

- 680.72 KB
- 2022-04-22 13:51:31 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'中国科技论文在线http://www.paper.edu.cn一种基于片上网络的分布式容错方法设计实现**胡康,丁晓彤,任鹏举5(西安交通大学电子与信息工程学院,西安710049)摘要:随着多核处理器核心数量的增多,系统容量的扩大,在制造和运行过程中产生的故障将会增多,容错能力对于系统的可靠性将变得越发重要。而一个片上系统的正常工作,将会非常依赖于片上网络系统传输数据的可靠性。芯片的制造偏差和组件故障、多处理器系统芯10片集成不规则IP以及动态的电源门控都将导致片上网络中出现不规则拓扑结构。片上网络应当具备可以重新配置网络路由方式并将数据传输路径绕过无法正常工作的位置。本文中设计了一种用于路由计算的特定约束跳转配置方法,为了保证其健壮性,采用基于局部信息的通信方式,设计实现了分布式的路由器传输路径配置单元,并完成了该方法的硬件实现。关键词:片上系统;容错路由算法;分布式路由;FPGA15中图分类号:TN4DistributedFault-TolerantRouterConfigurationforNoCHUKang,DINGXiaotong,RENPengju(ElectronicandInformationEngineeringSchool,Xi"anJiaotongUniversity,Xi"an710049)20Abstract:Inthefuture,bythedevelopmentofsystemonchip(SoC),multi-coreisnecessarytodevelopintothecore.Withtheincreaseinthenumberofcores,thesystemcapacityexpansion,errorsinthemanufacturingprocessandtheprocessofrunningwillincrease.Faulttolerancewillbecomemoreimportant.Acomplexsystemofnormalworkwillbeverydependentonthereliabilityoftheon-chipnetworksystemtotransmitdata.Theon-chipnetworkmusthavetheabilitytore-configurethenetwork25routinganddataroutingpathsaroundthewrongplace.Inthispaper,wedesignajumpallocationmethodforthespecificconstraintsofroutingcalculation.Inordertoensureitsrobustness,adistributedroutertransmissionpathconfigurationunitisdesignedandimplementedbasedonthelocalinformationcommunicationmethod.Keywords:system-onchip;fault-tolerant;distributedrouting;FPGA300引言集成电路发展到今天,晶体管的尺寸不断缩小,使得芯片上可以构造超大规模,乃至更大规模的电路系统。在深亚微米集成电路制造工艺下,尺寸的变小使得工艺偏差或者电迁移[1]35等影响变得更加明显,容易导致性能参数的漂移,这些都有可能导致故障率的上升。芯片的制造偏差和组件故障、多处理器系统芯片集成不规则IP以及动态的电源门控都将导致片上网络中出现不规则拓扑结构,这就要求具备更加鲁棒的片上网络传输能力,可以在运行过程中配置网络路由,从而适应拓扑结构的变化。常用方法大致可以分为三类。1)采用冗余单元:冗余单元在对面积要求不苛刻的时候可以使用,但它会增加额外的40资源消耗。随着核心数目上升,这些备用单元的数量也需要增加,带来了不可忽视的硬件开销。2)容错路由算法:片上网络的拓扑结构多种多样,不同拓扑结构下的路径多样性也很丰富,为了旁路失效单元就可以选择绕开不含错误组件的路径进行通讯传输。这种作者简介:胡康(1989-),男,研究生在读,主要研究方向:片上网络通信联系人:任鹏举(1984-),副教授,博导,主要研究方向:人工智能.E-mail:pengjuren@xjtu.edu.cn-1-
中国科技论文在线http://www.paper.edu.cn方式需要有效的路径计算,并在数据产生的源节点将路径信息加载到消息头部,来45引导数据包的正确传输。3)重配置:将路由表重新配置也可以达到容错的目的。这种方法的特点是额外硬件消耗少,且方法灵活,然而要应对不规则的网络结构则需要额外的配置步骤。本文提出了一种路由跳转约束配置方法,设计了一种相应的分布式实现方法,在新的路由方式中可以有效避免死锁,同时不会引起网络间断,并完成了该方法的硬件实现。50文章的结构安排如下:第1节给出了割点检测的方法,并采用硬件实现该方法;第2节描述了容错路由的配置要求以及其硬件实现方式;第3节对该方案进行了实验验证,分析了验证结果;第4节对研究内容进行总结。1割点检测当一个网络中出现无法绕通的错误节点或者需要关断的电源门控节点,这个网络将有非55常大的可能变成一个非规则的拓扑结构,而在非规则的拓扑结构中寻找路由路径的过程常常会在网络中产生“死锁”(Deadlock)的潜在威胁,为了重新配置网路的同时不产生死锁,就需要有一种重配置算法来保证按照这种方法配置出的路由表中不会存在死锁。如图1描述了[2]两种TurnModel模型无法连通的缺陷模型,为了包容在片上网络中的各种可能出现的节点错误,必须有一种算法既可以保证每个节点都能够互相访问,而且避免网络中可能出现死60锁的所有情况。012012345345678678(a)WestFirstTurns(b)NorthLastTurns图1TurnModel无法连通的缺陷网络Fig.1ThedefectivenetworksunabletoconnectbyTurnModel割点是本文中分布式容错方法中的一个重要概念,片上网络路由问题可以使用图算法建65立模型解决,在图算法中有几个相关的简单的定义描述如下:定义一个图G=G(R,L),R代表图G里的所有节点集合,L代表图中的所有连线集合,被称为边。在网络中ri∈R表示一个编号为i的路由节点,li,j表示一个从节点i到节点j的边,同时这条边对应一个物理线路。当从节点i到节点j有一条以上的路径可以连通时称为i与j是可连通的,当一个图中的所有节点互相之间都是可连通的,则称这个图为连通图。70当把一个拓扑结构使用深度优先搜索遍历之后,所有不在树上的边被称为返回边。深度优先树的返回边都是从一个节点连接到它的祖先或者连接到它的子孙,不会连接到其他深度优先树的分支。1.1分布式割点检测在传统的方法中,需要标记割点就需要知道整个网路的结构信息,然后在某一个专用计75算节点以离线的方式计算出割点信息。然而,随着片上网络规模的扩大,这种方法会遇到可扩展性的问题。采用分布式在线配置的方式,可以有效的提高其可扩展性。本文提出一种分-2-
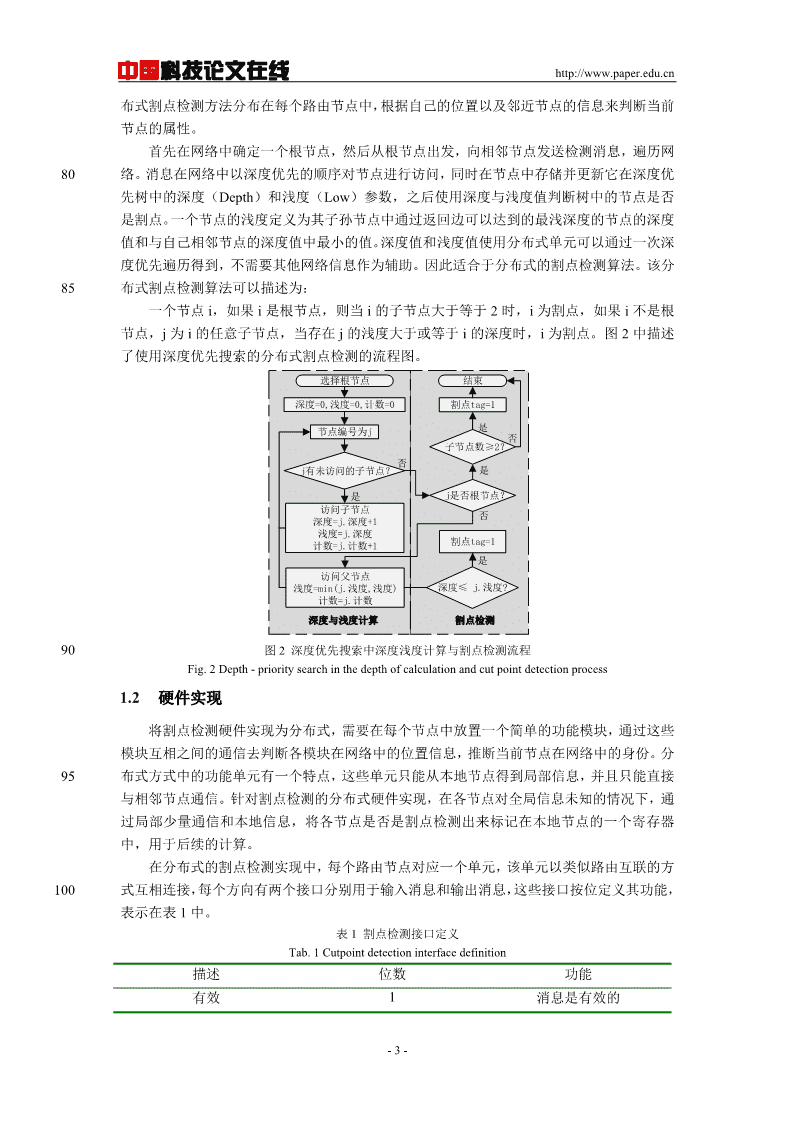
中国科技论文在线http://www.paper.edu.cn布式割点检测方法分布在每个路由节点中,根据自己的位置以及邻近节点的信息来判断当前节点的属性。首先在网络中确定一个根节点,然后从根节点出发,向相邻节点发送检测消息,遍历网80络。消息在网络中以深度优先的顺序对节点进行访问,同时在节点中存储并更新它在深度优先树中的深度(Depth)和浅度(Low)参数,之后使用深度与浅度值判断树中的节点是否是割点。一个节点的浅度定义为其子孙节点中通过返回边可以达到的最浅深度的节点的深度值和与自己相邻节点的深度值中最小的值。深度值和浅度值使用分布式单元可以通过一次深度优先遍历得到,不需要其他网络信息作为辅助。因此适合于分布式的割点检测算法。该分85布式割点检测算法可以描述为:一个节点i,如果i是根节点,则当i的子节点大于等于2时,i为割点,如果i不是根节点,j为i的任意子节点,当存在j的浅度大于或等于i的深度时,i为割点。图2中描述了使用深度优先搜索的分布式割点检测的流程图。选择根节点结束深度=0,浅度=0,计数=0割点tag=1节点编号为j是否子节点数≥2?否j有未访问的子节点?是是j是否根节点?访问子节点否深度=j.深度+1浅度=j.深度割点tag=1计数=j.计数+1是访问父节点浅度=min(j.浅度,浅度)深度≤j.浅度?计数=j.计数深度与浅度计算割点检测90图2深度优先搜索中深度浅度计算与割点检测流程Fig.2Depth-prioritysearchinthedepthofcalculationandcutpointdetectionprocess1.2硬件实现将割点检测硬件实现为分布式,需要在每个节点中放置一个简单的功能模块,通过这些模块互相之间的通信去判断各模块在网络中的位置信息,推断当前节点在网络中的身份。分95布式方式中的功能单元有一个特点,这些单元只能从本地节点得到局部信息,并且只能直接与相邻节点通信。针对割点检测的分布式硬件实现,在各节点对全局信息未知的情况下,通过局部少量通信和本地信息,将各节点是否是割点检测出来标记在本地节点的一个寄存器中,用于后续的计算。在分布式的割点检测实现中,每个路由节点对应一个单元,该单元以类似路由互联的方100式互相连接,每个方向有两个接口分别用于输入消息和输出消息,这些接口按位定义其功能,表示在表1中。表1割点检测接口定义Tab.1Cutpointdetectioninterfacedefinition描述位数功能有效1消息是有效的-3-
中国科技论文在线http://www.paper.edu.cn端口2注出消息的端口索引D/Llog2N深度/浅度传输计数log2N节点计数传输EWSN交叉组合有效端口D/L计数发现新Nbit节点?2深度EWSN0原值父节点tag+11Nbitlog浅度1选择4:12>?0原值选择4:1子节点tag割点有多个?EWSN>?11bitlog4:1100AE.(D/L)A≤B?选择W.(D/L)根B4:1S.(D/L)深度浅度N.(D/L)是叶节点或遍历终点有未访问邻节点?10父节点tag1是父节点消息EWSN+1即将遍历节点0按优先级选择编码非子节点的邻节点1110父节点tag00有效端口D/L计数交叉EWSN组合105图3分布式割点检测单元结构示意图Fig.3StructureofDistributedFracturePointDetectionUnit图3为分布式割点检测单元的设计框图。可以看到在设计中将所有端口的输入经过一个交叉组合单元组合成四组数据,其中信息有效位为4bit,端口位为4x2bit,D/L位为4xlog2N位,计数位为4xlog2N位。深度值会在深度优先遍历的过程中,向子节点遍历时被更新,这110时相当于发现了深度优先树中新的节点,这时将传入的深度值增加1存入当前节点的深度值寄存器,在当前节点向其子节点遍历的同时向子节点发送。父节点tag和子节点tag在遍历时由遍历方向和出入口方向等信息在遍历的同时标记出来。是否发现新节点由有效消息方向,消息发出端口索引号和父节点tag经过组合逻辑计算得出。在Mesh网络中算法为,当一个端口收到目标为相反端口的消息时,认为此消息为树上遍历消息,并发现节点,如果已115经有父节点,则保持深度值。2容错路由配置由Turn-Model避免死锁的方法,可以总结出一种统一的死锁避免方法,即通过解开所有网络中可能出现的环形跳转,使网络中不会出现任何资源释放和资源申请以环形形式出现。然而不是所有的解开环形的方式都适用于网络,例如图1中的几种情况,虽然死锁不可能出120现,但在缺陷网络中的连通性并不能保证。所以,在一个会出现随机节点失效或关断的网络中,为了保证不出现死锁,而又要保证连通性,就需要有一种路由表配置满足该要求。2.1分布式容错路由表配置算法根据Dally和Seitz的研究,当一个路由算法中,当所有节点可以以不同大小的数字标记节点,并且路由算法可以保证路由路径上节点标记数字恒增或恒减小,则路由算法是无死[3]125锁的。为了达到路由上的无死锁,和连通子网络的连通性,就需要一种方法配置路由表达[4]到连通和无环两种特性。基于Levitin等人提出的一种使用禁止最小量跳转解环的方法,本文章中设计了一种适用于2D-Mesh网络结构的分布式的路由表配置,达到最小禁用和无-4-
中国科技论文在线http://www.paper.edu.cn死锁,且保证连通性的方法。这个算法描述为:13001.将所有跳转标记为允许;02.在网络中标记所有割点;03.在网络中选择具有最少相邻节点且不是割点的节点X;04.For(i属于X的邻节点):05.For(j属于X的邻节点):13506.添加所有跳转(i,X,j)到禁止跳转集合;07.End08.End09.将节点X从配置过程中删除;10.回到步骤02;140在算法中,为了保证无死锁,在删除跳转时将节点也从配置步骤中去除,这样去除节点的顺序和配置的方式导致在路由配置完成后,跳转的时候不可能从一个后配置的节点跳到一个先配置的节点再跳到一个后配置的节点,因为这样的跳转已经被禁止掉了。而在一个所有节点都有不同编号的任何环中,必然有一个节点的编号是最小的,而每次经过配置移去节点X后形成的网络都相当于移去了所有包含X的环路。这样在配置完成之后,相当于移去了145包含所有被配置过节点的环路,而网络中所有的节点都被配置过,也就是网络中所有的环路都被移除。为了保证连通性,配置的时候会排除掉割点,因为对于割点来说,如果禁止掉了(i,X,j)的跳转,这个网络将因此变得不连通。而排除掉割点会使得每一次配置掉一个节点O,这个节点与剩余网络的连接(O,i,j)和(i,j,O)并未被禁止,且由于O已经从配置过150程中被删掉,(O,i,j)和(i,j,O)也不会在未来的配置中被删掉,因此总是能保证每个节点与网络的连通性。在图4中展示了一个网络的重配置过程,割点用黑色标出。0121212124567456756767abababab012(a)(b)(c)(d)45672677abab67abab(i)ab(e)(f)(g)(h)图4一次路由配置过程Fig.4Onerouteconfigurationprocess155图中(a)的网络为原始网络,最少相邻节点数2的节点有0,4,5,2,7,a,b七个,其中2为割点,在(a)中选择了节点0为配置节点,禁止掉(4,0,1)和(1,0,4)这两个跳转。在(b),(c),(d),(e)中分别选择只有一个邻节点的节点4,5,1,2配置,由于只有一个邻节点,所以不存在(i,X,j)这种形式的跳转,因此直接删除进入下一个配置阶段。在(f)阶段配置剩余网络中所有节点的邻点数都为2,所以任意选择节160点6,禁止跳转(a,6,7)和跳转(7,6,a)。在(g)中对节点7配置,在(h)中对节点b做同样的配置。配置完成的网络展示在图4(i)中,整个网络中禁止了节点0的相邻-5-
中国科技论文在线http://www.paper.edu.cn节点经过节点0互相的通信,以及节点6的相邻节点a和7之间经过节点6互相的通信。在这些通信形式禁止之后,网络中将不存在死锁。配置后的最大连通性表示在图5中。全相连网络百分比平均不连通节点数失效单元数目165图5失效单元变化影响连通性Fig.5Failureunitchangesaffectconnectivity由于使用的方法保证了连通性,不连通的节点都是由于失效资源导致的无法连通节点,[5]配置本身保证了连通性,因此相比uDirec,在连通性上有一定优势,而uDirec方法包括了配置与路由方法。1702.2硬件实现本文中针对2D-Mesh网络的特点,对路由配置过程进行修改,使之适应于2D-Mesh网络的硬件实现。2D-Mesh网络有一个性质,这个性质对路由配置算法的实现有着重要的意义。性质:在2D-Mesh网络中,无论是否有失效节点或边,当不存在叶节点时,各节点中邻节点数的最小值为2。175描述:首先,显然如果不存在失效节点或边,那么2D-Mesh网络角落的节点拥有最少的邻节点数2。在一个有失效节点或失效边的网络中,如果不存在叶节点,假设网络中不存在邻节点数为2的点,那么所有节点都有3个或者4个邻节点,图6中展示了所有这两种节点互相连接的可能性。(a)(b)(c)(d)(e)(f)(g)180图6相邻节点为3和4的节点组合Fig.6Nodeswith3and4adjacentnodes图6中(a)为两种节点类型,这两种节点总是有一对边指向相反的方向。(b)为两个空悬边为4的节点相连,(c,d,e)为两个空悬边为3的节点连接,(f,g)为一个空悬边为3和一个空悬边为4的节点连接。与一个节点相连的所有有效边必须有另一个节点连在185上面,否则会成为空悬的边,空悬的边被认为失效,因为不能进行任何通信。针对这两种节点,在一个维度上消除空悬边的唯一办法就是在该维度上连接一个边数为3的节点并使用反方向无悬空边的边连接。这些情况为图中的(c),(e),和(g),这些时候将会在另一个维度引入新的空悬边对。显然使用这两种节点构建网络时,使用4个边的节点总是会引入-6-
中国科技论文在线http://www.paper.edu.cn新的悬空边。同样使用3个边的节点的相对边与其他节点配对在同一个维度上总会引入新的190悬空边,在(d)和(f)中可以看到这种情况。所以一个只存在4边与3边的2D-Mesh网络是不存在的,在没有叶节点的时候,即不存在边数为1的节点时,必然存在边数为2的节点。当删去叶节点后必然会存在邻节点数为2的点,那么出于硬件实现考虑,就可以将最小邻节点数设为2,用于后续配置2D-Mesh网络的计算。由此,针对2D-Mesh型网络设计的一个流程展示在图7中。当前节点=选根节点完成移除否是当前为叶节点?邻节点数>0?是否DFS重配置流程遍历下一节点配置并从流程移除并访问某个邻节点是是根节点?邻节点数=2?否否否叶节点?搜索非割点是移除割点检测流程删叶节点配置路由表195图7路由重配置流程Fig.7Routereconfigurationprocess在重配置过程中,与前两次流程相似,也要进行深度优先遍历,在遍历的过程中寻找出一个非割点且只有两个邻节点的节点作为配置目标,一般而言,有可能在网络中存在多个满200足配置要求的节点,选择相邻节点中度数只和最大的节点进行配置往往可以带来更好的性能,然而这必然引入额外的配置时间,因此在硬件实现上可以简化为配置遇到的第一个符合配置条件的节点,遇到该节点后,将目前配置网络中与该节点相邻的两个节点之间的通信标识出来,作为配置通信的掩码。这些信息可以用于节点路由或者源路由方式,在使用源路由方法的时候,需要将这些信息分布到网络中的每个节点。图8中是配置路由表单元的主要功205能部分框图,其中对应的端口数据位功能的定义表示在表2中,图中相同粗体字单元表示同一个的单元。表2路由表配置单元相关接口定义Tab.2Routingtablehiverelatedinterfacedefinition描述位数功能有效1消息是有效的(同表4-1)删去1在配置流程中删去节点配置通知1节点被配置根1根节点通知叶邻点/叶节点1邻节点是叶节点/节点是叶节点访问控制1记录通过返回边访问的节点-7-
中国科技论文在线http://www.paper.edu.cnEWSN交叉组合有效删去配置通知根叶邻点访问控制4辅助信息4"b1开始44:1104:1遍历是根节点缩减掩码=stage0?5:1未删邻点阶段0缩减掩码按优先级选择4"b0组合逻正向遍历014辑:配置是根节点2:110控制信息此节点?邻点数量0未删邻点是割点阶段返回01组合逻候选访问节点4"b0是根节点辑:删除10阶段01是叶节点控制信息此节点?是割点配置禁止的跳转4:1已配置访问控制判断叶节点有效删去配置通知根叶节点访问控制交叉EWSN组合210图8重配置单元硬件实现Fig.8Reconfigurationunithardwareimplementation图中的这些逻辑块同样分布于每个路由器中,形成分布式的控制单元,这些单元同样将四个方向的信号交叉并按功能组合成几组信号,用于参与网络遍历,辅助网络遍历和读写路由表配置寄存器。其中每个端口的“有效”位与图8中的“有效”位的意义相同,表示进入的消215息有效和发出有效消息,输入端“删去”位接当前单元周围四个单元各自的输出端“删去”位,当一个单元a被从配置中删除,则通知其周围的单元bi,周围的单元收到此信息之后,将此信息反相之后作为配置过程中删除节点的掩码经过与门和当前节点bi中记录的未删邻节点按位与,掩去删除的节点即可以得到更新后的未删邻节点。当配置禁止跳转中存在真值时表示当前节点a已被配置,需要从配置流程中删除,意味220着不参与剩余网络的配置,这就需要向其所有邻节点发送信息,通知删去本节点,其他节点bi则执行前一段所述操作。图中的“缩减掩码”同样用于掩去邻节点中不必要再配置的节点,主要用于从网络中掩去所有的叶节点,这一动作将发生在配置流程的第一部中。叶节点在本地接收相邻节点是否被删除的信息,用于判断自己当前周围的相连节点数,当节点数变成1的时候,此节点即被判断为叶节点。叶节点也会影响未删邻节点的更新,从而维持通信范围225在当前需要配置的节点内。配置包括三个阶段,即删除叶节点阶段,割点检测阶段和重配置路由阶段。这三个阶段任务不同,在设计中使用stage寄存器保存节点跟踪阶段。在深度优先遍历返回阶段,信息会通过一个“返回置位”信号将树信息重置,等待下一阶段遍历,并改变“阶段”寄存器值,节点通过阶段寄存器判断要做的工作。2303实验结果使用设计中的方法生成的路由跳转配置会用来在计算路由时限制路由跳转,通过此方法得到的路由的性能,使用Uniform-Random的通信模型测试得到的吞吐率展示在图9中。-8-
中国科技论文在线http://www.paper.edu.cn接收速率(flits/cycle)注入速率(flits/cycle)图964节点2D-Mesh网络中不同失效率下的吞吐率235Fig.9Thethroughputof64-node2D-Meshnetworkswithdifferentfailurerates图10显示了不同注入速率下64节点的2D-Mesh网络的平均延时。可以看到在失效率20%的时候,平均延时的增加趋势变快。这也是由于网络中失效节点增加导致的网络阻塞造成的。平均延时(cycles)注入速率(flits/cycle)240图1064节点2D-Mesh网络中不同失效率下的平均延时Fig.10Theaveragedelayinthe64-node2D-Meshnetworkwithdifferentfailurerates图11中为设计中算法与一些近年来算法的比较,其中DOS-R为使用了本文中路由配置[6]方法的算法。对比了Fick的Fdate09,以及Parikh等人的uDirec。由于使用的配置方法是分布式的,在实现时具体的路由路径采用最短路径。图中可以看到这几种路径计算方法在低245失效数的时候,具有相似的性能,当失效数目增大的时候,使用了DOS-R的平均延时增加[7]缓慢于其他两种算法。Benchmark来源于分布式x86多核仿真器Graphite。-9-
中国科技论文在线http://www.paper.edu.cn平均延时(cycles)(a)失效数目5平均延时(cycles)平均延时(cycles)(b)失效数目10(c)失效数目20图11平均延时比较Fig.11Averagedelaycomparison250此配置模块通过进行深度优先遍历来配置网络,而遍历的过程所需要的时间为o(N),其中N为网络中节点的个数。每次配置迭代都会删掉一个节点,则配置完成所有节点,理论上需要o(N2)的时间。在图12中的是一个64节点网络中需要进行配置的周期数,当节点数不大,即节点数与失效数在同一个量级时,随着失效数目配置时间很快减小,因为整个网络的规模随着失效率的增加下降很快。配置时间(cycles)失效数目255图1264节点网络失效数目与配置时间Fig.1264nodenetworkfailurenumberandconfigurationtime当网络规模变大时,节点失效数量对配置时间的影响将减小,这从图13中256节点网络的配置时间可以看出来。对比图12和图13中的零失效配置时间也可以看出来,配置时间260与节点数的平方成正比例关系。-10-
中国科技论文在线http://www.paper.edu.cn配置时间(cycles)失效数目图13256节点网络失效数目与配置时间Fig.13256nodenetworkfailurenumberandconfigurationtime数据对虚拟通道的读写,通过交叉开关和进入路由输入输出寄存器等行为都会产生功265耗。而功耗与链路的使用率相关密切,其已经广泛用于网络能耗分析过程中。图14显示了一个8x8的网络在使用了采用此配置方法的路由算法后在网络中随机传输模型下的路由能耗分布,颜色越红表示能耗越高。在图中能耗为0的节点为失效节点,可以看到网络中失效率越高,所造成的负载不平衡也会越严重。此能耗分布图可以用来参考判断各节点路由器的拥堵情况,路由器中器件开关频率越高表示越拥堵,同时能耗也就相对越高。(a)10%失效率(b)20%失效率(c)30%失效率(d)40%失效率270图14各种失效率下的能耗空间分布示意图Fig.14Thespatialdistributionofenergyconsumptionundervariousfailurerates作为一个分布式的容错单元,其数量是随着网络中的节点数量而变化的,由于每个节点都会配备一个相同的单元,这样,单元的占用资源情况就变得比较关键。设计中的配置单元275互相之间通信的模式与网络中节点之间的互联存在对应关系,因此相当于充分利用了网络本身隐含的关于结构的信息,在本地节点记录的数据更少,因此占用资源较小。为了比较资源情况,表3和表4中分别采用适应于8x8和16x16的Mesh网络的配置单元综合后与相应的一个适用于同样规模网络的参考路由器对资源消耗进行对比。-11-
中国科技论文在线http://www.paper.edu.cn表3FPGA实现资源280Tab.3FPGAimplementationresources规模路由器配置单元LUTsRegsLUTsRegs8x86252206820715316x1666142108236177在FGPA的实现时使用XilinxXC7V2000TFLG1925型号的FPGA,在资源报告中可以看到在64节点网络中每个配置单元的LUT数量占到参考路由器的3.3%,Reg数量占用7.4%,256节点网络中LUT占用3.6%,Reg数量占8.4%。由于路由器和配置单元的verilog写法并未对FPGA进行优化,可以看出来由于FPGA资源的粗粒度,导致更小单元所占用285的资源偏大,以致于配置单元占用路由器占比高于ASIC综合得出的结果。表4ASIC实现资源Tab.4ASICimplementationresources规模路由器配置单元面积(um2)静态功耗(uW)面积(um2)静态功耗(uW)8x8215085480022095816x162294015465348793在ASIC实现中使用TSMC65nm工艺库,64节点网络中每个配置单元的面积占用到参考路由器面积的1%,漏功耗为参考路由器的1.2%,在256节点网络中面积占用路由面积2901.5%,静态功耗为参考路由器的1.7%。在以往的重配置方法的实现中,重配置面积占用路[8]由面积较小的单元包括Immunet,Vicis,Ariadne和uDirec,分别为6%,1.5%,2%和0.34%。在对比中使用参考路由器的配置类似,可以看出,本文中的配置方法的硬件开销比较低。4结论本文研究了一种用于配置网络的无死锁最小禁止跳转的方法,通过分析与研究,针对这295种方法,设计了一种适合于分布式实现的硬件结构,并验证了其正确性。网络可以将这种结构的单元搭配在每一个路由器中并互相连接,从而形成一个高度健壮的可重配置系统,使得网络中任何一个节点的损坏或者关闭都不会影响到重配置功能的完整性。之后分析了此配置模型的连通性,以及使用此配置模型的网络的吞吐率和延迟特性,并给出了此重配置单元工作所需的时间,以及网络的功耗分布图。结果显示此配置模型下的网络会达到最大的连通性,300和良好的性能。之后分析了分布式配置单元的资源消耗,显示在对比一个参考路由器的时候,此配置单元达到了比较低的资源占用。[参考文献](References)[1]AisoposK,ChenCHO,PehLS.Enablingsystem-levelmodelingofvariation-inducedfaultsin305networks-on-chips[C].Proceedingsofthe48thDesignAutomationConference,ACM,2011:930-935[2]GlassCJ,NiLM.Theturnmodelforadaptiverouting[C]//The,InternationalSymposiumonComputerArchitecture,1992.Proceedings,IEEE,1992:278-287[3]AustinT,BertaccoV,MahlkeS,etal.Reliablesystemsonunreliablefabrics[J].Design&TestofComputers,IEEE,2008,25(4):322-332310[4]DallyWJ,SeitzCL.Deadlock-freemessageroutinginmultiprocessorinterconnectionnetworks[J].Computers,IEEETransactionson,1987,100(5):547-553[5]ParikhR,BertaccoV.uDIREC:unifieddiagnosisandreconfigurationforfrugalbypassofNoCfaults[C].-12-
中国科技论文在线http://www.paper.edu.cnProceedingsofthe46thAnnualIEEE/ACMInternationalSYmposiumonMicroarchitecture,ACM,2013L148-159[6]FickD,DeOrioA,HuJ,etal.Vicis:areliablenetworkforunreliablesilicon[C].Proceedingsofthe46th315AnnualDesignAutomationConference,ACM,2009:812-817[7]MillerJE,KastureH,KurianG,etal.Graphite:Adistributedparallelsimulatorformulticores[C].HighPerformanceComputerArchitecture,IEEE16thInternationalSymposiumon,IEEE,2010:1-12[8]BahrebarP,StroobandtD.AdaptiveandReconfigurableFault-tolerantRoutingMethodfor2DNetworks-on-chip[C]//InternationalConferenceonReconfigurableComputingandFpgas.IEEE,2015:1-8320-13-'
您可能关注的文档
- 精选研究生入党申请书1500字.doc
- 航运管理毕业论文题目精选推荐.doc
- 计算机基层实训心得体会.doc
- 运动会加油口号范文4篇.doc
- 酒店餐饮国庆节营销活动方案.doc
- 银行管理培训心得体会范文.doc
- 预备党员转正决议例文.doc
- 高中阶段教育发展统计公报范文.doc
- 高级党课心得体会2500字.doc
- 基于修正KMV模型商业银行客户信贷风险测度.pdf
- 基于多范式建模与仿真的电动汽车充换电站优化配置研究.pdf
- 基于稳定性控制的自适应MANET分簇策略.pdf
- 用于改善生物学性质的钛表面含锶海藻酸钠涂层的研究.pdf
- 网络虚拟团队信任影响因素和模型研究.pdf
- 遗传算法在化工精馏中的运用.pdf
- 高压缩比天然气发动机性能研究.pdf
- GB 12337-2014 钢制球形储罐 标准释义及算例.pdf
- GB 19147-2016 车用柴油.pdf
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明