

- 7.64 MB
- 2022-04-22 11:51:34 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
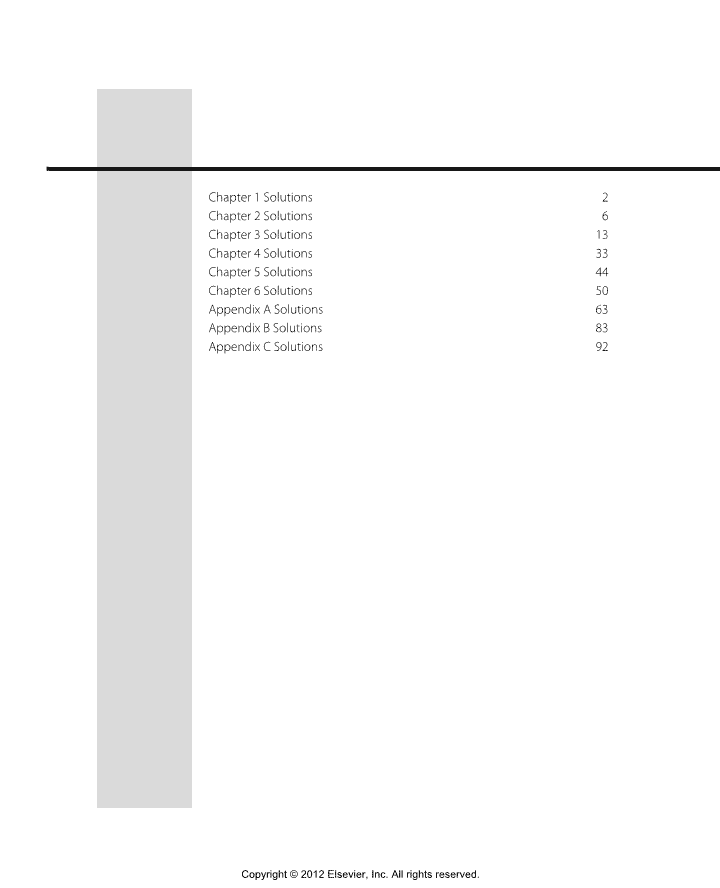
'Chapter1Solutions2Chapter2Solutions6Chapter3Solutions13Chapter4Solutions33Chapter5Solutions44Chapter6Solutions50AppendixASolutions63AppendixBSolutions83AppendixCSolutions92Copyright©2012Elsevier,Inc.Allrightsreserved.
SolutionstoCaseStudiesandExercises1Copyright©2012Elsevier,Inc.Allrightsreserved.
2■SolutionstoCaseStudiesandExercisesChapter1SolutionsCaseStudy1:ChipFabricationCost10.30×3.89–41.1a.Yield==⎛⎞1+---------------------------0.36⎝⎠4.0b.Itisfabricatedinalargertechnology,whichisanolderplant.Asplantsage,theirprocessgetstuned,andthedefectratedecreases.2π×()302π×301.2a.Diesperwafer=-----------------------------–-------------------------------=471–54.4=4161.5sqrt2()×1.50.30×1.5–4Yield==⎛⎞1+------------------------0.65⎝⎠4.0Profit=416×0.65×$20=$54082π×()302π×30b.Diesperwafer=-----------------------------–-------------------------------=283–42.1=2402.5sqrt2()×2.50.30×2.5–4Yield==⎛⎞1+--------------------------0.50⎝⎠4.0Profit=240×0.50×$25=$3000c.TheWoodschipd.Woodschips:50,000/416=120.2wafersneededMarkonchips:25,000/240=104.2wafersneededTherefore,themostlucrativesplitis120Woodswafers,30Markonwafers.0.75×1.992–41.3a.Defect–Freesinglecore==⎛⎞1+----------------------------------0.28⎝⎠4.0Nodefects=0.282=0.08Onedefect=0.28×0.72×2=0.40Nomorethanonedefect=0.08+0.40=0.48Wafersizeb.$20=------------------------------------olddpw×0.28$20×0.28=Wafersize/olddpwWafersize$20×0.28x==---------------------------------------------------------------------------=$23.331/2×olddpw×0.481/2×0.48Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter1Solutions■3CaseStudy2:PowerConsumptioninComputerSystems1.4a..80x=66+2×2.3+7.9;x=99b..6×4W+.4×7.9=5.56c.Solvethefollowingfourequations:seek7200=.75×seek5400seek7200+idle7200=100seek5400+idle5400=100seek7200×7.9+idle7200×4=seek5400×7+idle5400×2.9idle7200=29.8%14KW1.5a.------------------------------------------------------------1=83()66W2++.3W7.9W14KWb.---------------------------------------------------------------------=166()66W+2.3W+2×7.9Wc.200W×11=2200W2200/(76.2)=28racksOnly1coolingdoorisrequired.1.6a.TheIBMx346couldtakelessspace,whichwouldsavemoneyinrealestate.Theracksmightbebetterlaidout.Itcouldalsobemuchcheaper.Inaddition,ifwewererunningapplicationsthatdidnotmatchthecharacteristicsofthesebenchmarks,theIBMx346mightbefaster.Finally,therearenoreliabilitynumbersshown.AlthoughwedonotknowthattheIBMx346isbetterinanyoftheseareas,wedonotknowitisworse,either.1.7a.(1–8)+.8/2=.2+.4=.62Powernew()V×0.60×()F×0.603b.--------------------------==-----------------------------------------------------------0.6=0.216Powerold2V×F.75c.1=--------------------------------;x=50%()1–x+x22Powernew()V×0.75×()F×0.602d.--------------------------==-----------------------------------------------------------0.75×0.6=0.338PoweroldV2×FExercises1.8a.(1.35)10=approximately20b.3200×(1.4)12=approximately181,420c.3200×(1.01)12=approximately3605d.Powerdensity,whichisthepowerconsumedovertheincreasinglysmallarea,hascreatedtoomuchheatforheatsinkstodissipate.Thishaslimitedtheactivityofthetransistorsonthechip.Insteadofincreasingtheclockrate,manufacturersareplacingmultiplecoresonthechip.Copyright©2012Elsevier,Inc.Allrightsreserved.
4■SolutionstoCaseStudiesandExercisese.Anythinginthe15–25%rangewouldbeareasonableconclusionbasedonthedeclineintherateoverhistory.Asthesuddenstopinclockrateshows,though,eventhedeclinesdonotalwaysfollowpredictions.1.9a.50%b.Energy=½load×V2.Changingthefrequencydoesnotaffectenergy–onlypower.Sothenewenergyis½load×(½V)2,reducingittoabout¼theoldenergy.1.10a.60%b.0.4+0.6×0.2=0.58,whichreducestheenergyto58%oftheoriginalenergy.2×(Frequency×.6)/c.newPower/oldPower=½Capacitance×(Voltage×.8)½Capacitance×Voltage×Frequency=0.82×0.6=0.256oftheoriginalpower.d.0.4+0.3×2=0.46,whichreducetheenergyto46%oftheoriginalenergy.1.11a.109/100=107b.107/107+24=1c.[needsolution]1.12a.35/10000×3333=11.67daysb.Thereareseveralcorrectanswers.Onewouldbethat,withthecurrentsys-tem,onecomputerfailsapproximatelyevery5minutes.5minutesisunlikelytobeenoughtimetoisolatethecomputer,swapitout,andgetthecomputerbackonlineagain.10minutes,however,ismuchmorelikely.Inanycase,itwouldgreatlyextendtheamountoftimebefore1/3ofthecomputershavefailedatonce.Becausethecostofdowntimeissohuge,beingabletoextendthisisveryvaluable.c.$90,000=(x+x+x+2x)/4$360,000=5x$72,000=x4thquarter=$144,000/hr1.13a.Itanium,becauseithasaloweroverallexecutiontime.b.Opteron:0.6×0.92+0.2×1.03+0.2×0.65=0.888c.1/0.888=1.1261.14a.SeeFigureS.1.b.2=1/((1–x)+x/10)5/9=x=0.56or56%c.0.056/0.5=0.11or11%d.Maximumspeedup=1/(1/10)=105=1/((1–x)+x/10)8/9=x=0.89or89%Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter1Solutions■5121086Netspeedup4200102030405060708090100PercentvectorizationFigureS.1Plotoftheequation:y=100/((100–x)+x/10).e.Currentspeedup:1/(0.3+0.7/10)=1/0.37=2.7Speedupgoal:5.4=1/((1–x)+x/10)=x=0.91Thismeansthepercentageofvectorizationwouldneedtobe91%1.15a.oldexecutiontime=0.5new+0.5×10new=5.5newb.Intheoriginalcode,theunenhancedpartisequalintimetotheenhancedpartspedupby10,therefore:(1–x)=x/1010–10x=x10=11x10/11=x=0.911.16a.1/(0.8+0.20/2)=1.11b.1/(0.7+0.20/2+0.10×3/2)=1.05c.fpops:0.1/0.95=10.5%,cache:0.15/0.95=15.8%1.17a.1/(0.6+0.4/2)=1.25b.1/(0.01+0.99/2)=1.98c.1/(0.2+0.8×0.6+0.8×0.4/2)=1/(.2+.48+.16)=1.19d.1/(0.8+0.2×.01+0.2×0.99/2)=1/(0.8+0.002+0.099)=1.111.18a.1/(.2+.8/N)b.1/(.2+8×0.005+0.8/8)=2.94c.1/(.2+3×0.005+0.8/8)=3.17d.1/(.2+logN×0.005+0.8/N)e.d/dN(1/((1–P)+logN×0.005+P/N))=0Copyright©2012Elsevier,Inc.Allrightsreserved.
6■SolutionstoCaseStudiesandExercisesChapter2SolutionsCaseStudy1:OptimizingCachePerformanceviaAdvancedTechniques2.1a.Eachelementis8B.Sincea64Bcachelinehas8elements,andeachcolumnaccesswillresultinfetchinganewlineforthenon-idealmatrix,weneedaminimumof8x8(64elements)foreachmatrix.Hence,theminimumcachesizeis128×8B=1KB.b.Theblockedversiononlyhastofetcheachinputandoutputelementonce.Theunblockedversionwillhaveonecachemissforevery64B/8B=8rowelements.Eachcolumnrequires64Bx256ofstorage,or16KB.Thus,columnelementswillbereplacedinthecachebeforetheycanbeusedagain.Hencetheunblockedversionwillhave9misses(1rowand8columns)forevery2intheblockedversion.c.for(i=0;i<256;i=i+B){for(j=0;j<256;j=j+B){for(m=0;m2.396×.5=1.2ns2-way–(1–.012)×3+.012×(20)=3.2cycles=>3.2×.5=1.6ns4-way–(1–.0033)×2+.0033×(13)=2.036cycles=>2.06×.83=1.69ns8-way–(1–.0009)×3+.0009×13=3cycles=>3×.79=2.37nsDirectmappedcacheisthebest.2.9a.Theaveragememoryaccesstimeofthecurrent(4-way64KB)cacheis1.69ns.64KBdirectmappedcacheaccesstime=.86ns@.5nscycletime=2cyclesWay-predictedcachehascycletimeandaccesstimesimilartodirectmappedcacheandmissratesimilarto4-waycache.TheAMAToftheway-predictedcachehasthreecomponents:miss,hitwithwaypredictioncorrect,andhitwithwaypredictionmispredict:0.0033×(20)+(0.80×2+(1–0.80)×3)×(1–0.0033)=2.26cycles=1.13nsb.Thecycletimeofthe64KB4-waycacheis0.83ns,whilethe64KBdirect-mappedcachecanbeaccessedin0.5ns.Thisprovides0.83/0.5=1.66or66%fastercacheaccess.c.With1cyclewaymispredictionpenalty,AMATis1.13ns(asperparta),butwitha15cyclemispredictionpenalty,theAMATbecomes:0.0033×20+(0.80×2+(1–0.80)×15)×(1–0.0033)=4.65cyclesor2.3ns.d.Theserialaccessis2.4ns/1.59ns=1.509or51%slower.2.10a.Theaccesstimeis1.12ns,whilethecycletimeis0.51ns,whichcouldbepotentiallypipelinedasfinelyas1.12/.51=2.2pipestages.b.Thepipelineddesign(notincludinglatchareaandpower)hasanareaof1.19mm2andenergyperaccessof0.16nJ.Thebankedcachehasanareaof1.36mm2andenergyperaccessof0.13nJ.Thebankeddesignusesslightlymoreareabecauseithasmoresenseampsandothercircuitrytosupportthetwobanks,whilethepipelineddesignburnsslightlymorepowerbecausethememoryarraysthatareactivearelargerthaninthebankedcase.2.11a.Withcriticalwordfirst,themissservicewouldrequire120cycles.Withoutcriticalwordfirst,itwouldrequire120cyclesforthefirst16Band16cyclesforeachofthenext316Bblocks,or120+(3×16)=168cycles.b.ItdependsonthecontributiontoAverageMemoryAccessTime(AMAT)ofthelevel-1andlevel-2cachemissesandthepercentreductioninmissservicetimesprovidedbycriticalwordfirstandearlyrestart.Ifthepercentagereduc-tioninmissservicetimesprovidedbycriticalwordfirstandearlyrestartisroughlythesameforbothlevel-1andlevel-2missservice,theniflevel-1missescontributemoretoAMAT,criticalwordfirstwouldlikelybemoreimportantforlevel-1misses.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter2Solutions■92.12a.16B,tomatchthelevel2datacachewritepath.b.Assumemergingwritebufferentriesare16Bwide.Sinceeachstorecanwrite8B,amergingwritebufferentrywouldfillupin2cycles.Thelevel-2cachewilltake4cyclestowriteeachentry.Anon-mergingwritebufferwouldtake4cyclestowritethe8Bresultofeachstore.Thismeansthemergingwritebufferwouldbe2timesfaster.c.Withblockingcaches,thepresenceofmisseseffectivelyfreezesprogressmadebythemachine,sowhethertherearemissesornotdoesn’tchangetherequirednumberofwritebufferentries.Withnon-blockingcaches,writescanbeprocessedfromthewritebufferduringmisses,whichmaymeanfewerentriesareneeded.2.13a.A2GBDRAMwithparityorECCeffectivelyhas9bitbytes,andwouldrequire181GbDRAMs.Tocreate72outputbits,eachonewouldhavetooutput72/18=4bits.b.Aburstlengthof4readsout32B.c.TheDDR-667DIMMbandwidthis667×8=5336MB/s.TheDDR-533DIMMbandwidthis533×8=4264MB/s.2.14a.Thisissimilartothescenariogiveninthefigure,buttRCDandCLareboth5.Inaddition,wearefetchingtwotimesthedatainthefigure.Thusitrequires5+5+4×2=18cyclesofa333MHzclock,or18×(1/333MHz)=54.0ns.b.Thereadtoanopenbankrequires5+4=9cyclesofa333MHzclock,or27.0ns.Inthecaseofabankactivate,thisis14cycles,or42.0ns.Including20nsformissprocessingonchip,thismakesthetwo42+20=61nsand27.0+20=47ns.Includingtimeonchip,thebankactivatetakes61/47=1.30or30%longer.2.15Thecostsofthetwosystemsare$2×130+$800=$1060withtheDDR2-667DIMMand2×$100+$800=$1000withtheDDR2-533DIMM.Thelatencytoservicealevel-2missis14×(1/333MHz)=42ns80%ofthetimeand9×(1/333MHz)=27ns20%ofthetimewiththeDDR2-667DIMM.Itis12×(1/266MHz)=45ns(80%ofthetime)and8×(1/266MHz)=30ns(20%ofthetime)withtheDDR-533DIMM.TheCPIaddedbythelevel-2missesinthecaseofDDR2-667is0.00333×42×.8+0.00333×27×.2=0.130givingatotalof1.5+0.130=1.63.MeanwhiletheCPIaddedbythelevel-2missesforDDR-533is0.00333×45×.8+0.00333×30×.2=0.140givingatotalof1.5+0.140=1.64.Thusthedropisonly1.64/1.63=1.006,or0.6%,whilethecostis$1060/$1000=1.06or6.0%greater.Thecost/performanceoftheDDR2-667systemis1.63×1060=1728whilethecost/performanceoftheDDR2-533systemis1.64×1000=1640,sotheDDR2-533systemisabettervalue.2.16Thecoreswillbeexecuting8cores×3GHz/2.0CPI=12billioninstructionspersecond.Thiswillgenerate12×0.00667=80millionlevel-2missespersecond.Withtheburstlengthof8,thiswouldbe80×32B=2560MB/sec.IfthememoryCopyright©2012Elsevier,Inc.Allrightsreserved.
10■SolutionstoCaseStudiesandExercisesbandwidthissometimes2Xthis,itwouldbe5120MB/sec.FromFigure2.14,thisisjustbarelywithinthebandwidthprovidedbyDDR2-667DIMMs,sojustonememorychannelwouldsuffice.2.17a.Thesystembuiltfrom1GbDRAMswillhavetwiceasmanybanksasthesystembuiltfrom2GbDRAMs.Thusthe1Gb-basedsystemshouldprovidehigherperformancesinceitcanhavemorebankssimultaneouslyopen.b.Thepowerrequiredtodrivetheoutputlinesisthesameinbothcases,butthesystembuiltwiththex4DRAMswouldrequireactivatingbankson18DRAMs,versusonly9DRAMsforthex8parts.Thepagesizeactivatedoneachx4andx8partarethesame,andtakeroughlythesameactivationenergy.ThussincetherearefewerDRAMsbeingactivatedinthex8designoption,itwouldhavelowerpower.2.18a.Withpolicy1,PrechargedelayTrp=5×(1/333MHz)=15nsActivationdelayTrcd=5×(1/333MHz)=15nsColumnselectdelayTcas=4×(1/333MHz)=12nsAccesstimewhenthereisarowbufferhitrTcas()+TddrT=--------------------------------------h100Accesstimewhenthereisamiss()100–r()TrpT+++rcdTcasTddrT=---------------------------------------------------------------------------------------------m100Withpolicy2,Accesstime=Trcd+Tcas+TddrIfAisthetotalnumberofaccesses,thetip-offpointwilloccurwhenthenetaccesstimewithpolicy1isequaltothetotalaccesstimewithpolicy2.i.e.,r100–r---------Tcas()+TddrA+-----------------Trp()+++TrcdTcasTddrA100100=(Trcd+Tcas+Tddr)A100×Trp⇒r=----------------------------Trp+Trcdr=100×(15)/(15+15)=50%Ifrislessthan50%,thenwehavetoproactivelycloseapagetogetthebestperformance,elsewecankeepthepageopen.b.ThekeybenefitofclosingapageistohidetheprechargedelayTrpfromthecriticalpath.Iftheaccessesarebacktoback,thenthisisnotpossible.Thisnewconstrainwillnotimpactpolicy1.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter2Solutions■11Thenewequationsforpolicy2,Accesstimewhenwecanhideprechargedelay=Trcd+Tcas+TddrAccesstimewhenprechargedelayisinthecriticalpath=Trcd+Tcas+Trp+TddrEquation1willnowbecome,r100–r---------()Tcas+TddrA+-----------------()TrpT+++rcdTcasTddrA100100=0.9×()Trcd++TcasTddrA+0.1×()Trcd+++TcasTrpTddr⎛⎞Trp⇒r=90×----------------------------⎝⎠Trp+Trcdr=90×15/30=45%c.Foranyrowbufferhitrate,policy2requiresadditionalr×(2+4)nJperaccess.Ifr=50%,thenpolicy2requires3nJofadditionalenergy.2.19HibernatingwillbeusefulwhenthestaticenergysavedinDRAMisatleastequaltotheenergyrequiredtocopyfromDRAMtoFlashandthenbacktoDRAM.DRAMdynamicenergytoread/writeisnegligiblecomparedtoFlashandcanbeignored.9–681×0×22×.561×0Time=-------------------------------------------------------------64×1.6=400secondsThefactor2intheaboveequationisbecausetohibernateandwakeup,bothFlashandDRAMhavetobereadandwrittenonce.2.20a.Yes.TheapplicationandproductionenvironmentcanberunonaVMhostedonadevelopmentmachine.b.Yes.ApplicationscanberedeployedonthesameenvironmentontopofVMsrunningondifferenthardware.Thisiscommonlycalledbusinesscontinuity.c.No.Dependingonsupportinthearchitecture,virtualizingI/Omayaddsig-nificantorverysignificantperformanceoverheads.d.Yes.Applicationsrunningondifferentvirtualmachinesareisolatedfromeachother.e.Yes.See“Devirtualizablevirtualmachinesenablinggeneral,single-node,onlinemaintenance,”DavidLowell,YasushiSaito,andEileenSamberg,intheProceedingsofthe11thASPLOS,2004,pages211–223.2.21a.ProgramsthatdoalotofcomputationbuthavesmallmemoryworkingsetsanddolittleI/Oorothersystemcalls.b.Theslowdownabovewas60%for10%,so20%systemtimewouldrun120%slower.c.Themedianslowdownusingpurevirtualizationis10.3,whileforparavirtu-alizationthemedianslowdownis3.76.Copyright©2012Elsevier,Inc.Allrightsreserved.
12■SolutionstoCaseStudiesandExercisesd.ThenullcallandnullI/Ocallhavethelargestslowdown.Thesehavenorealworktooutweighthevirtualizationoverheadofchangingprotectionlevels,sotheyhavethelargestslowdowns.2.22Thevirtualmachinerunningontopofanothervirtualmachinewouldhavetoemu-lateprivilegelevelsasifitwasrunningonahostwithoutVT-xtechnology.2.23a.AsofthedateoftheComputerpaper,AMD-Vaddsmoresupportforvirtual-izingvirtualmemory,soitcouldprovidehigherperformanceformemory-intensiveapplicationswithlargememoryfootprints.b.Bothprovidesupportforinterruptvirtualization,butAMD’sIOMMUalsoaddscapabilitiesthatallowsecurevirtualmachineguestoperatingsystemaccesstoselecteddevices.2.24Openhands-onexercise,nofixedsolution.2.25a.Theseresultsarefromexperimentsona3.3GHzIntel®Xeon®ProcessorX5680withNehalemarchitecture(westmereat32nm).Thenumberofmissesper1KinstructionsofL1Dcacheincreasessignificantlybymorethan300Xwheninputdatasizegoesfrom8KBto64KB,andkeepsrelativelyconstantaround300/1Kinstructionsforallthelargerdatasets.SimilarbehaviorwithdifferentflatteningpointsonL2andL3cachesareobserved.b.TheIPCdecreasesby60%,20%,and66%wheninputdatasizegoesfrom8KBto128KB,from128KBto4MB,andfrom4MBto32MB,respectively.Thisshowstheimportanceofallcaches.Amongallthreelevels,L1andL3cachesaremoreimportant.ThisisbecausetheL2cacheintheIntel®Xeon®ProcessorX5680isrelativelysmallandslow,withcapacitybeing256KBandlatencybeingaround11cycles.c.ForarecentInteli7processor(3.3GHzIntel®Xeon®ProcessorX5680),whenthedatasetsizeisincreasedfrom8KBto128KB,thenumberofL1Dcachemissesper1Kinstructionsincreasesbyaround300,andthenumberofL2cachemissesper1Kinstructionsremainsnegligible.Witha11cyclemisspenalty,thismeansthatwithoutprefetchingorlatencytolerancefromout-of-orderissuewewouldexpecttheretobeanextra3300cyclesper1KinstructionsduetoL1misses,whichmeansanincreaseof3.3cyclesperinstructiononaverage.ThemeasuredCPIwiththe8KBinputdatasizeis1.37.WithoutanylatencytolerancemechanismswewouldexpecttheCPIofthe128KBcasetobe1.37+3.3=4.67.However,themeasuredCPIofthe128KBcaseis3.44.ThismeansthatmemorylatencyhidingtechniquessuchasOOOexecution,prefetching,andnon-blockingcachesimprovetheperfor-mancebymorethan26%.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■13Chapter3SolutionsCaseStudy1:ExploringtheImpactofMicroarchitecturalTechniques23.1Thebaselineperformance(incycles,perloopiteration)ofthecodesequenceinFigure3.48,ifnonewinstruction’sexecutioncouldbeinitiateduntiltheprevi-ousinstruction’sexecutionhadcompleted,is40.SeeFigureS.2.Eachinstruc-tionrequiresoneclockcycleofexecution(aclockcycleinwhichthatinstruction,andonlythatinstruction,isoccupyingtheexecutionunits;sinceeveryinstructionmustexecute,theloopwilltakeatleastthatmanyclockcycles).Tothatbasenumber,weaddtheextralatencycycles.Don’tforgetthebranchshadowcycle.Loop:LDF2,0(Rx)1+4DIVDF8,F2,F01+12MULTDF2,F6,F21+5LDF4,0(Ry)1+4ADDDF4,F0,F41+1ADDDF10,F8,F21+1ADDIRx,Rx,#81ADDIRy,Ry,#81SDF4,0(Ry)1+1SUBR20,R4,Rx1BNZR20,Loop1+1____cyclesperloopiter40FigureS.2Baselineperformance(incycles,perloopiteration)ofthecodesequenceinFigure3.48.3.2HowmanycycleswouldtheloopbodyinthecodesequenceinFigure3.48requireifthepipelinedetectedtruedatadependenciesandonlystalledonthose,ratherthanblindlystallingeverythingjustbecauseonefunctionalunitisbusy?Theansweris25,asshowninFigureS.3.Remember,thepointoftheextralatencycyclesistoallowaninstructiontocompletewhateveractionsitneeds,inordertoproduceitscorrectoutput.Untilthatoutputisready,nodependentinstructionscanbeexecuted.SothefirstLDmuststallthenextinstructionforthreeclockcycles.TheMULTDproducesaresultforitssuccessor,andthereforemuststall4moreclocks,andsoon.Copyright©2012Elsevier,Inc.Allrightsreserved.
14■SolutionstoCaseStudiesandExercisesLoop:LDF2,0(Rx)1+4DIVDF8,F2,F01+12MULTDF2,F6,F21+5LDF4,0(Ry)1+4ADDDF4,F0,F41+1ADDDF10,F8,F21+1ADDIRx,Rx,#81ADDIRy,Ry,#81SDF4,0(Ry)1+1SUBR20,R4,Rx1BNZR20,Loop1+1------cyclesperloopiter25FigureS.3NumberofcyclesrequiredbytheloopbodyinthecodesequenceinFigure3.48.3.3Consideramultiple-issuedesign.Supposeyouhavetwoexecutionpipelines,eachcapableofbeginningexecutionofoneinstructionpercycle,andenoughfetch/decodebandwidthinthefrontendsothatitwillnotstallyourexecution.Assumeresultscanbeimmediatelyforwardedfromoneexecutionunittoanother,ortoitself.Furtherassumethattheonlyreasonanexecutionpipelinewouldstallistoobserveatruedatadependency.Nowhowmanycyclesdoesthelooprequire?Theansweris22,asshowninFigureS.4.TheLDgoesfirst,asbefore,andtheDIVDmustwaitforitthrough4extralatencycycles.AftertheDIVDcomestheMULTD,whichcanruninthesecondpipealongwiththeDIVD,sincethere’snodependencybetweenthem.(Notethattheybothneedthesameinput,F2,andtheymustbothwaitonF2’sreadi-ness,butthereisnoconstraintbetweenthem.)TheLDfollowingtheMULTDdoesnotdependontheDIVDnortheMULTD,sohadthisbeenasuperscalar-order-3machine,Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■15Executionpipe0Executionpipe1Loop:LDF2,0(Rx);;;;;DIVDF8,F2,F0;MULTDF2,F6,F2LDF4,0(Ry);;;;;ADDF4,F0,F4;;;;;;;ADDDF10,F8,F2;ADDIRx,Rx,#8ADDIRy,Ry,#8;SDF4,0(Ry)SUBR20,R4,Rx;BNZR20,Loop;cyclesperloopiter22FigureS.4Numberofcyclesrequiredperloop.thatLDcouldconceivablyhavebeenexecutedconcurrentlywiththeDIVDandtheMULTD.Sincethisproblempositedatwo-execution-pipemachine,theLDexecutesinthecyclefollowingtheDIVD/MULTD.Theloopoverheadinstructionsattheloop’sbottomalsoexhibitsomepotentialforconcurrencybecausetheydonotdependonanylong-latencyinstructions.3.4Possibleanswers:1.IfaninterruptoccursbetweenNandN+1,thenN+1mustnothavebeenallowedtowriteitsresultstoanypermanentarchitecturalstate.Alternatively,itmightbepermissibletodelaytheinterruptuntilN+1completes.2.IfNandN+1happentotargetthesameregisterorarchitecturalstate(say,memory),thenallowingNtooverwritewhatN+1wrotewouldbewrong.3.Nmightbealongfloating-pointopthateventuallytraps.N+1cannotbeallowedtochangearchstateincaseNistoberetried.Copyright©2012Elsevier,Inc.Allrightsreserved.
16■SolutionstoCaseStudiesandExercisesLong-latencyopsareathighestriskofbeingpassedbyasubsequentop.TheDIVDinstrwillcompletelongaftertheLDF4,0(Ry),forexample.3.5FigureS.5demonstratesonepossiblewaytoreordertheinstructionstoimprovetheperformanceofthecodeinFigure3.48.Thenumberofcyclesthatthisreorderedcodetakesis20.Executionpipe0Executionpipe1Loop:LDF2,0(Rx);LDF4,0(Ry);;;;DIVDF8,F2,F0;ADDDF4,F0,F4MULTDF2,F6,F2;;SDF4,0(Ry);#ops:11;#nops:(20×2)–11=29;ADDIRx,Rx,#8;ADDIRy,Ry,#8;;;;;;SUBR20,R4,RxADDDF10,F8,F2;BNZR20,Loop;cyclesperloopiter20FigureS.5Numberofcyclestakenbyreorderedcode.3.6a.Fractionofallcycles,countingbothpipes,wastedinthereorderedcodeshowninFigureS.5:11opsoutof2x20opportunities.1–11/40=1–0.275=0.725b.Resultsofhand-unrollingtwoiterationsoftheloopfromcodeshowninFigureS.6:exectimew/oenhancementc.Speedup=--------------------------------------------------------------------exectimewithenhancementSpeedup=20/(22/2)Speedup=1.82Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■17Executionpipe0Executionpipe1Loop:LDF2,0(Rx);LDF4,0(Ry)LDF2,0(Rx);LDF4,0(Ry);;;DIVDF8,F2,F0;ADDDF4,F0,F4DIVDF8,F2,F0;ADDDF4,F0,F4MULTDF2,F0,F2;SDF4,0(Ry)MULTDF2,F6,F2;SDF4,0(Ry);;ADDIRx,Rx,#16;ADDIRy,Ry,#16;;;;;;;ADDDF10,F8,F2;SUBR20,R4,RxADDDF10,F8,F2;BNZR20,Loop;cyclesperloopiter22FigureS.6Hand-unrollingtwoiterationsoftheloopfromcodeshowninFigureS.5.3.7ConsiderthecodesequenceinFigure3.49.Everytimeyouseeadestinationregis-terinthecode,substitutethenextavailableT,beginningwithT9.Thenupdateallthesrc(source)registersaccordingly,sothattruedatadependenciesaremain-tained.Showtheresultingcode.(Hint:SeeFigure3.50.)Loop:LDT9,0(Rx)IO:MULTDT10,F0,T2I1:DIVDT11,T9,T10I2:LDT12,0(Ry)I3:ADDDT13,F0,T12I4:SUBDT14,T11,T13I5:SDT14,0(Ry)FigureS.7Registerrenaming.Copyright©2012Elsevier,Inc.Allrightsreserved.
18■SolutionstoCaseStudiesandExercises3.8SeeFigureS.8.TherenametablehasarbitraryvaluesatclockcycleN–1.Lookatthenexttwoinstructions(I0andI1):I0targetstheF1register,andI1willwritetheF4register.ThismeansthatinclockcycleN,therenametablewillhavehaditsentries1and4overwrittenwiththenextavailableTempregisterdesignators.I0getsrenamedfirst,soitgetsthefirstTreg(9).I1thengetsrenamedtoT10.InclockcycleN,instructionsI2andI3comealong;I2willoverwriteF6,andI3willwriteF0.Thismeanstherenametable’sentry6gets11(thenextavailableTreg),andrenametableentry0iswrittentotheTregafterthat(12).Inprinciple,youdon’thavetoallocateTregssequentially,butit’smucheasierinhardwareifyoudo.I0:SUBDF1,F2,F3RenamedincycleNI1:ADDDF4,F1,F2I2:MULTDF6,F4,F1RenamedincycleN+1I3:DIVDF0,F2,F6ClockcycleN–1NN+1000001211191122222233333344410445555556666611777777888888Renametable99999962626262626263636363636312111091413121116151413NextavailTregFigureS.8Cycle-by-cyclestateoftherenametableforeveryinstructionofthecodeinFigure3.51.3.9SeeFigureS.9.ADDR1,R1,R1;5+5−>10ADDR1,R1,R1;10+10−>20ADDR1,R1,R1;20+20−>40FigureS.9ValueofR1whenthesequencehasbeenexecuted.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■193.10Anexampleofaneventthat,inthepresenceofself-drainingpipelines,coulddis-ruptthepipeliningandyieldwrongresultsisshowninFigureS.10.alu0alu1ld/stld/stbrClock1ADDIR11,R3,#2LWR4,0(R0)cycle2ADDIR2,R2,#16ADDIR20,R0,#2LWR4,0(R0)LWR5,8(R1)3LWR5,8(R1)4ADDIR10,R4,#15ADDIR10,R4,#1SWR7,0(R6)SWR9,8(R8)6SUBR4,R3,R2SWR7,0(R6)SWR9,8(R8)7BNZR4,LoopFigureS.10Exampleofaneventthatyieldswrongresults.Whatcouldgowrongwiththis?Ifaninterruptistakenbetweenclockcycles1and4,thentheresultsoftheLWatcycle2willendupinR1,insteadoftheLWatcycle1.BankstallsandECCstallswillcausethesameeffect—pipeswilldrain,andthelastwriterwins,aclassicWAWhazard.Allother“intermediate”resultsarelost.3.11SeeFigureS.11.Theconventionisthataninstructiondoesnotentertheexecutionphaseuntilallofitsoperandsareready.Sothefirstinstruction,LWR3,0(R0),marchesthroughitsfirstthreestages(F,D,E)butthatMstagethatcomesnextrequirestheusualcycleplustwomoreforlatency.UntilthedatafromaLDisavail-ableattheexecutionunit,anysubsequentinstructions(especiallythatADDIR1,R1,#1,whichdependsonthe2ndLW)cannotentertheEstage,andmustthereforestallattheDstage.LooplengthLoop:12345678910111213141516171819LWR3,0(R0)FDEM––WLWR1,0(R3)FD–––EM––WADDIR1,R1,#1F–––D–––EMWSUBR4,R3,R2F–––DEMWSWR1,0(R3)FDEM––WBNZR4,LoopFDE––MWLWR3,0(R0)FD...(2.11a)4cycleslosttobranchoverhead(2.11b)2cycleslostwithstaticpredictor(2.11c)NocycleslostwithcorrectdynamicpredictionFigureS.11Phasesofeachinstructionperclockcycleforoneiterationoftheloop.Copyright©2012Elsevier,Inc.Allrightsreserved.
20■SolutionstoCaseStudiesandExercisesa.4cycleslosttobranchoverhead.Withoutbypassing,theresultsoftheSUBinstructionarenotavailableuntiltheSUB’sWstage.Thattacksonanextra4clockcyclesattheendoftheloop,becausethenextloop’sLWR1can’tbeginuntilthebranchhascompleted.b.2cycleslostw/staticpredictor.Astaticbranchpredictormayhaveaheuristiclike“ifbranchtargetisanegativeoffset,assumeit’saloopedge,andloopsareusuallytakenbranches.”Butwestillhadtofetchanddecodethebranchtoseethat,sowestilllose2clockcycleshere.c.Nocycleslostw/correctdynamicprediction.Adynamicbranchpredictorremembersthatwhenthebranchinstructionwasfetchedinthepast,iteventu-allyturnedouttobeabranch,andthisbranchwastaken.Soa“predictedtaken”willoccurinthesamecycleasthebranchisfetched,andthenextfetchafterthatwillbetothepresumedtarget.Ifcorrect,we’vesavedallofthelatencycyclesseenin3.11(a)and3.11(b).Ifnot,wehavesomecleaninguptodo.3.12a.SeeFigureS.12.LDF2,0(Rx)DIVDF8,F2,F0MULTDF2,F8,F2;regrenamingdoesn’treallyhelphere,dueto;truedatadependenciesonF8andF2LDF4,0(Ry);thisLDisindependentoftheprevious3;instrsandcanbeperformedearlierthan;pgmorder.ItfeedsthenextADDD,andADDD;feedstheSDbelow.Butthere’satruedata;dependencychainthroughall,sonobenefitADDDF4,F0,F4ADDDF10,F8,F2;ThisADDDstillhastowaitforDIVDlatency,;nomatterwhatyoucalltheirrendezvousregADDIRx,Rx,#8;renamefornextloopiterationADDIRy,Ry,#8;renamefornextloopiterationSDF4,0(Ry);ThisSDcanstartwhentheADDD’slatencyhas;transpired.Withregrenaming,doesn’thave;towaituntiltheLDof(adifferent)F4has;completed.SUBR20,R4,RxBNZR20,LoopFigureS.12Instructionsincodewhereregisterrenamingimprovesperformance.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■21b.SeeFigureS.13.Thenumberofclockcyclestakenbythecodesequenceis25.CycleopwasdispatchedtoFUalu0alu1ld/stClockcycle1ADDIRx,Rx,#8ADDIRy,Ry,#8LDF2,0(Rx)2SUBR20,R4,RxLDF4,0(Ry)Note:theseADDI’sare3LDlatencygeneratingRx,yfornextloopiteration,notthisone.456DIVDF8,F2,F07DIVDlatencyADDDF4,F0,F4ADDDlatency8...SDF4,0(Ry)1819MULTDF2,F8,F220MULTDlatency21222324BNZR20,Loop25BranchshadowADDDF10,F8,F2FigureS.13Numberofclockcyclestakenbythecodesequence.c.SeeFiguresS.14andS.15.TheboldinstructionsarethoseinstructionsthatarepresentintheRS,andreadyfordispatch.ThinkofthisexercisefromtheReservationStation’spointofview:atanygivenclockcycle,itcanonly“see”theinstructionsthatwerepreviouslywrittenintoit,thathavenotalreadydispatched.Fromthatpool,theRS’sjobistoidentifyanddispatchthetwoeligibleinstructionsthatwillmostboostmachineperformance.0123456LDF2,0(Rx)LDF2,0(Rx)LDF2,0(Rx)LDF2,0(Rx)LDF2,0(Rx)LDF2,0(Rx)DIVDF8,F2,F0DIVDF8,F2,F0DIVDF8,F2,F0DIVDF8,F2,F0DIVDF8,F2,F0DIVDF8,F2,F0MULTDF2,F8,F2MULTDF2,F8,F2MULTDF2,F8,F2MULTDF2,F8,F2MULTDF2,F8,F2MULTDF2,F8,F2LDF4,0(Ry)LDF4,0(Ry)LDF4,0(Ry)LDF4,0(Ry)LDF4,0(Ry)LDF4,0(Ry)ADDDF4,F0,F4ADDDF4,F0,F4ADDDF4,F0,F4ADDDF4,F0,F4ADDDF4,F0,F4ADDDF4,F0,F4ADDDF10,F8,F2ADDDF10,F8,F2ADDDF10,F8,F2ADDDF10,F8,F2ADDDF10,F8,F2ADDDF10,F8,F2ADDIRx,Rx,#8ADDIRx,Rx,#8ADDIRx,Rx,#8ADDIRx,Rx,#8ADDIRx,Rx,#8ADDIRx,Rx,#8ADDIRy,Ry,#8ADDIRy,Ry,#8ADDIRy,Ry,#8ADDIRy,Ry,#8ADDIRy,Ry,#8ADDIRy,Ry,#8SDF4,0(Ry)SDF4,0(Ry)SDF4,0(Ry)SDF4,0(Ry)SDF4,0(Ry)SDF4,0(Ry)SUBR20,R4,RxSUBR20,R4,RxSUBR20,R4,RxSUBR20,R4,RxSUBR20,R4,RxSUBR20,R4,RxBNZ20,LoopBNZ20,LoopBNZ20,LoopBNZ20,LoopBNZ20,LoopBNZ20,LoopFirst2instructionsappearinRSCandidatesfordispatchinboldFigureS.14Candidatesfordispatch.Copyright©2012Elsevier,Inc.Allrightsreserved.
22■SolutionstoCaseStudiesandExercisesalu0alu1ld/st1LDF2,0(Rx)2LDF4,0(Ry)34ADDIRx,Rx,#85ADDIRy,Ry,#86SUBR20,R4,RxDIVDF8,F2,F07ADDDF4,F0,F48Clockcycle9SDF4,0(Ry)...1819MULTDF2,F8,F22021222324BNZR20,Loop25ADDDF10,F8,F2Branchshadow25clockcyclestotalFigureS.15Numberofclockcyclesrequired.d.SeeFigureS.16.CycleopwasdispatchedtoFUalu0alu1ld/st1LDF2,0(Rx)Clockcycle2LDF4,0(Ry)34ADDIRx,Rx,#85ADDIRy,Ry,#86SUBR20,R4,RxDIVDF8,F2,F07ADDDF4,F0,F489SDF4,0(Ry)...1819MULTDF2,F8,F22021222324BNZR20,Loop25ADDDF10,F8,F2Branchshadow25clockcyclestotalFigureS.16Speedupis(executiontimewithoutenhancement)/(executiontimewithenhancement)=25/(25–6)=1.316.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■231.AnotherALU:0%improvement2.AnotherLD/STunit:0%improvement3.Fullbypassing:criticalpathisLD->Div->MULT->ADDD.Bypassingwouldsave1cyclefromlatencyofeach,so4cyclestotal4.Cuttinglongestlatencyinhalf:dividerislongestat12cycles.Thiswouldsave6cyclestotal.e.SeeFigureS.17.CycleopwasdispatchedtoFUalu0alu1ld/st1LDF2,0(Rx)Clockcycle2LDF2,0(Rx)3LDF4,0(Ry)4ADDIRx,Rx,#85ADDIRy,Ry,#86SUBR20,R4,RxDIVDF8,F2,F07DIVDF8,F2,F08ADDDF4,F0,F49...SDF4,0(Ry)1819MULTDF2,F8,F220MULTDF2,F8,F22122232425ADDDF10,F8,F2BNZR20,Loop26ADDDF10,F8,F2Branchshadow26clockcyclestotalFigureS.17Numberofclockcyclesrequiredtodotwoloops’worthofwork.CriticalpathisLD->DIVD->MULTD->ADDD.IfRSschedules2ndloop’scriticalLDincycle2,thenloop2’scriticaldependencychainwillbethesamelengthasloop1’sis.Sincewe’renotfunctional-unit-limitedforthiscode,onlyoneextraclockcycleisneeded.Copyright©2012Elsevier,Inc.Allrightsreserved.
24■SolutionstoCaseStudiesandExercisesExercises3.13a.SeeFigureS.18.ClockcycleUnscheduledcodeScheduledcode1DADDIUR4,R1,#800DADDIUR4,R1,#8002L.DF2,0(R1)L.DF2,0(R1)3stallL.DF6,0(R2)4MUL.DF4,F2,F0MUL.DF4,F2,F05L.DF6,0(R2)DADDIUR1,R1,#86stallDADDIUR2,R2,#8stallDSLTUR3,R1,R4stallstallstallstall7ADD.DF6,F4,F6ADD.DF6,F4,F68stallstall9stallstall10stallBNEZR3,foo11S.DF6,0(R2)S.DF6,-8(R2)12DADDIUR1,R1,#813DADDIUR2,R2,#814DSLTUR3,R1,R415stall16BNEZR3,foo17stallFigureS.18Theexecutiontimeperelementfortheunscheduledcodeis16clockcyclesandforthescheduledcodeis10clockcycles.Thisis60%faster,sotheclockmustbe60%fasterfortheunscheduledcodetomatchtheperformanceofthesched-uledcodeontheoriginalhardware.b.SeeFigureS.19.ClockcycleScheduledcode1DADDIUR4,R1,#8002L.DF2,0(R1)3L.DF6,0(R2)4MUL.DF4,F2,F0FigureS.19Thecodemustbeunrolledthreetimestoeliminatestallsafterscheduling.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■255L.DF2,8(R1)6L.DF10,8(R2)7MUL.DF8,F2,F08L.DF2,8(R1)9L.DF14,8(R2)10MUL.DF12,F2,F011ADD.DF6,F4,F612DADDIUR1,R1,#2413ADD.DF10,F8,F1014DADDIUR2,R2,#2415DSLTUR3,R1,R416ADD.DF14,F12,F1417S.DF6,-24(R2)18S.DF10,-16(R2)19BNEZR3,foo20S.DF14,-8(R2)FigureS.19Continuedc.SeeFiguresS.20andS.21.Unrolled6times:MemoryMemoryIntegeropera-Cyclereference1reference2FPoperation1FPoperation2tion/branch1L.DF1,0(R1)L.DF2,8(R1)2L.DF3,16(R1)L.DF4,24(R1)3L.DF5,32(R1)L.DF6,40(R1)MUL.DF1,F1,F0MUL.DF2,F2,F04L.DF7,0(R2)L.DF8,8(R2)MUL.DF3,F3,F0MUL.DF4,F4,F05L.DF9,16(R2)L.DF10,24(R2)MUL.DF5,F5,F0MUL.DF6,F6,F06L.DF11,32(R2)L.DF12,40(R2)7DADDIUR1,R1,488DADDIUR2,R2,48FigureS.2015cyclesfor34operations,yielding2.67issuesperclock,withaVLIWefficiencyof34operationsfor75slots=45.3%.Thisschedulerequires12floating-pointregisters.Copyright©2012Elsevier,Inc.Allrightsreserved.
26■SolutionstoCaseStudiesandExercises9ADD.DF7,F7,F1ADD.DF8,F8,F210ADD.DF9,F9,F3ADD.DF10,F10,F411ADD.DF11,F11,F5ADD.DF12,F12,F612DSLTUR3,R1,R413S.DF7,-48(R2)S.DF8,-40(R2)14S.DF9,-32(R2)S.DF10,-24(R2)15S.DF11,-16(R2)S.DF12,-8(R2)BNEZR3,fooFigureS.20ContinuedUnrolled10times:MemoryMemoryIntegerCyclereference1reference2FPoperation1FPoperation2operation/branch1L.DF1,0(R1)L.DF2,8(R1)2L.DF3,16(R1)L.DF4,24(R1)3L.DF5,32(R1)L.DF6,40(R1)MUL.DF1,F1,F0MUL.DF2,F2,F04L.DF7,48(R1)L.DF8,56(R1)MUL.DF3,F3,F0MUL.DF4,F4,F05L.DF9,64(R1)L.DF10,72(R1)MUL.DF5,F5,F0MUL.DF6,F6,F06L.DF11,0(R2)L.DF12,8(R2)MUL.DF7,F7,F0MUL.DF8,F8,F07L.DF13,16(R2)L.DF14,24(R2)MUL.DF9,F9,F0MUL.DF10,F10,F0DADDIUR1,R1,488L.DF15,32(R2)L.DF16,40(R2)DADDIUR2,R2,489L.DF17,48(R2)L.DF18,56(R2)ADD.DF11,F11,F1ADD.DF12,F12,F210L.DF19,64(R2)L.DF20,72(R2)ADD.DF13,F13,F3ADD.DF14,F14,F411ADD.DF15,F15,F5ADD.DF16,F16,F612ADD.DF17,F17,F7ADD.DF18,F18,F8DSLTUR3,R1,R413S.DF11,-80(R2)S.DF12,-72(R2)ADD.DF19,F19,F9ADD.DF20,F20,F1014S.DF13,-64(R2)S.DF14,-56(R2)15S.DF15,-48(R2)S.DF16,-40(R2)16S.DF17,-32(R2)S.DF18,-24(R2)17S.DF19,-16(R2)S.DF20,-8(R2)BNEZR3,fooFigureS.2117cyclesfor54operations,yielding3.18issuesperclock,withaVLIWefficiencyof54operationsfor85slots=63.5%.Thisschedulerequires20floating-pointregisters.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■273.14a.SeeFigureS.22.Executes/IterationInstructionIssuesatMemoryWriteCDBatComment1L.DF2,0(R1)123Firstissue1MUL.DF4,F2,F02419WaitforF2Multrs[3–4]Multuse[5–18]1L.DF6,0(R2)345Ldbuf[4]1ADD.DF6,F4,F642030WaitforF4Addrs[5–20]Adduse[21–29]1S.DF6,0(R2)531WaitforF6Stbuf1[6–31]1DADDIUR1,R1,#86781DADDIUR2,R2,#87891DSLTUR3,R1,R489101BNEZR3,foo911WaitforR32L.DF2,0(R1)101213WaitforBNEZLdbuf[11–12]2MUL.DF4,F2,F0111434WaitforF219MultbusyMultrs[12–19]Multuse[20–33]2L.DF6,0(R2)121314Ldbuf[13]2ADD.DF6,F4,F6133545WaitforF4Addrs[14–35]Adduse[36–44]2S.DF6,0(R2)1446WaitforF6Stbuf[15–46]2DADDIUR1,R1,#81516172DADDIUR2,R2,#81617182DSLTUR3,R1,R41718202BNEZR3,foo1820WaitforR33L.DF2,0(R1)192122WaitforBNEZLdbuf[20–21]3MUL.DF4,F2,F0202349WaitforF234MultbusyMultrs[21–34]Multuse[35–48]3L.DF6,0(R2)212223Ldbuf[22]3ADD.DF6,F4,F6225060WaitforF4Addrs[23–49]Adduse[51–59]FigureS.22Solutionforexercise3.14a.Copyright©2012Elsevier,Inc.Allrightsreserved.
28■SolutionstoCaseStudiesandExercises3S.DF6,0(R2)2355WaitforF6Stbuf[24–55]3DADDIUR1,R1,#82425263DADDIUR2,R2,#82526273DSLTUR3,R1,R42627283BNEZR3,foo2729WaitforR3FigureS.22Continuedb.SeeFigureS.23.Executes/IterationInstructionIssuesatMemoryWriteCDBatComment1L.DF2,0(R1)1231MUL.DF4,F2,F01419WaitforF2Multrs[2–4]Multuse[5]1L.DF6,0(R2)234Ldbuf[3]1ADD.DF6,F4,F622030WaitforF4Addrs[3–20]Adduse[21]1S.DF6,0(R2)331WaitforF6Stbuf[4–31]1DADDIUR1,R1,#83451DADDIUR2,R2,#84561DSLTUR3,R1,R4467INTbusyINTrs[5–6]1BNEZR3,foo57INTbusyINTrs[6–7]2L.DF2,0(R1)689WaitforBEQZ2MUL.DF4,F2,F061025WaitforF2Multrs[7–10]Multuse[11]2L.DF6,0(R2)7910INTbusyINTrs[8–9]2ADD.DF6,F4,F672636WaitforF4AddRS[8–26]Adduse[27]2S.DF6,0(R2)837WaitforF62DADDIUR1,R1,#881011INTbusyINTrs[8–10]FigureS.23Solutionforexercise3.14b.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■292DADDIUR2,R2,#891112INTbusyINTrs[10–11]2DSLTUR3,R1,R491213INTbusyINTrs[10–12]2BNEZR3,foo1014WaitforR33L.DF2,0(R1)111516WaitforBNEZ3MUL.DF4,F2,F0111732WaitforF2Multrs[12–17]Multuse[17]3L.DF6,0(R2)121617INTbusyINTrs[13–16]3ADD.DF6,F4,F6123343WaitforF4Addrs[13–33]Adduse[33]3S.DF6,0(R2)1444WaitforF6INTrsfullin153DADDIUR1,R1,#81517INTrsfullandbusyINTrs[17]3DADDIUR2,R2,#81618INTrsfullandbusyINTrs[18]3DSLTUR3,R1,R42021INTrsfull3BNEZR3,foo2122INTrsfullFigureS.23Continued3.15SeeFigureS.24.InstructionIssuesatExecutes/MemoryWriteCDBatADD.DF2,F4,F61212ADDR1,R1,R2234ADDR1,R1,R2356ADDR1,R1,R2478ADDR1,R1,R25910ADDR1,R1,R261112(CDBconflict)FigureS.24Solutionforexercise3.15.Copyright©2012Elsevier,Inc.Allrightsreserved.
30■SolutionstoCaseStudiesandExercises3.16SeeFiguresS.25andS.26.CorrelatingPredictorBranchPCmod4EntryPredictionOutcomeMispredict?TableUpdate24TTnonone36NTNTnochangeto“NT”12NTNTnonone37NTNTnonone13TNTyeschangeto“Twithonemisprediction”24TTnonone13TNTyeschangeto“NT”24TTnonone37NTTyeschangeto“NTwithonemisprediction”FigureS.25Individualbranchoutcomes,inorderofexecution.Mispredictionrate=3/9=.33.LocalPredictorBranchPCmod2EntryPredictionOutcomeMispredict?TableUpdate00TTnochangeto“T”14TNTyeschangeto“Twithonemisprediction”11NTNTnonone13TNTyeschangeto“Twithonemisprediction”13TNTyeschangeto“NT”00TTnonone13NTNTnonone00TTnonone15TTnochangeto“T”FigureS.26Individualbranchoutcomes,inorderofexecution.Mispredictionrate=3/9=.33.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter3Solutions■313.17ForthisproblemwearegiventhebaseCPIwithoutbranchstalls.FromthiswecancomputethenumberofstallsgivenbynoBTBandwiththeBTB:CPInoBTBandCPIBTBandtheresultingspeedupgivenbytheBTB:CPICPI+StallsnoBTBbasebaseSpeedup=-------------------------=---------------------------------------------------CPICPI+StallsBTBbaseBTBStalls==15%×20.30noBTBTocomputeStallsBTB,considerthefollowingtable:BTBPenaltyBTBResultPredictionFrequency(PerInstruction)(Cycles)Miss15%×10%=1.5%3HitCorrect15%×90%×90%=12.1%0HitIncorrect15%×90%×10%=1.3%4FigureS.27Weightedpenaltiesforpossiblebranchoutcomes.Therefore:StallsBTB==()1.5%×3++1()12.1%×0()1.3%×4.21.0+0.30Speedup==---------------------------1.21.0+0.0973.18a.Storingthetargetinstructionofanunconditionalbrancheffectivelyremovesoneinstruction.IfthereisaBTBhitininstructionfetchandthetargetinstructionisavailable,thenthatinstructionisfedintodecodeinplaceofthebranchinstruction.Thepenaltyis–1cycle.Inotherwords,itisaperfor-mancegainof1cycle.b.IftheBTBstoresonlythetargetaddressofanunconditionalbranch,fetchhastoretrievethenewinstruction.ThisgivesusaCPItermof5%×(90%×0+10%×2)of0.01.ThetermrepresentstheCPIforunconditionalbranches(weightedbytheirfrequencyof5%).IftheBTBstoresthetargetinstructioninstead,theCPItermbecomes5%×(90%×(–1)+10%×2)or–0.035.ThenegativesigndenotesthatitreducestheoverallCPIvalue.Thehitpercentagetojustbreakevenissimply20%.Copyright©2012Elsevier,Inc.Allrightsreserved.
32■SolutionstoCaseStudiesandExercisesChapter4SolutionsCaseStudy:ImplementingaVectorKernelonaVectorProcessorandGPU4.1MIPScode(answersmayvary)li$r1,#0#initializekloop:l.s$f0,0($RtipL)#loadallvaluesforfirstexpressionl.s$f1,0($RclL)l.s$f2,4($RtipL)l.s$f3,4($RclL)l.s$f4,8($RtipL)l.s$f5,8($RclL)l.s$f6,12($RtipL)l.s$f7,12($RclL)l.s$f8,0($RtipR)l.s$f9,0($RclR)l.s$f10,4($RtipR)l.s$f11,4($RclR)l.s$f12,8($RtipR)l.s$f13,8($RclR)l.s$f14,12($RtipR)l.s$f15,12($RclR)mul.s$f16,$f0,$f1#firstfourmultipliesmul.s$f17,$f2,$f3mul.s$f18,$f4,$f5mul.s$f19,$f6,$f7add.s$f20,$f16,$f17#accumulateadd.s$f20,$f20,$f18add.s$f20,$f20,$f19mul.s$f16,$f8,$f9#secondfourmultipliesmul.s$f17,$f10,$f11mul.s$f18,$f12,$f13mul.s$f19,$f14,$f15add.s$f21,$f16,$f17#accumulateadd.s$f21,$f21,$f18add.s$f21,$f21,$f19mul.s$f20,$f20,$f21#finalmultiplyst.s$f20,0($RclP)#storeresultadd$RclP,$RclP,#4#incrementclPfornextexpressionadd$RtiPL,$RtiPL,#16#incrementtiPLfornextexpressionCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter4Solutions■33add$RtiPR,$RtiPR,#16#incrementtiPRfornextexpressionaddi$r1,$r1,#1and$r2,$r2,#3#checktoseeifweshouldincrementclLandclR(every4bits)bneq$r2,skipadd$RclL,$RclL,#16#incrementtiPLfornextloopiterationadd$RclR,$RclR,#16#incrementtiPRfornextloopiterationskip:blt$r1,$r3,loop#assumer3=seq_length*4VMIPScode(answersmayvary)li$r1,#0#initializekli$VL,#4#initializevectorlengthloop:lv$v0,0($RclL)lv$v1,0($RclR)lv$v2,0($RtipL)#loadalltipLvalueslv$v3,16($RtipL)lv$v4,32($RtipL)lv$v5,48($RtipL)lv$v6,0($RtipR)#loadalltipRvalueslv$v7,16($RtipR)lv$v8,32($RtipR)lv$v9,48($RtipR)mulvv.s$v2,$v2,$v0#multiplyleftsub-expressionsmulvv.s$v3,$v3,$v0mulvv.s$v4,$v4,$v0mulvv.s$v5,$v5,$v0mulvv.s$v6,$v6,$v1#multiplyrightsub-expressionmulvv.s$v7,$v7,$v1mulvv.s$v8,$v8,$v1mulvv.s$v9,$v9,$v1sumr.s$f0,$v2#reduceleftsub-expressionssumr.s$f1,$v3sumr.s$f2,$v4sumr.s$f3,$v5sumr.s$f4,$v6#reducerightsub-expressionssumr.s$f5,$v7sumr.s$f6,$v8sumr.s$f7,$v9mul.s$f0,$f0,$f4#multiplyleftandrightsub-expressionsCopyright©2012Elsevier,Inc.Allrightsreserved.
34■SolutionstoCaseStudiesandExercisesmul.s$f1,$f1,$f5mul.s$f2,$f2,$f6mul.s$f3,$f3,$f7s.s$f0,0($Rclp)#storeresultss.s$f1,4($Rclp)s.s$f2,8($Rclp)s.s$f3,12($Rclp)add$RtiPL,$RtiPL,#64#incrementtiPLfornextexpressionadd$RtiPR,$RtiPR,#64#incrementtiPRfornextexpressionadd$RclP,$RclP,#16#incrementclPfornextexpressionadd$RclL,$RclL,#16#incrementclLfornextexpressionadd$RclR,$RclR,#16#incrementclRfornextexpressionaddi$r1,$r1,#1blt$r1,$r3,loop#assumer3=seq_length4.2MIPS:loopis41instructions,williterate500×4=2000times,soroughly82000instructionsVMIPS:loopisalso41instructionsbutwilliterateonly500times,soroughly20500instructions4.31.lv#clL2.lv#clR3.lvmulvv.s#tiPL04.lvmulvv.s#tiPL15.lvmulvv.s#tiPL26.lvmulvv.s#tiPL37.lvmulvv.s#tiPR08.lvmulvv.s#tiPR19.lvmulvv.s#tiPR210.lvmulvv.s#tiPR311.sumr.s12.sumr.s13.sumr.s14.sumr.s15.sumr.s16.sumr.s17.sumr.s18.sumr.s18chimes,4results,15FLOPSperresult,18/15=1.2cyclesperFLOPCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter4Solutions■354.4Inthiscase,the16valuescouldbeloadedintoeachvectorregister,performingvec-tormultipliesfromfouriterationsoftheloopinsinglevectormultiplyinstructions.Thiscouldreducetheiterationcountoftheloopbyafactorof4.However,withoutawaytoperformreductionsonasubsetofvectorelements,thistechniquecannotbeappliedtothiscode.4.5__global__voidcompute_condLike(float*clL,float*clR,float*clP,float*tiPL,float*tiPR){inti,k=threadIdx.x;__shared__floatclL_s[4],clR_s[4];for(i=0;i<4;i++){clL_s[i]=clL[k*4+i];clR_s[i]=clR[k*4+i];}clP[k*4]=(tiPL[k*16+AA]*clL_s[A]+tiPL[k*16+AC]*clL_s[C]+tiPL[k*16+AG]*clL_s[G]+tiPL[k*16+AT]*clL_s[T])*(tiPR[k*16+AA]*clR_s[A]+tiPR[k*16+AC]*clR_s[C]+tiPR[k*16+AG]*clR_s[G]+tiPR[k*16+AT]*clR_s[T]);clP[k*4+1]=(tiPL[k*16+CA]*clL_s[A]+tiPL[k*16+CC]*clL_s[C]+tiPL[k*16+CG]*clL_s[G]+tiPL[k*16+CT]*clL_s[T])*(tiPR[k*16+CA]*clR_s[A]+tiPR[k*16+CC]*clR_s[C]+tiPR[k*16+CG]*clR_s[G]+tiPR[k*16+CT]*clR_s[T]);clP[k*4+2]=(tiPL[k*16+GA]*clL_s[A]+tiPL[k*16+GC]*clL_s[C]+tiPL[k*16+GG]*clL_s[G]+tiPL[k*16+GT]*clL_s[T])*(tiPR[k*16+GA]*clR_s[A]+tiPR[k*16+GC]*clR_s[C]+tiPR[k*16+GG]*clR_s[G]+tiPR[k*16+GT]*clR_s[T]);clP[k*4+3]=(tiPL[k*16+TA]*clL_s[A]+tiPL[k*16+TC]*clL_s[C]+tiPL[k*16+TG]*clL_s[G]+tiPL[k*16+TT]*clL_s[T])*(tiPR[k*16+TA]*clR_s[A]+tiPR[k*16+TC]*clR_s[C]+tiPR[k*16+TG]*clR_s[G]+tiPR[k*16+TT]*clR_s[T]);}4.6clP[threadIdx.x*4+blockIdx.x+12*500*4]clP[threadIdx.x*4+1+blockIdx.x+12*500*4]clP[threadIdx.x*4+2+blockIdx.x+12*500*4]clP[threadIdx.x*4+3+blockIdx.x+12*500*4]clL[threadIdx.x*4+i+blockIdx.x*2*500*4]clR[threadIdx.x*4+i+(blockIdx.x*2+1)*500*4]Copyright©2012Elsevier,Inc.Allrightsreserved.
36■SolutionstoCaseStudiesandExercisestipL[threadIdx.x*16+AA+blockIdx.x*2*500*16]tipL[threadIdx.x*16+AC+blockIdx.x*2*500*16]…tipL[threadIdx.x*16+TT+blockIdx.x*2*500*16]tipR[threadIdx.x*16+AA+(blockIdx.x*2+1)*500*16]tipR[threadIdx.x*16+AC+1+(blockIdx.x*2+1)*500*16]…tipR[threadIdx.x*16+TT+15+(blockIdx.x*2+1)*500*16]4.7#computeaddressofclLmul.u64%r1,%ctaid.x,4000#multiplyblockindexby4000mul.u64%r2,%tid.x,4#multiplythreadindexby4add.u64%r1,%r1,%r2#addproductsld.param.u64%r2,[clL]#loadbaseaddressofclLadd.u64%r1,%r2,%r2#addbasetooffset#computeaddressofclRadd.u64%r2,%ctaid.x,1#add1toblockindexmul.u64%r2,%r2,4000#multiplyby4000mul.u64%r3,%tid.x,4#multiplythreadindexby4add.u64%r2,%r2,%r3#addproductsld.param.u64%r3,[clR]#loadbaseaddressofclRadd.u64%r2,%r2,%r3#addbasetooffsetld.global.f32%f1,[%r1+0]#moveclLandclRintosharedmemoryst.shared.f32[clL_s+0],%f1#(unrolltheloop)ld.global.f32%f1,[%r2+0]st.shared.f32[clR_s+0],%f1ld.global.f32%f1,[%r1+4]st.shared.f32[clL_s+4],%f1ld.global.f32%f1,[%r2+4]st.shared.f32[clR_s+4],%f1ld.global.f32%f1,[%r1+8]st.shared.f32[clL_s+8],%f1ld.global.f32%f1,[%r2+8]st.shared.f32[clR_s+8],%f1ld.global.f32%f1,[%r1+12]st.shared.f32[clL_s+12],%f1ld.global.f32%f1,[%r2+12]st.shared.f32[clR_s+12],%f1#computeaddressoftiPL:mul.u64%r1,%ctaid.x,16000#multiplyblockindexby4000mul.u64%r2,%tid.x,64#multiplythreadindexby16floatsadd.u64%r1,%r1,%r2#addproductsCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter4Solutions■37ld.param.u64%r2,[tipL]#loadbaseaddressoftipLadd.u64%r1,%r2,%r2#addbasetooffsetadd.u64%r2,%ctaid.x,1#computeaddressoftiPR:mul.u64%r2,%r2,16000#multiplyblockindexby4000mul.u64%r3,%tid.x,64#multiplythreadindexby16floatsadd.u64%r2,%r2,%r3#addproductsld.param.u64%r3,[tipR]#loadbaseaddressoftipLadd.u64%r2,%r2,%r3#addbasetooffset#computeaddressofclP:mul.u64%r3,%r3,24000#multiplyblockindexby4000mul.u64%r4,%tid.x,16#multiplythreadindexby4floatsadd.u64%r3,%r3,%r4#addproductsld.param.u64%r4,[tipR]#loadbaseaddressoftipLadd.u64%r3,%r3,%r4#addbasetooffsetld.global.f32%f1,[%r1]#loadtiPL[0]ld.global.f32%f2,[%r1+4]#loadtiPL[1]…ld.global.f32%f16,[%r1+60]#loadtiPL[15]ld.global.f32%f17,[%r2]#loadtiPR[0]ld.global.f32%f18,[%r2+4]#loadtiPR[1]…ld.global.f32%f32,[%r1+60]#loadtiPR[15]ld.shared.f32%f33,[clL_s]#loadclLld.shared.f32%f34,[clL_s+4]ld.shared.f32%f35,[clL_s+8]ld.shared.f32%f36,[clL_s+12]ld.shared.f32%f37,[clR_s]#loadclRld.shared.f32%f38,[clR_s+4]ld.shared.f32%f39,[clR_s+8]ld.shared.f32%f40,[clR_s+12]mul.f32%f1,%f1,%f33#firstexpressionmul.f32%f2,%f2,%f34mul.f32%f3,%f3,%f35mul.f32%f4,%f4,%f36add.f32%f1,%f1,%f2add.f32%f1,%f1,%f3add.f32%f1,%f1,%f4mul.f32%f17,%f17,%f37mul.f32%f18,%f18,%f38mul.f32%f19,%f19,%f39mul.f32%f20,%f20,%f40add.f32%f17,%f17,%f18add.f32%f17,%f17,%f19add.f32%f17,%f17,%f20st.global.f32[%r3],%f17#storeresultCopyright©2012Elsevier,Inc.Allrightsreserved.
38■SolutionstoCaseStudiesandExercisesmul.f32%f5,%f5,%f33#secondexpressionmul.f32%f6,%f6,%f34mul.f32%f7,%f7,%f35mul.f32%f8,%f8,%f36add.f32%f5,%f5,%f6add.f32%f5,%f5,%f7add.f32%f5,%f5,%f8mul.f32%f21,%f21,%f37mul.f32%f22,%f22,%f38mul.f32%f23,%f23,%f39mul.f32%f24,%f24,%f40add.f32%f21,%f21,%f22add.f32%f21,%f21,%f23add.f32%f21,%f21,%f24st.global.f32[%r3+4],%f21#storeresultmul.f32%f9,%f9,%f33#thirdexpressionmul.f32%f10,%f10,%f34mul.f32%f11,%11,%f35mul.f32%f12,%f12,%f36add.f32%f9,%f9,%f10add.f32%f9,%f9,%f11add.f32%f9,%f9,%f12mul.f32%f25,%f25,%f37mul.f32%f26,%f26,%f38mul.f32%f27,%f27,%f39mul.f32%f28,%f28,%f40add.f32%f25,%f26,%f22add.f32%f25,%f27,%f23add.f32%f25,%f28,%f24st.global.f32[%r3+8],%f25#storeresultmul.f32%f13,%f13,%f33#fourthexpressionmul.f32%f14,%f14,%f34mul.f32%f15,%f15,%f35mul.f32%f16,%f16,%f36add.f32%f13,%f14,%f6add.f32%f13,%f15,%f7add.f32%f13,%f16,%f8mul.f32%f29,%f29,%f37mul.f32%f30,%f30,%f38mul.f32%f31,%f31,%f39mul.f32%f32,%f32,%f40add.f32%f29,%f29,%f30add.f32%f29,%f29,%f31add.f32%f29,%f29,%f32st.global.f32[%r3+12],%f29#storeresultCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter4Solutions■394.8Itwillperformwell,sincetherearenobranchdivergences,allmemoryreferencesarecoalesced,andthereare500threadsspreadacross6blocks(3000totalthreads),whichprovidesmanyinstructionstohidememorylatency.Exercises4.9a.ThiscodereadsfourfloatsandwritestwofloatsforeverysixFLOPs,soarithmeticintensity=6/6=1.b.AssumeMVL=64:li$VL,44#performthefirst44opsli$r1,0#initializeindexloop:lv$v1,a_re+$r1#loada_relv$v3,b_re+$r1#loadb_remulvv.s$v5,$v1,$v3#a+re*b_relv$v2,a_im+$r1#loada_imlv$v4,b_im+$r1#loadb_immulvv.s$v6,$v2,$v4#a+im*b_imsubvv.s$v5,$v5,$v6#a+re*b_re-a+im*b_imsv$v5,c_re+$r1#storec_remulvv.s$v5,$v1,$v4#a+re*b_immulvv.s$v6,$v2,$v3#a+im*b_readdvv.s$v5,$v5,$v6#a+re*b_im+a+im*b_resv$v5,c_im+$r1#storec_imbne$r1,0,else#checkiffirstiterationaddi$r1,$r1,#44#firstiteration,incrementby44jloop#guaranteednextiterationelse:addi$r1,$r1,#256#notfirstiteration,incrementby256skip:blt$r1,1200,loop#nextiteration?c.1.mulvv.slv#a_re*b_re(assumealready#loaded),loada_im2.lvmulvv.s#loadb_im,a_im*b_im3.subvv.ssv#subtractandstorec_re4.mulvv.slv#a_re*b_im,loadnexta_revector5.mulvv.slv#a_im*b_re,loadnextb_revector6.addvv.ssv#addandstorec_im6chimesCopyright©2012Elsevier,Inc.Allrightsreserved.
40■SolutionstoCaseStudiesandExercisesd.totalcyclesperiteration=6chimes×64elements+15cycles(load/store)×6+8cycles(multiply)×4+5cycles(add/subtract)×2=516cyclesperresult=516/128=4e.1.mulvv.s#a_re*b_re2.mulvv.s#a_im*b_im3.subvv.ssv#subtractandstorec_re4.mulvv.s#a_re*b_im5.mulvv.slv#a_im*b_re,loadnexta_re6.addvv.ssvlvlvlv#add,storec_im,loadnextb_re,a_im,b_imSamecyclesperresultasinpartc.Addingadditionalload/storeunitsdidnotimproveperformance.4.10Vectorprocessorrequires:■(200MB+100MB)/(30GB/s)=10msforvectormemoryaccess+■400msforscalarexecution.Assumingthatvectorcomputationcanbeoverlappedwithmemoryaccess,totaltime=410ms.Thehybridsystemrequires:■(200MB+100MB)/(150GB/s)=2msforvectormemoryaccess+■400msforscalarexecution+■(200MB+100MB)/(10GB/s)=30msforhostI/OEvenifhostI/OcanbeoverlappedwithGPUexecution,theGPUwillrequire430msandthereforewillachievelowerperformancethanthehost.4.11a.for(i=0;i<32;i+=2)dot[i]=dot[i]+dot[i+1];for(i=0;i<16;i+=4)dot[i]=dot[i]+dot[i+2];for(i=0;i<8;i+=8)dot[i]=dot[i]+dot[i+4];for(i=0;i<4;i+=16)dot[i]=dot[i]+dot[i+8];for(i=0;i<2;i+=32)dot[i]=dot[i]+dot[i+16];dot[0]=dot[0]+dot[32];b.li$VL,4addvv.s$v0(0),$v0(4)addvv.s$v0(8),$v0(12)addvv.s$v0(16),$v0(20)addvv.s$v0(24),$v0(28)addvv.s$v0(32),$v0(36)addvv.s$v0(40),$v0(44)addvv.s$v0(48),$v0(52)addvv.s$v0(56),$v0(60)Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter4Solutions■41c.for(unsignedints=blockDim.x/2;s>0;s/=2){if(tid(30GB/s)×(0.18FLOPs/byte)=5.4GFLOPs/s,thenthiscodeislikelytobememory-bound,unlesstheworkingsetfitswellwithintheprocessor’scache.d.Thesingleprecisionarithmeticintensitycorrespondingtotheedgeoftheroofis85/4=21.25FLOPs/byte.4.13a.1.5GHz×.80×.85×0.70×10cores×32/4=57.12GFLOPs/sb.Option1:1.5GHz×.80×.85×.70×10cores×32/2=114.24GFLOPs/s(speedup=114.24/57.12=2)Option2:1.5GHz×.80×.85×.70×15cores×32/4=85.68GFLOPs/s(speedup=85.68/57.12=1.5)Option3:1.5GHz×.80×.95×.70×10cores×32/4=63.84GFLOPs/s(speedup=63.84/57.12=1.11)Option3isbest.4.14a.UsingtheGCDtest,adependencyexistsifGCD(2,4)mustdivide5–4.Inthiscase,aloop-carrieddependencydoesexist.b.OutputdependenciesS1andS3causethroughA[i]Anti-dependenciesS4andS3causeananti-dependencythroughC[i]Re-writtencodefor(i=0;i<100;i++){T[i]=A[i]*B[i];/*S1*/B[i]=T[i]+c;/*S2*/A1[i]=C[i]*c;/*S3*/C1[i]=D[i]*A1[i];/*S4*/}Copyright©2012Elsevier,Inc.Allrightsreserved.
42■SolutionstoCaseStudiesandExercisesTruedependenciesS4andS3throughA[i]S2andS1throughT[i]c.Thereisananti-dependencebetweeniterationiandi+1forarrayB.ThiscanbeavoidedbyrenamingtheBarrayinS2.4.15a.Branchdivergence:causesSIMDlanestobemaskedwhenthreadsfollowdifferentcontrolpathsb.Coveringmemorylatency:asufficientnumberofactivethreadscanhidememorylatencyandincreaseinstructionissueratec.Coalescedoff-chipmemoryreferences:memoryaccessesshouldbeorga-nizedconsecutivelywithinSIMDthreadgroupsd.Useofon-chipmemory:memoryreferenceswithlocalityshouldtakeadvan-tageofon-chipmemory,referencestoon-chipmemorywithinaSIMDthreadgroupshouldbeorganizedtoavoidbankconflicts4.16ThisGPUhasapeakthroughputof1.5×16×16=384GFLOPS/sofsingle-precisionthroughput.However,assumingeachsingleprecisionoperationrequiresfour-bytetwooperandsandoutputsonefour-byteresult,sustainingthisthroughput(assumingnotemporallocality)wouldrequire12bytes/FLOP×384GFLOPs/s=4.6TB/sofmemorybandwidth.Assuch,thisthroughputisnotsustainable,butcanstillbeachievedinshortburstswhenusingon-chipmemory.4.17Referencecodeforprogrammingexercise:#include#include#include#include__global__voidlife(unsignedchar*d_board,intiterations){inti,row,col,rows,cols;unsignedcharstate,neighbors;row=blockIdx.y*blockDim.y+threadIdx.y;col=blockIdx.x*blockDim.x+threadIdx.x;rows=gridDim.y*blockDim.y;cols=gridDim.x*blockDim.x;state=d_board[(row)*cols+(col)];for(i=0;i3)state=0;__syncthreads();d_board[(row)*cols+(col)]=state;}}intmain(){dim3gDim,bDim;unsignedchar*h_board,*d_board;inti,iterations=100;bDim.y=16;bDim.x=32;bDim.z=1;gDim.y=16;gDim.x=8;gDim.z=1;h_board=(unsignedchar*)malloc(sizeof(unsignedchar)*4096*4096);cudaMalloc((void**)&d_board,sizeof(unsignedchar)*4096*4096);srand(56);for(i=0;i<4096*4096;i++)h_board[i]=rand()%2;cudaMemcpy(d_board,h_board,sizeof(unsignedchar)*4096*4096,cudaMemcpyHostToDevice);life<<>>(d_board,iterations);cudaMemcpy(h_board,d_board,sizeof(unsignedchar)*4096*4096,cudaMemcpyDeviceToHost);free(h_board);cudaFree(d_board);}Copyright©2012Elsevier,Inc.Allrightsreserved.
44■SolutionstoCaseStudiesandExercisesChapter5SolutionsCaseStudy1:Single-ChipMulticoreMultiprocessor5.1a.P0:read120ÆP0.B0:(S,120,0020)returns0020b.P0:write120Å80ÆP0.B0:(M,120,0080)P3.B0:(I,120,0020)c.P3:write120Å80ÆP3.B0:(M,120,0080)d.P1:read110ÆP1.B2:(S,110,0010)returns0010e.P0:write108Å48ÆP0.B1:(M,108,0048)P3.B1:(I,108,0008)f.P0:write130Å78ÆP0.B2:(M,130,0078)M:110Å0030(writebacktomemory)g.P3:write130Å78ÆP3.B2:(M,130,0078)5.2a.P0:read120,Readmiss,satisfiedbymemoryP0:read128,Readmiss,satisfiedbyP1’scacheP0:read130,Readmiss,satisfiedbymemory,writeback110Implementation1:100+40+10+100+10=260stallcyclesImplementation2:100+130+10+100+10=350stallcyclesb.P0:read100,Readmiss,satisfiedbymemoryP0:write108Å48,Writehit,sendsinvalidateP0:write130Å78,Writemiss,satisfiedbymemory,writeback110Implementation1:100+15+10+100=225stallcyclesImplementation2:100+15+10+100=225stallcyclesc.P1:read120,Readmiss,satisfiedbymemoryP1:read128,ReadhitP1:read130,Readmiss,satisfiedbymemoryImplementation1:100+0+100=200stallcyclesImplementation2:100+0+100=200stallcyclesd.P1:read100,Readmiss,satisfiedbymemoryP1:write108Å48,Writemiss,satisfiedbymemory,writeback128P1:write130Å78,Writemiss,satisfiedbymemoryImplementation1:100+100+10+100=310stallcyclesImplementation2:100+100+10+100=310stallcycles5.3SeeFigureS.28Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■45WritemissorinvalidateforthisblockInvalidCPUreadSharedPlacereadmissonbusWritemissforthisblockInvalidateforthisblockCPUreadhitWritebackblock;abortmemoryaccessCPUwritePlaceinvalidateonbusCPUwriteWritebackblock;abortmemoryaccessPlacewritemissonbusWritemissforthisblockReadmissModifiedWritebackblock;abortOwnedmemoryaccessCPUwritePlaceinvalidateonbusCPUwritehitCPUreadhitCPUreadhitFigureS.28Protocoldiagram.5.4(Showingresultsforimplementation1)a.P1:read110,Readmiss,P0’scacheP3:read110,Readmiss,MSIsatisfiesinmemory,MOSIsatisfiesinP0’scacheP0:read110,ReadhitMSI:40+10+100+0=150stallcyclesMOSI:40+10+40+10+0=100stallcyclesb.P1:read120,Readmiss,satisfiedinmemoryP3:read120,ReadhitP0:read120,Readmiss,satisfiedinmemoryBothprotocols:100+0+100=200stallcyclesc.P0:write120Å80,Writemiss,invalidatesP3P3:read120,Readmiss,P0’scacheP0:read120,ReadhitBothprotocols:100+40+10+0=150stallcyclesCopyright©2012Elsevier,Inc.Allrightsreserved.
46■SolutionstoCaseStudiesandExercisesd.P0:write108Å88,Sendinvalidate,invalidateP3P3:read108,Readmiss,P0’scacheP0:write108Å98,Sendinvalidate,invalidateP3Bothprotocols:15+40+10+15=80stallcycles5.5SeeFigureS.29WritemissorinvalidateforthisblockInvalidCPUread,othersharedblockSharedPlacereadmissonbusWritemissorinvalidateforthisblockCPUreadhitCPUwriteCPUread,nosharesPlaceinvalidatePlacereadmissonbusonbusReadmissWritemissforthisblockWritebackblock;abortmemoryaccessCPUwritePlacewritemissonbusReadmissWritebackblock;abortmemoryModifiedaccessExcl.CPUwritehitCPUwritehitCPUreadhitCPUreadhitFigureS.29DiagramforaMESIprotocol.5.6a.p0:read100,Readmiss,satisfiedinmemory,nosharersMSI:S,MESI:Ep0:write100Å40,MSI:sendinvalidate,MESI:silenttransitionfromEtoMMSI:100+15=115stallcyclesMESI:100+0=100stallcyclesb.p0:read120,Readmiss,satisfiedinmemory,sharersbothtoSp0:write120Å60,BothsendinvalidatesBoth:100+15=115stallcyclesc.p0:read100,Readmiss,satisfiedinmemory,nosharersMSI:S,MESI:Ep0:read120,Readmiss,memory,silentlyreplace120fromSorEBoth:100+100=200stallcycles,silentreplacementfromECopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■47d.p0:read100,Readmiss,satisfiedinmemory,nosharersMSI:S,MESI:Ep1:write100Å60,Writemiss,satisfiedinmemoryregardlessofprotocolBoth:100+100=200stallcycles,don’tsupplydatainEstate(someprotocolsdo)e.p0:read100,Readmiss,satisfiedinmemory,nosharersMSI:S,MESI:Ep0:write100Å60,MSI:sendinvalidate,MESI:silenttransitionfromEtoMp1:write100Å40,Writemiss,P0’scache,writebackdatatomemoryMSI:100+15+40+10=165stallcyclesMESI:100+0+40+10=150stallcycles5.7a.Assumetheprocessorsacquirethelockinorder.P0willacquireitfirst,incur-ring100stallcyclestoretrievetheblockfrommemory.P1andP3willstalluntilP0’scriticalsectionends(ping-pongingtheblockbackandforth)1000cycleslater.P0willstallfor(about)40cycleswhileitfetchestheblocktoinvalidateit;thenP1takes40cyclestoacquireit.P1’scriticalsectionis1000cycles,plus40tohandlethewritemissatrelease.Finally,P3grabstheblockforafinal40cyclesofstall.So,P0stallsfor100cyclestoacquire,10togiveittoP1,40toreleasethelock,andafinal10tohanditofftoP1,foratotalof160stallcycles.P1essentiallystallsuntilP0releasesthelock,whichwillbe100+1000+10+40=1150cycles,plus40togetthelock,10togiveittoP3,40togetitbacktoreleasethelock,andafinal10tohanditbacktoP3.Thisisatotalof1250stallcycles.P3stallsuntilP1handsitoffthereleasedlock,whichwillbe1150+40+10+1000+40=2240cycles.Finally,P3getsthelock40cycleslater,soitstallsatotalof2280cycles.b.Theoptimizedspinlockwillhavemanyfewerstallcyclesthantheregularspinlockbecauseitspendsmostofthecriticalsectionsittinginaspinloop(whichwhileuseless,isnotdefinedasastallcycle).Usingtheanalysisbelowfortheinterconnecttransactions,thestallcycleswillbe3readmemorymisses(300),1upgrade(15)and1writemisstoacache(40+10)and1writemisstomemory(100),1readcachemisstocache(40+10),1writemisstomemory(100),1readmisstocacheand1readmisstomemory(40+10+100),followedbyanupgrade(15)andawritemisstocache(40+10),andfinallyawritemisstocache(40+10)followedbyareadmisstocache(40+10)andanupgrade(15).Soapproximately945cyclestotal.c.Approximately31interconnecttransactions.Thefirstprocessortowinarbi-trationfortheinterconnectgetstheblockonitsfirsttry(1);theothertwoping-pongtheblockbackandforthduringthecriticalsection.Becausethelatencyis40cycles,thiswilloccurabout25times(25).Thefirstprocessordoesawritetoreleasethelock,causinganotherbustransaction(1),andthesecondprocessordoesatransactiontoperformitstestandset(1).Thelastprocessorgetstheblock(1)andspinsonituntilthesecondprocessorreleasesit(1).Finallythelastprocessorgrabstheblock(1).Copyright©2012Elsevier,Inc.Allrightsreserved.
48■SolutionstoCaseStudiesandExercisesd.Approximately15interconnecttransactions.Assumeprocessorsacquirethelockinorder.Allthreeprocessorsdoatest,causingareadmiss,thenatestandset,causingthefirstprocessortoupgradeandtheothertwotowritemiss(6).Theloserssitinthetestloop,andoneofthemneedstogetbackasharedblockfirst(1).Whenthefirstprocessorreleasesthelock,ittakesawritemiss(1)andthenthetwoloserstakereadmisses(2).Bothhavetheirtestsucceed,sothenewwinnerdoesanupgradeandthenewlosertakesawritemiss(2).Theloserspinsonanexclusiveblockuntilthewinnerreleasesthelock(1).Theloserfirstteststheblock(1)andthentest-and-setsit,whichrequiresanupgrade(1).5.8Latenciesinimplementation1ofFigure5.36areused.a.P0:write110Å80HitinP0’scache,nostallcyclesforeitherTSOorSCP0:read108HitinP0’scache,nostallcyclesforeitherTSOorSCb.P0:write100Å80Miss,TSOsatisfieswriteinwritebuffer(0stallcycles)SCmustwaituntilitreceivesthedata(100stallcycles)P0:read108Hit,butmustwaitforprecedingoperation:TSO=0,SC=100c.P0:write110Å80HitinP0’scache,nostallcyclesforeitherTSOorSCP0:write100Å90Miss,TSOsatisfieswriteinwritebuffer(0stallcycles)SCmustwaituntilitreceivesthedata(100stallcycles)d.P0:write100Å80Miss,TSOsatisfieswriteinwritebuffer(0stallcycles)SCmustwaituntilitreceivesthedata(100stallcycles)P0:write110Å90Hit,butmustwaitforprecedingoperation:TSO=0,SC=100CaseStudy2:SimpleDirectory-BasedCoherence5.9a.P0,0:read100L1hitreturns0x0010,stateunchanged(M)b.P0,0:read128L1missandL2misswillreplaceB1inL1andB1inL2whichhasaddress108.L1willhave128inB1(shared),L2alsowillhaveit(DS,P0,0)Memorydirectoryentryfor108willbecomeMemorydirectoryentryfor128willbecomec,d,…,h:followsameapproachCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■495.10a.P0,0:write100Å80,WritehitonlyseenbyP0,0b.P0,0:write108Å88,Write“upgrade”receivedbyP0,0;invalidatereceivedbyP3,1c.P0,0:write118Å90,WritemissreceivedbyP0,0;invalidatereceivedbyP1,0d.P1,0:write128Å98,WritemissreceivedbyP1,0.5.11a.SeeFiguresS.30andS.31CPUreadmissReadmissInvalidateInvalidCPUreadSharedSendreadmessageCPUreadhitCPUwriteSendinvalidateCPUwritemessageInvalidateFetchinvalidateFetchinvalidateWritedatabackWritedatabackSendwritemissmessageFetchWritedatabackCPUreadmissCPUwritemissCPUwritemissWritedatabackWritedatabackReadmissReadmissWritemissModifiedSenddataOwnedCPUwriteSendinvalidatemessageCPUwritehitCPUreadhitCPUreadhitFigureS.30Cachestates.5.12TheExclusivestate(E)combinespropertiesofModified(M)andShared(S).TheEstateallowssilentupgradestoM,allowingtheprocessortowritetheblockwithoutcommunicatingthisfacttomemory.ItalsoallowssilentdowngradestoI,allowingtheprocessortodiscarditscopywithnotifyingmemory.Thememorymusthaveawayofinferringeitherofthesetransitions.Inadirectory-basedsystem,thisistypicallydonebyhavingthedirectoryassumethatthenodeisinstateMandforwardingallmissestothatnode.IfanodehassilentlydowngradedtoI,thenitsendsaNACK(NegativeAcknowledgment)backtothedirectory,whichtheninfersthatthedowngradeoccurred.However,thisresultsinaracewithothermes-sages,whichcancauseotherproblems.Copyright©2012Elsevier,Inc.Allrightsreserved.
50■SolutionstoCaseStudiesandExercisesReadmissInvalidDatavaluereply,SharedSharers={P}ReadmissDatavaluereplySharers=sharers+{P}{}{P}==sharers–{P}Writemiss{P}=Sendinvalidate=smessagetosharersDatawritebackSharersWritemissDatavaluereplySharersDatavaluereplySharerDatawritebackSharersReadmissFetchReadmissDatavalueresponseFetch;DatavaluereplySharers=sharers+{P}ModifiedSharers=sharers+{P}OwnedWritemissFetchinvalidateDatavalueresponseSharers={P}WritemissFetchinvalidateDatavalueresponseSharers={P}FigureS.31Directorystates.CaseStudy3:AdvancedDirectoryProtocol5.13a.P0,0:read100Readhitb.P0,0:read120Miss,willreplacemodifieddata(B0)andgetnewlineinsharedstateP0,0:MÆMIAÆIÆISDÆSDir:DM{P0,0}ÆDI{}c.P0,0:write120Å80Misswillreplacemodifieddata(B0)andgetnewlineinmodifiedstateP0,0:MÆMIAÆIÆIMADÆIMAÆMP3,1:SÆIDir:DS{P3,0}ÆDM{P0,0}d,e,f:stepssimilartopartsa,b,andc5.14a.P0,0:read120Miss,willreplacemodifieddata(B0)andgetnewlineinsharedstateP0,0:MÆMIAÆIÆISDÆSCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■51P1,0:read120Miss,willreplacemodifieddata(B0)andgetnewlineinsharedstateP1,0:MÆMIAÆIÆISDÆSDir:DS{P3,0}ÆDS{P3,0;P0,0}ÆDS{P3,0;P0,0;P1,0}b.P0,0:read120Miss,willreplacemodifieddata(B0)andgetnewlineinsharedstateP0,0:MÆMIAÆIÆISDÆSP1,0:write120Å80Misswillreplacemodifieddata(B0)andgetnewlineinmodifiedstateP1,0:MÆMIAÆIÆIMADÆIMAÆMP3,1:SÆIDir:DS{P3,1}ÆDS{P3,0;P1,0}ÆDM{P1,0}c,d,e:stepssimilartopartsaandb5.15a.P0,0:read100Readhit,1cycleb.P0,0:read120ReadMiss,causesmodifiedblockreplacementandissatisfiedinmemoryandincurs4chipcrossings(seeunderlined)LatencyforP0,0:Lsend_data+Ldata_msg+Lwrite_memory+Linv+L_ack+Lreq_msg+Lsend_msg+Lreq_msg+Lread_memory+Ldata_msg+Lrcv_data+4×chipcrossingslatency=20+30+20+1+4+15+6+15+100+30+15+4×20=336c,d,e:followsamestepsasaandb5.16Allprotocolsmustensureforwardprogress,evenunderworst-casememoryaccesspatterns.Itiscrucialthattheprotocolimplementationguarantee(atleastwithaprobabilisticargument)thataprocessorwillbeabletoperformatleastonemem-oryoperationeachtimeitcompletesacachemiss.Otherwise,starvationmightresult.Considerthesimplespinlockcode:tas:DADDUIR2,R0,#1lockit:EXCHR2,0(R1)BNEZR2,lockitIfallprocessorsarespinningonthesameloop,theywillallrepeatedlyissueGetMmessages.Ifaprocessorisnotguaranteedtobeabletoperformatleastoneinstruction,theneachcouldstealtheblockfromtheotherrepeatedly.Intheworstcase,noprocessorcouldeversuccessfullyperformtheexchange.Copyright©2012Elsevier,Inc.Allrightsreserved.
52■SolutionstoCaseStudiesandExercises5.17a.TheMSAstateisessentiallya“transientO”becauseitallowstheprocessortoreadthedataanditwillrespondtoGetSharedandGetModifiedrequestsfromotherprocessors.Itistransient,andnotarealOstate,becausememorywillsendthePutM_Ackandtakeresponsibilityforfuturerequests.b.SeeFiguresS.32andS.33Replace-Forwarded_Forwarded_PutM_StateReadWritementINVGetSGetMAckDataLastACKIsendsenderrorsenderrorerrorerrorerrorerrorGetS/ISGetM/IMAck/ISdoReadsendIsenderrorerrorerrorerrorerrorGetM/IMAck/IOdoReadsendsenderrorsendDatasendData/Ierror——GetM/OMPutM/OIMdoReaddoWritesenderrorsendData/OsendData/IerrorerrorerrorPutM/MIISzzzsenderrorerrorerrorsaveData,errorAck/ISIdoRead/SISIzzzsendAckerrorerrorerrorsaveData,errordoRead/IIMzzzsendAckIMOIMIAerrorsaveDatadoWrite/MIMIzzzerrorerrorerrorerrorsaveDatadoWrite,sendData/IIMOzzzsend—IMOIerrorsaveDatadoWrite,Ack/IMIsendData/OIMOIzzzerrorerrorerrorerrorsaveDatadoWrite,sendData/IOIzzzerrorsendDatasendData/IerrorerrorMIzzzerrorsendDatasendData/IerrorerrorOMzzzerrorsendDatasendData/IMerrorsaveDatadoWrite/MFigureS.32Directoryprotocolcachecontrollertransitions.ReplacementINVStateReadWrite(owner)(nonowner)DIsendData,sendData,clearsharers,errorsendPutM_Ackaddtosharers/DSsetowner/DMDSsendData,sendINVstosharers,errorsendPutM_Ackaddtosharersclearsharers,setowner,sendData/DMDOforwardGetS,forwardGetM,sendINVssendData,sendsendPutM_Ackaddtosharerstosharers,clearsharers,PutM_Ack/DSsetowner/DMDMforwardGetS,forwardGetM,sendINVssendData,sendsendPutM_Ackaddtorequesterandtosharers,clearsharers,PutM_Ack/DIownertosharers/DOsetownerFigureS.33Directorycontrollertransitions.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■535.18a.P1,0:read100P3,1:write100Å90Inthisproblem,bothP0,1andP3,1missandsendrequeststhatracetothedirectory.AssumingthatP0,1’sGetSrequestarrivesfirst,thedirectorywillforwardP0,1’sGetStoP0,0,followedshortlyafterwardsbyP3,1’sGetM.Ifthenetworkmaintainspoint-to-pointorder,thenP0,0willseetherequestsintherightorderandtheprotocolwillworkasexpected.However,ifthefor-wardedrequestsarriveoutoforder,thentheGetXwillforceP0tostateI,causingittodetectanerrorwhenP1’sforwardedGetSarrives.b.P1,0:read100P0,0:replace100P1,0’sGetSarrivesatthedirectoryandisforwardedtoP0,0beforeP0,0’sPutMmessagearrivesatthedirectoryandsendsthePutM_Ack.However,ifthePutM_AckarrivesatP0,0outoforder(i.e.,beforetheforwardedGetS),thenthiswillcauseP0,0totransitiontostateI.Inthiscase,theforwardedGetSwillbetreatedasanerrorcondition.Exercises5.19ThegeneralformforAmdahl’sLawisExecutiontimeoldSpeedup=------------------------------------------------Executiontimenewallthatneedstobedonetocomputetheformulaforspeedupinthismultiproces-sorcaseistoderivethenewexecutiontime.TheexercisestatesthatfortheportionoftheoriginalexecutiontimethatcanuseiprocessorsisgivenbyF(i,p).IfweletExecutiontimeoldbe1,thentherelativetimefortheapplicationonpprocessorsisgivenbysummingthetimesrequiredforeachportionoftheexecutiontimethatcanbespedupusingiprocessors,whereiisbetween1andp.Thisyieldspfi(),pExecutiontimenew=∑-------------i=1iSubstitutingthisvalueforExecutiontimenewintothespeedupequationmakesAmdahl’sLawafunctionoftheavailableprocessors,p.5.20a.(i)64processorsarrangedaasaring:largestnumberofcommunicationhops=32Æcommunicationcost=(100+10×32)ns=420ns.(ii)64processorsarrangedas8x8processorgrid:largestnumberofcommu-nicationhops=14Æcommunicationcost=(100+10×14)ns=240ns.(iii)64processorsarrangedasahypercube:largestnumberofhops=6(log264)Æcommunicationcost=(100+10×6)ns=160ns.Copyright©2012Elsevier,Inc.Allrightsreserved.
54■SolutionstoCaseStudiesandExercisesb.BaseCPI=0.5cpi(i)64processorsarrangedaasaring:WorstcaseCPI=0.5+0.2/100×(420)=1.34cpi(ii)64processorsarrangedas8x8processorgrid:WorstcaseCPI=0.5+0.2/100×(240)=0.98cpi(iii)64processorsarrangedasahypercube:WorstcaseCPICPI=0.5+0.2/100×(160)=0.82cpiTheaverageCPIcanbeobtainedbyreplacingthelargestnumberofcommuni-cationshopsintheabovecalculationbyhˆ,theaveragenumbersofcommunica-tionshops.Thatlatternumberdependsonboththetopologyandtheapplication.c.SincetheCPUfrequencyandthenumberofinstructionsexecuteddidnotchange,theanswercanbeobtainedbytheCPIforeachofthetopologies(worstcaseoraverage)bythebase(noremotecommunication)CPI.5.21Tokeepthefiguresfrombecomingcluttered,thecoherenceprotocolissplitintotwopartsaswasdoneinFigure5.6inthetext.FigureS.34presentstheCPUportionofthecoherenceprotocol,andFigureS.35presentsthebusportionoftheprotocol.Inbothofthesefigures,thearcsindicatetransitionsandthetextalongeacharcindicatesthestimulus(innormaltext)andbusaction(inboldtext)thatoccursduringthetransitionbetweenstates.Finally,likethetext,weassumeawritehitishandledasawritemiss.FigureS.34presentsthebehaviorofstatetransitionscausedbytheCPUitself.Inthiscase,awritetoablockineithertheinvalidorsharedstatecausesustobroad-casta“writeinvalidate”toflushtheblockfromanyothercachesthatholdtheblockandmovetotheexclusivestate.Wecanleavetheexclusivestatethrougheitheraninvalidatefromanotherprocessor(whichoccursonthebussideofthecoherenceprotocolstatediagram),orareadmissgeneratedbytheCPU(whichoccurswhenanexclusiveblockofdataisdisplacedfromthecachebyasecondblock).InthesharedstateonlyawritebytheCPUoraninvalidatefromanotherprocessorcanmoveusoutofthisstate.InthecaseoftransitionscausedbyeventsexternaltotheCPU,thestatediagramisfairlysimple,asshowninFigureS.35.Whenanotherprocessorwritesablockthatisresidentinourcache,weuncondi-tionallyinvalidatethecorrespondingblockinourcache.Thisensuresthatthenexttimewereadthedata,wewillloadtheupdatedvalueoftheblockfrommemory.Also,wheneverthebusseesareadmiss,itmustchangethestateofanexclusiveblocktosharedastheblockisnolongerexclusivetoasinglecache.Themajorchangeintroducedinmovingfromawrite-backtowrite-throughcacheistheeliminationoftheneedtoaccessdirtyblocksinanotherprocessor’scaches.Asaresult,inthewrite-throughprotocolitisnolongernecessarytopro-videthehardwaretoforcewritebackonreadaccessesortoabortpendingmem-oryaccesses.Asmemoryisupdatedduringanywriteonawrite-throughcache,aprocessorthatgeneratesareadmisswillalwaysretrievethecorrectinformationfrommemory.Basically,itisnotpossibleforvalidcacheblockstobeincoherentwithrespecttomainmemoryinasystemwithwrite-throughcaches.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■55CPUreadSharedInvalid(readonly)CPUreadCPUwriteCPUreadInvalidateblockmissCPUwriteInvalidateblockExclusive(read/write)CPUreadhitorwriteFigureS.34CPUportionofthesimplecachecoherencyprotocolforwrite-throughcaches.WritemissSharedInvalidInvalidateblock(readonly)WritemissInvalidateblockExclusive(read/write)ReadmissFigureS.35Busportionofthesimplecachecoherencyprotocolforwrite-throughcaches.Copyright©2012Elsevier,Inc.Allrightsreserved.
56■SolutionstoCaseStudiesandExercises5.22ToaugmentthesnoopingprotocolofFigure5.7withaCleanExclusivestateweassumethatthecachecandistinguishareadmissthatwillallocateablockdestinedtohavetheCleanExclusivestatefromareadmissthatwilldeliveraSharedblock.Withoutfurtherdiscussionweassumethatthereissomemechanismtodoso.ThethreestatesofFigure5.7andthetransitionsbetweenthemareunchanged,withthepossibleclarifyingexceptionofrenamingtheExclusive(read/write)statetoDirtyExclusive(read/write).ThenewCleanExclusive(readonly)stateshouldbeaddedtothediagramalongwiththefollowingtransitions.■fromCleanExclusivetoCleanExclusiveintheeventofaCPUreadhitonthisblockoraCPUreadmissonaDirtyExclusiveblock■fromCleanExclusivetoSharedintheeventofaCPUreadmissonaSharedblockoronaCleanExclusiveblock■fromCleanExclusivetoSharedintheeventofareadmissonthebusforthisblock■fromCleanExclusivetoInvalidintheeventofawritemissonthebusforthisblock■fromCleanExclusivetoDirtyExclusiveintheeventofaCPUwritehitonthisblockoraCPUwritemiss■fromDirtyExclusivetoCleanExclusiveintheeventofaCPUreadmissonaDirtyExclusiveblock■fromInvalidtoCleanExclusiveintheeventofaCPUreadmissonaDirtyExclusiveblock■fromSharedtoCleanExclusiveintheeventofaCPUreadmissonaDirtyExclusiveblockSeveraltransitionsfromtheoriginalprotocolmustchangetoaccommodatetheexistenceoftheCleanExclusivestate.Thefollowingthreetransitionsarethosethatchange.■fromDirtyExclusivetoShared,thelabelchangestoCPUreadmissonaSharedblock■fromInvalidtoShared,thelabelchangestoCPUmissonaSharedblock■fromSharedtoShared,themisstransitionlabelchangestoCPUreadmissonaSharedblock5.23Anobviouscomplicationintroducedbyprovidingavalidbitperwordistheneedtomatchnotonlythetagoftheblockbutalsotheoffsetwithintheblockwhensnoopingthebus.Thisiseasy,involvingjustlookingatafewmorebits.Inaddi-tion,however,thecachemustbechangedtosupportwrite-backofpartialcacheblocks.Whenwritingbackablock,onlythosewordsthatarevalidshouldbewrit-tentomemorybecausethecontentsofinvalidwordsarenotnecessarilycoherentCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■57withthesystem.Finally,giventhatthestatemachineofFigure5.7isappliedateachcacheblock,theremustbeawaytoallowthisdiagramtoapplywhenstatecanbedifferentfromwordtowordwithinablock.Theeasiestwaytodothiswouldbetoprovidethestateinformationofthefigureforeachwordintheblock.Doingsowouldrequiremuchmorethanonevalidbitperword,though.Withoutreplica-tionofstateinformationtheonlysolutionistochangethecoherenceprotocolslightly.5.24a.Theinstructionexecutioncomponentwouldbesignificantlyspedupbecausetheout-of-orderexecutionandmultipleinstructionissueallowsthelatencyofthiscomponenttobeoverlapped.Thecacheaccesscomponentwouldbesim-ilarlyspedupduetooverlapwithotherinstructions,butsincecacheaccessestakelongerthanfunctionalunitlatencies,theywouldneedmoreinstructionstobeissuedinparalleltooverlaptheirentirelatency.Sothespeedupforthiscomponentwouldbelower.Thememoryaccesstimecomponentwouldalsobeimproved,butthespeedupherewouldbelowerthantheprevioustwocases.Becausethemem-orycompriseslocalandremotememoryaccessesandpossiblyothercache-to-cachetransfers,thelatenciesoftheseoperationsarelikelytobeveryhigh(100’sofprocessorcycles).The64-entryinstructionwindowinthisexampleisnotlikelytoallowenoughinstructionstooverlapwithsuchlonglatencies.Thereis,however,onecasewhenlargelatenciescanbeoverlapped:whentheyarehiddenunderotherlonglatencyoperations.Thisleadstoatechniquecalledmiss-clusteringthathasbeenthesubjectofsomecompileroptimiza-tions.Theother-stallcomponentwouldgenerallybeimprovedbecausetheymainlyconsistofresourcestalls,branchmispredictions,andthelike.Thesynchronizationcomponentifanywillnotbespedupmuch.b.MemorystalltimeandinstructionmissstalltimedominatetheexecutionforOLTP,moresothanfortheotherbenchmarks.Bothofthesecomponentsarenotverywelladdressedbyout-of-orderexecution.HencetheOLTPworkloadhaslowerspeedupcomparedtotheotherbenchmarkswithSystemB.5.25Becausefalsesharingoccurswhenboththedataobjectsizeissmallerthanthegranularityofcacheblockvalidbit(s)coverageandmorethanonedataobjectisstoredinthesamecacheblockframeinmemory,therearetwowaystopreventfalsesharing.Changingthecacheblocksizeortheamountofthecacheblockcov-eredbyagivenvalidbitarehardwarechangesandoutsidethescopeofthisexer-cise.However,theallocationofmemorylocationstodataobjectsisasoftwareissue.Thegoalistolocatedataobjectssothatonlyonetrulysharedobjectoccurspercacheblockframeinmemoryandthatnonon-sharedobjectsarelocatedinthesamecacheblockframeasanysharedobject.Ifthisisdone,thenevenwithjustasinglevalidbitpercacheblock,falsesharingisimpossible.Notethatshared,read-only-accessobjectscouldbecombinedinasinglecacheblockandnotcon-tributetothefalsesharingproblembecausesuchacacheblockcanbeheldbymanycachesandaccessedasneededwithoutaninvalidationstocauseunneces-sarycachemisses.Copyright©2012Elsevier,Inc.Allrightsreserved.
58■SolutionstoCaseStudiesandExercisesTotheextentthatshareddataobjectsareexplicitlyidentifiedintheprogramsourcecode,thenthecompilershould,withknowledgeofmemoryhierarchydetails,beabletoavoidplacingmorethanonesuchobjectinacacheblockframeinmemory.Ifsharedobjectsarenotdeclared,thenprogrammerdirectivesmayneedtobeaddedtotheprogram.Theremainderofthecacheblockframeshouldnotcontaindatathatwouldcausefalsesharingmisses.Thesuresolutionistopadwithblockwithnon-referencedlocations.Paddingacacheblockframecontainingashareddataobjectwithunusedmem-orylocationsmayleadtoratherinefficientuseofmemoryspace.Acacheblockmaycontainasharedobjectplusobjectsthatareread-onlyasatrade-offbetweenmemoryuseefficiencyandincurringsomefalse-sharingmisses.Thisoptimiza-tionalmostcertainlyrequiresprogrammeranalysistodetermineifitwouldbeworthwhile.Generally,carefulattentiontodatadistributionwithrespecttocachelinesandpartitioningthecomputationacrossprocessorsisneeded.5.26Theproblemillustratesthecomplexityofcachecoherenceprotocols.Inthiscase,thiscouldmeanthattheprocessorP1evictedthatcacheblockfromitscacheandimmediatelyrequestedtheblockinsubsequentinstructions.Giventhatthewrite-backmessageislongerthantherequestmessage,withnetworksthatallowout-of-orderrequests,thenewrequestcanarrivebeforethewritebackarrivesatthedirec-tory.Onesolutiontothisproblemwouldbetohavethedirectorywaitforthewritebackandthenrespondtotherequest.Alternatively,thedirectorycansendoutanegativeacknowledgment(NACK).Notethatthesesolutionsneedtobethoughtoutverycarefullysincetheyhavepotentialtoleadtodeadlocksbasedonthepartic-ularimplementationdetailsofthesystem.Formalmethodsareoftenusedtocheckforracesanddeadlocks.5.27Ifreplacementhintsareused,thentheCPUreplacingablockwouldsendahinttothehomedirectoryofthereplacedblock.SuchhintwouldleadthehomedirectorytoremovetheCPUfromthesharinglistfortheblock.Thatwouldsaveaninvali-datemessagewhentheblockistobewrittenbysomeotherCPU.Notethatwhilethereplacementhintmightreducethetotalprotocollatencyincurredwhenwritingablock,itdoesnotreducetheprotocoltraffic(hintsconsumeasmuchbandwidthasinvalidates).5.28a.Consideringfirstthestoragerequirementsfornodesthatarecachesunderthedirectorysubtree:Thedirectoryatanylevelwillhavetoallocateentriesforallthecacheblockscachedunderthatdirectory’ssubtree.Intheworstcase(alltheCPU’sunderthesubtreearenotsharinganyblocks),thedirectorywillhavetostoreasmanyentriesasthenumberofblocksofallthecachescoveredinthesubtree.Thatmeansthattherootdirectorymighthavetoallocateenoughentriestoreferencealltheblocksofallthecaches.Everymemoryblockcachedinadirectorywillrepresentedbyanentry,thek-bitvectorwillhaveabitspecifyingallthesubtreesthathaveacopyoftheblock.Forexample,forabinarytreeanentrymeansthatblockmiscachedunderbothbranchesofthetree.Tobemoreprecise,onebitpersubtreewouldCopyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■59Root(Level0)Directoryk-10Level1Level1DirectoryDirectoryLevelL-1DirectoryCPU0CPU1CPUk-1FigureS.36Tree-baseddirectoryhierarchy(k-arytreewithllevels).beadequateifonlythevalid/invalidstatesneedtoberecorded;howevertorecordwhetherablockismodifiedornot,morebitswouldbeneeded.Notethatnoentryisneededifablockisnotcachedunderthesubtree.Ifthecacheblockhasmbits(tag+index)thenandsstatebitsneedtobestoredperblock,andthecachecanholdbblocks,thenthedirectoriesatlevelL-1(lowestleveljustaboveCPU’s)willhavetoholdk×bentries.Eachentrywillhave(m+k×s)bits.ThuseachdirectoryatlevelL-1willhave(mkb+k2bs)bits.Atthenextlevelofthehierarchy,thedirectorieswillbektimesbigger.Thenumberofdirectoriesatleveliiski.Toconsidermemoryblockswithahomeinthesubtreecachedoutsidethesubtree.Thestoragerequirementsperdirectorywouldhavetobemodified.Calculationoutline:Notethatforsomedirectory(forexampletheonesatlevell-1)thenumberofpossiblehomenodesthatcanbecachedoutsidethesubtreeisequalto(b×(kl–x)),whereklisthetotalnumberofCPU’s,bisthenumberofblockspercacheandxisthenumberofCPU’sunderthedirectory’ssub-tree.Itshouldbenotedthattheextrastoragediminishesfordirectoriesinhigherlevelsofthetree(forexamplethedirectoryatlevel0doesnotrequireanysuchstoragesincealltheblockshaveahomeinthatdirec-tory’ssubtree).b.Simulation.Copyright©2012Elsevier,Inc.Allrightsreserved.
60■SolutionstoCaseStudiesandExercises5.29Testandsetcodeusingloadlinkedandstoreconditional.MOVR3,#1LLR2,0(R1)SCR3,0(R1)Typicallythiscodewouldbeputinaloopthatspinsuntila1isreturnedinR3.5.30Assumeacachelinethathasasynchronizationvariableandthedataguardedbythatsynchronizationvariableinthesamecacheline.Assumeatwoprocessorsys-temwithoneprocessorperformingmultiplewritesonthedataandtheotherpro-cessorspinningonthesynchronizationvariable.Withaninvalidateprotocol,falsesharingwillmeanthateveryaccesstothecachelineendsupbeingamissresultinginsignificantperformancepenalties.5.31Themonitorhastobeplaceatapointthroughwhichallmemoryaccessespass.Onesuitableplacewillbeinthememorycontrolleratsomepointwhereaccessesfromthe4coresconverge(sincetheaccessesareuncachedanyways).Themonitorwillusesomesortofacachewherethetagofeachvalidentryistheaddressaccessedbysomeload-linkedinstruction.Inthedatafieldoftheentry,thecorenumberthatproducedtheload-linkedaccess-whoseaddressisstoredinthetagfield-isstored.Thisishowthemonitorreactstothedifferentmemoryaccesses.■Readnotoriginatingfromaload-linkedinstruction:❍Bypassesthemonitorprogressestoreaddatafrommemory■Readoriginatingfromaload-linkedinstruction:❍Checksthecache,ifthereisanyentrywithwhoseaddressmatchesthereadaddressevenifthereisapartialaddressmatch(forexample,read[0:7]andread[4:11]overlapmatchinaddresses[4:7]),thematchingcacheentryisinvalidatedandanewentryiscreatedforthenewread(recordingthecorenumberthatitbelongsto).Ifthereisnomatchingentryinthecache,thenanewentryiscreated(ifthereisspaceinthecache).Ineithercasethereadprogressestomemoryandreturnsdatatooriginatingcore.■Writenotoriginatingfromastore-conditionalinstruction:❍Checksthecache,ifthereisanyentrywithwhoseaddressmatchesthewriteaddressevenifthereisapartialaddressmatch(forexample,read[0:7]andwrite[4:11]overlapmatchinaddresses[4:7]),thematchingcacheentryisinvalidated.Thewriteprogressestomemoryandwritesdatatotheintendedaddress.■Writeoriginatingfromastore-conditionalinstruction:❍Checksthecache,ifthereisanyentrywithwhoseaddressmatchesthewriteaddressevenifthereisapartialaddressmatch(forexample,read[0:7]andwrite[4:11]overlapmatchinaddresses[4:7]),thecorenumberinthecacheentryiscomparedtothecorethatoriginatedthewrite.Copyright©2012Elsevier,Inc.Allrightsreserved.
Chapter5Solutions■61Ifthecorenumbersarethesame,thenthematchingcacheentryisinvali-dated,thewriteproceedstomemoryandreturnsasuccesssignaltotheoriginatingcore.Inthatcase,weexpecttheaddressmatchtobeperfect–notpartial-asweexpectthatthesamecorewillnotissueload-linked/storeconditionalinstructionpairsthathaveoverlappingaddressranges.Ifthecorenumbersdiffer,thenthematchingcacheentryisinvalidated,thewriteisabortedandreturnsafailuresignaltotheoriginatingcore.Thiscasesignifiesthatsynchronizationvariablewascorruptedbyanothercoreorbysomeregularstoreoperation.5.32a.BecauseflagiswrittenonlyafterAiswritten,wewouldexpectCtobe2000,thevalueofA.b.Case1:IfthewritetoflagreachedP2fasterthanthewritetoA.Case2:IfthereadtoAwasfasterthanthereadtoflag.c.EnsurethatwritesbyP1arecarriedoutinprogramorderandthatmemoryoperationsexecuteatomicallywithrespecttoothermemoryoperations.Togetintuitiveresultsofsequentialconsistencyusingbarrierinstructions,abarrierneedtobeinsertedinP1betweenthewritetoAandthewritetoflag.5.33Inclusionstatesthateachhigherlevelofcachecontainsallthevaluespresentinthelowercachelevels,i.e.,ifablockisinL1thenitisalsoinL2.TheproblemstatesthatL2hasequalorhigherassociativitythanL1,bothuseLRU,andbothhavethesameblocksize.Whenamississervicedfrommemory,theblockisplacedintoallthecaches,i.e.,itisplacedinL1andL2.Also,ahitinL1isrecordedinL2intermsofupdatingLRUinformation.AnotherkeypropertyofLRUisthefollowing.LetAandBbothbesetswhoseelementsareorderedbytheirlatestuse.IfAisasubsetofBsuchthattheysharetheirmostrecentlyusedelements,thentheLRUelementofBmusteitherbetheLRUelementofAornotbeanelementofA.ThissimplystatesthattheLRUorderingisthesameregardlessifthereare10entriesor100.Letusassumethatwehaveablock,D,thatisinL1,butnotinL2.SinceDinitiallyhadtoberesidentinL2,itmusthavebeenevicted.AtthetimeofevictionDmusthavebeentheleastrecentlyusedblock.SinceanL2evictiontookplace,theprocessormusthaverequestedablocknotresidentinL1andobviouslynotinL2.ThenewblockfrommemorywasplacedinL2(causingtheeviction)andplacedinL1causingyetanothereviction.L1wouldhavepickedtheleastrecentlyusedblocktoevict.SinceweknowthatDisinL1,itmustbetheLRUentrysinceitwastheLRUentryinL2bytheargumentmadeinthepriorparagraph.ThismeansthatL1wouldhavehadtopickDtoevict.ThisresultsinDnotbeinginL1whichresultsinacontradictionfromwhatweassumed.IfanelementisinL1ithastobeinL2(inclusion)giventheproblem’sassumptionsaboutthecache.Copyright©2012Elsevier,Inc.Allrightsreserved.
62■SolutionstoCaseStudiesandExercises5.34Analyticalmodelscanbeusedtoderivehigh-levelinsightonthebehaviorofthesysteminaveryshorttime.Typically,thebiggestchallengeisindeterminingthevaluesoftheparameters.Inaddition,whiletheresultsfromananalyticalmodelcangiveagoodapproximationoftherelativetrendstoexpect,theremaybesignificanterrorsintheabsolutepredictions.Trace-drivensimulationstypicallyhavebetteraccuracythananalyticalmodels,butneedgreatertimetoproduceresults.Theadvantagesarethatthisapproachcanbefairlyaccuratewhenfocusingonspecificcomponentsofthesystem(e.g.,cachesystem,memorysystem,etc.).However,thismethoddoesnotmodeltheimpactofaggressiveprocessors(mispredictedpath)andmaynotmodeltheactualorderofaccesseswithreordering.Tracescanalsobeverylarge,oftentak-inggigabytesofstorage,anddeterminingsufficienttracelengthfortrustworthyresultsisimportant.Itisalsohardtogeneraterepresentativetracesfromoneclassofmachinesthatwillbevalidforalltheclassesofsimulatedmachines.Itisalsohardertomodelsynchronizationonthesesystemswithoutabstractingthesyn-chronizationinthetracestotheirhigh-levelprimitives.Execution-drivensimulationmodelsallthesystemcomponentsindetailandisconsequentlythemostaccurateofthethreeapproaches.However,itsspeedofsimulationismuchslowerthanthatoftheothermodels.Insomecases,theextradetailmaynotbenecessaryfortheparticulardesignparameterofinterest.5.35Onewaytodeviseamultiprocessor/clusterbenchmarkwhoseperformancegetsworseasprocessorsareadded:Createthebenchmarksuchthatallprocessorsupdatethesamevariableorsmallgroupofvariablescontinuallyafterverylittlecomputation.Foramultiprocessor,themissrateandthecontinuousinvalidatesinbetweentheaccessesmaycontributemoretotheexecutiontimethantheactualcomputation,andaddingmoreCPU’scouldslowtheoverallexecutiontime.Foraclusterorganizedasaringcommunicationcostsneededtoupdatethecom-monvariablescouldleadtoinverselinearspeedupbehaviorasmoreprocessorsareadded.Copyright©2012Elsevier,Inc.Allrightsreserved.
'
您可能关注的文档
- 观部分》人大_高鸿业_第四版_课后习题答案.pdf
- 《西方经济学》(微观部分)高鸿业第四版课后答案.doc
- 《西方经济学》-微观部分练习【有答案】.doc
- 《西方经济学》习题及答案.doc
- 《西方经济学》练习题库答案.doc
- 《西方经济学》编写组书后习题参考答案(大学期末复习资料).doc
- 《西方经济学导学》综合练习题参考答案.doc
- 《西方经济学练习册》参考答案.doc
- 《计学基础》习题及答案第四版.doc
- 《计算机图形学》第1-5章课后习题参考答案.doc
- 《计算机常用算法与程序设计案例教程》习题解答.doc
- 《计算机应用基础》习题册加答案.doc
- 《计算机应用基础》习题及答案.doc
- 《计算机应用基础》题库(二) 及答案分析.doc
- 《计算机理论知识》复习题及答案.doc
- 《计算机程序设计A》复习试题(答案).doc
- 《计算机算法基础》课后答案.docx
- 《计算机组成原理》_陆遥编著 课后习题参考答案.doc
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明