

- 1.84 MB
- 2022-04-22 11:26:14 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'《应用回归分析》部分课后习题答案第一章回归分析概述1.1变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。1.2回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。区别有a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。b.相关分析中所涉及的变量y与变量x全是随机变量。而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。1.4线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。2.等方差及不相关的假定条件为{E(εi)=0i=1,2….Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。4.样本容量的个数要多于解释变量的个数,即n>p.1.5回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。应注意的问题有:在选择变量时要注意与一些专门领域的专家合作,不要认为一个回归模型所涉及的变量越多越好,回归变量的确定工作并不能一次完成,需要反复试算,最终找出最合适的一些变量。40
1.6收集,整理数据包括哪些内容?答;常用的样本数据分为时间序列数据和横截面数据,因而数据收集的方法主要有按时间顺序统计数据和在同一时间截面上统计数据,在数据的收集中,样本容量的多少一般要与设置的解释变量数目相配套。而数据的整理不仅要把一些变量数据进行折算差分甚至把数据对数化,标准化等有时还需注意剔除个别特别大或特别小的“野值”。1.7构造回归理论模型的基本依据是什么?答:选择模型的数学形式的主要依据是经济行为理论,根据变量的样本数据作出解释变量与被解释变量之间关系的散点图,并将由散点图显示的变量间的函数关系作为理论模型的数学形式。对同一问题我们可以采用不同的形式进行计算机模拟,对不同的模拟结果,选择较好的一个作为理论模型。1.8为什么要对回归模型进行检验?答:我们建立回归模型的目的是为了应用它来研究经济问题,但如果马上就用这个模型去预测,控制,分析,显然是不够慎重的,所以我们必须通过检验才能确定这个模型是否真正揭示了被解释变量和解释变量之间的关系。1.9回归模型有那几个方面的应用?答:回归模型的应用方面主要有:经济变量的因素分析和进行经济预测。1.10为什么强调运用回归分析研究经济问题要定性分析和定量分析相结合?答:在回归模型的运用中,我们还强调定性分析和定量分析相结合。这是因为数理统计方法只是从事物外在的数量表面上去研究问题,不涉及事物质的规定性,单纯的表面上的数量关系是否反映事物的本质?这本质究竟如何?必须依靠专门的学科研究才能下定论,所以,在经济问题的研究中,我们不能仅凭样本数据估计的结果就不加分析地说长道短,必须把参数估计的结果和具体经济问题以及现实情况紧密结合,这样才能保证回归模型在经济问题研究中的正确应用。40
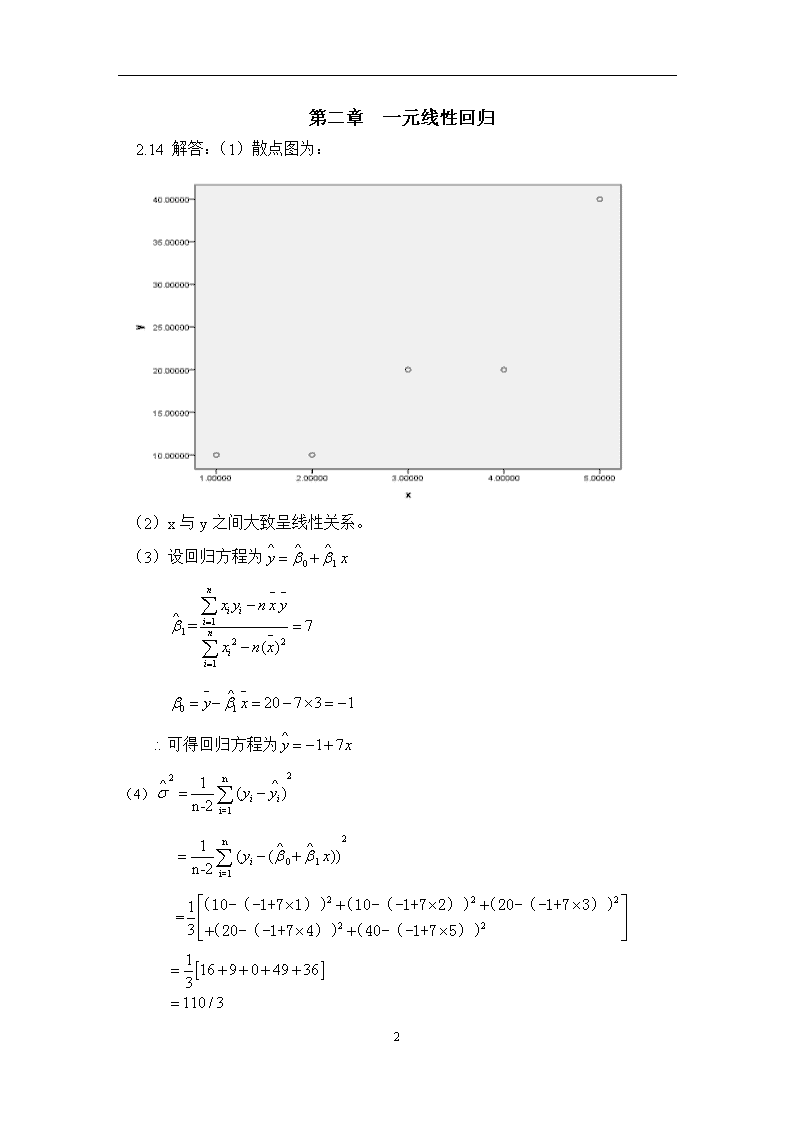
第二章一元线性回归2.14解答:(1)散点图为:(2)x与y之间大致呈线性关系。(3)设回归方程为=(4)=40
(5)由于服从自由度为n-2的t分布。因而也即:=可得即为:(2.49,11.5)服从自由度为n-2的t分布。因而即可得(6)x与y的决定系数40
(7)ANOVAx平方和df均方F显著性组间(组合)9.00024.5009.000.100线性项加权的8.16718.16716.333.056偏差.8331.8331.667.326组内1.0002.500总数10.0004由于,拒绝,说明回归方程显著,x与y有显著的线性关系。(8)其中接受原假设认为显著不为0,因变量y对自变量x的一元线性回归成立。(9)相关系数=小于表中的相应值同时大于表中的相应值,x与y有显著的线性关系.(10)序号111064221013-33320200442027-75540346残差图为:40
从图上看,残差是围绕e=0随机波动,从而模型的基本假定是满足的。(11)当广告费=4.2万元时,销售收入,即(17.1,39.7)2.15解答:(1)散点图为:40
(2)x与y之间大致呈线性关系。(3)设回归方程为=(4)=0.23050.4801(5)由于服从自由度为n-2的t分布。因而也即:=可得即为:(0.0028,0.0044)40
服从自由度为n-2的t分布。因而即可得(6)x与y的决定系数=0.908(7)ANOVAx平方和df均方F显著性组间(组合)1231497.5007175928.2145.302.168线性项加权的1168713.03611168713.03635.222.027偏差62784.464610464.077.315.885组内66362.500233181.250总数1297860.0009由于,拒绝,说明回归方程显著,x与y有显著的线性关系。(8)其中40
接受原假设认为显著不为0,因变量y对自变量x的一元线性回归成立。(9)相关系数=小于表中的相应值同时大于表中的相应值,x与y有显著的线性关系.(10)序号18253.53.07680.4232221510.88080.11923107043.95880.0412455022.0868-0.0868548011.8348-0.8348692033.4188-0.4188713504.54.9688-0.466883251.51.27680.2232967032.51880.481210121554.48080.5192从图上看,残差是围绕e=0随机波动,从而模型的基本假定是满足的。(11)(12),即为(2.7,4.7)近似置信区间为:,即(2.74,4.66)40
(13)可得置信水平为为,即为(3.33,4.07).2.16(1)散点图为:可以用直线回归描述y与x之间的关系.(2)回归方程为:(3)40
从图上可看出,检验误差项服从正态分布。40
第三章多元线性回归3.11解:(1)用SPSS算出y,x1,x2,x3相关系数矩阵:相关性yx1x2x3Pearson相关性y1.000.556.731.724x1.5561.000.113.398x2.731.1131.000.547x3.724.398.5471.000y..048.008.009x1.048..378.127x2.008.378..051x3.009.127.051.Ny10101010x110101010x210101010x310101010所以=系数a模型非标准化系数标准系数tSig.B的95.0%置信区间相关性共线性统计量B标准误差试用版下限上限零阶偏部分容差VIF1(常量)-348.280176.459-1.974.096-780.06083.500x13.7541.933.3851.942.100-.9778.485.556.621.350.8251.211x27.1012.880.5352.465.049.05314.149.731.709.444.6871.455x312.44710.569.2771.178.284-13.41538.310.724.433.212.5861.708a.因变量:y(2)所以三元线性回归方程为模型汇总40
模型RR方调整R方标准估计的误差更改统计量R方更改F更改df1df2Sig.F更改1.898a.806.70823.44188.8068.28336.015a.预测变量:(常量),x3,x1,x2。(3)由于决定系数R方=0.708R=0.898较大所以认为拟合度较高(4)Anovab模型平方和df均方FSig.1回归13655.37034551.7908.283.015a残差3297.1306549.522总计16952.5009a.预测变量:(常量),x3,x1,x2。b.因变量:y因为F=8.283P=0.015<0.05所以认为回归方程在整体上拟合的好(5)系数a模型非标准化系数标准系数tSig.B的95.0%置信区间相关性共线性统计量B标准误差试用版下限上限零阶偏部分容差VIF1(常量)-348.280176.459-1.974.096-780.06083.500x13.7541.933.3851.942.100-.9778.485.556.621.350.8251.211x27.1012.880.5352.465.049.05314.149.731.709.444.6871.455x312.44710.569.2771.178.284-13.41538.310.724.433.212.5861.708a.因变量:y(6)可以看到P值最大的是x3为0.284,所以x3的回归系数没有通过显著检验,应去除。去除x3后作F检验,得:Anovab模型平方和df均方FSig.1回归12893.19926446.60011.117.007a残差4059.3017579.900总计16952.5009a.预测变量:(常量),x2,x1。b.因变量:y由表知通过F检验继续做回归系数检验40
系数a模型非标准化系数标准系数tSig.B的95.0%置信区间相关性共线性统计量B标准误差试用版下限上限零阶偏部分容差VIF1(常量)-459.624153.058-3.003.020-821.547-97.700x14.6761.816.4792.575.037.3818.970.556.697.476.9871.013x28.9712.468.6763.634.0083.13414.808.731.808.672.9871.013a.因变量:y此时,我们发现x1,x2的显著性大大提高。(7)x1:(-0.997,8.485)x2:(0.053,14.149)x3:(-13.415,38.310)(8)(9)残差统计量a极小值极大值均值标准偏差N预测值175.4748292.5545231.500038.9520610标准预测值-1.4381.567.0001.00010预测值的标准误差10.46620.19114.5263.12710调整的预测值188.3515318.1067240.183549.8391410残差-25.1975933.22549.0000019.1402210标准残差-1.0751.417.000.81610Student化残差-2.1161.754-.1231.18810已删除的残差-97.6152350.88274-8.6834843.4322010Student化已删除的残差-3.8322.294-.2551.65810Mahal。距离.8945.7772.7001.55510Cook的距离.0003.216.486.97610居中杠杆值.099.642.300.17310a.因变量:y所以置信区间为(175.4748,292.5545)(10)由于x3的回归系数显著性检验未通过,所以居民非商品支出对货运总量影响不大,但是回归方程整体对数据拟合较好3.12解:在固定第二产业增加值,考虑第三产业增加值影响的情况下,第一产业每增加一个单位,GDP就增加0.607个单位。在固定第一产业增加值,考虑第三产业增加值影响的情况下,第二产业每增加一个单位,GDP就增加1.709个单位。第四章违背基本假设的情况40
4.8加权变化残差图上点的散步较之前的残差图,没有明显的趋势,点的散步较随机,因此加权最小二乘估计的效果较最小二乘估计好。4.9解:系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量)-.831.442-1.882.065x.004.000.83911.030.000a.因变量:y由SPSS计算得:=-0.831+0.004x残差散点图为:40
(2)由残差散点图可知存在异方差性再用等级相关系数分析:相关系数xtSpearman的rhoX相关系数1.000.318*Sig.(双侧)..021N5353T相关系数.318*1.000Sig.(双侧).021.N5353*.在置信度(双测)为0.05时,相关性是显著的。P=0.021所以方差与自变量的相关性是显著的。(3)模型描述因变量y自变量1x权重源x幂值1.500模型:MOD_1.M=1.5时可以建立最优权函数,此时得到:40
ANOVA平方和df均方FSig.回归.0061.00698.604.000残差.00351.000总计.00952系数未标准化系数标准化系数tSig.B标准误试用版标准误(常数)-.683.298-2.296.026x.004.000.812.0829.930.000所以:-0.683+0.004x(4)系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量).582.1304.481.000x.001.000.8059.699.000a.因变量:yy4.1040
经济变量的滞后性会给序列带来自相关性。如前期消费额对后期消费额一般会有明显的影响,有时,经济变量的这种滞后性表现出一种不规则的循环运动,当经济情况处于衰退的低谷时,经济扩张期随之开始,这时,大多数经济时间序列上升的快一些。在经济扩张时期,经济时间数列内部有一种内在的动力,受此影响,时间序列一直上升到循环的顶点,在顶点时刻,经济收缩随之开始。因此,在这样的时间序列数据中,顺序观察值之间的相关现象是恨自然的。4.11当一个线性回归模型的随机误差项存在序列相关时,就违背了线性回归方程的基本假设,如果仍然直接用普通最小二乘估计未知参数,将会产生严重后果,一般情况下序列相关性会带来下列问题:(1)参数的估计值不再具有最小方差线性无偏性。(2)均方误差MSE可能严重低估误差项的方差。(3)容易导致对t值评价过高,常用的F检验和t检验失效。如果忽视这一点,可能导致得出回归参数统计检验为显著,但实际上并不显著的严重错误结论。(4)当存在序列相关时,最小二乘估计量对抽样波动变得非常敏感。(5)如果不加处理地运用普通最小二乘法估计模型参数,用此模型进行预测和进行结构分析将会带来较大的方差甚至错误的解释。4.12优点:DW检验有着广泛的应用,对很多模型能简单方便的判断该模型有无序列相关性,当DW的值在2左右时,则无需查表,即可放心的认为模型不存在序列的自相关性。缺点:DW检验有两个不能确定的区域,一旦DW值落在这两个区域,就无法判断,这时,只有增大样本容量或选取其他方法;DW统计量的上、下界表要求n>15,这是因为如果样本再小,利用残差就很难对自相关的存在性作出比较正确的判断;DW检验不适合随机项具有高阶序列相关的检验。4.13解:(1)系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量)-1.435.242-5.930.000x.176.002.999107.928.000a.因变量:y=-1.435+0.176x(2)模型汇总b模型RR方调整R方标准估计的误差Durbin-Watson1.999a.998.998.09744.663a.预测变量:(常量),x。b.因变量:yDW=0.663查DW分布表知:=0.9540
所以DW<,故误差项存在正相关。残差图为:随t的变化逐次变化并不频繁的改变符号,说明误差项存在正相关。(3)=1-0.5*DW=0.6685计算得:40Y’x’7.3944.907.6545.806.8440.698.0048.507.7946.858.2649.457.9648.478.2850.047.9048.03Y’X’8.4951.177.8847.268.7752.338.9352.699.3254.959.2955.549.4856.779.3855.839.6758.009.9059.2240模型汇总b模型RR方调整R方标准估计的误差Durbin-Watson1.996a.993.993.073951.344a.预测变量:(常量),xx。b.因变量:yy系数a模型非标准化系数标准系数tSig.40
B标准误差试用版1(常量)-.303.180-1.684.110xx.173.004.99649.011.000a.因变量:yy得回归方程=-0.303+0.173x’即:=-0.303+0.6685+0.173(—0.6685)(4)模型汇总b模型RR方调整R方标准估计的误差Durbin-Watson1.978a.957.955.074491.480a.预测变量:(常量),x3。b.因变量:y3系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量).033.0261.273.220x3.161.008.97819.528.000a.因变量:y3△=0.033+0.161△即:=0.033++0.161(-)(5)差分法的DW值最大为1.48消除相关性最彻底,但是迭代法的值最小为0.07395,拟合的较好。4.14解:(1)模型汇总b模型RR方调整R方标准估计的误差Durbin-Watson1.541a.293.264329.69302.745a.预测变量:(常量),x2,x1。b.因变量:y系数a模型非标准化系数标准系数tSig.B标准误差试用版40
1(常量)-574.062349.271-1.644.107x1191.09873.309.3452.607.012x22.045.911.2972.246.029a.因变量:y回归方程为:=-574.062+191.098x1+2.045x2DW=0.7450),那么X"X+kI接近奇异的程度小得多,考虑到变量的量纲问题,先对数据作标准化,为了计算方便,标准化后的设计阵仍然用X表示,定义为,称为的岭回归估计,其中k称为岭参数。3.选择岭参数k有哪几种主要方法?答:选择岭参数的几种常用方法有1.岭迹法,2.方差扩大因子法,3.由残差平方和来确定k值。4.用岭回归方法选择自变量应遵从哪些基本原则?答:用岭回归方法来选择变量应遵从的原则有:1.40
在岭回归的计算中,我们假定设计矩阵X已经中心化和标准化了,这样可以直接比较标准化岭回归系数的大小,我们可以剔除掉标准化岭回归系数比较稳定且绝对值很小的自变量。1.当k值较小时标准化岭回归系数的绝对值并不是很小,但是不稳定,随着k的增加迅速趋于零。像这样的岭回归系数不稳定,震动趋于零的自变量,我们也可以予以删除。2.去掉标准化岭回归系数很不稳定的自变量,如果有若干个岭回归系数不稳定,究竟去掉几个,去掉哪几个,这并无一般原则可循,这需根据去掉某个变量后重新进行岭回归分析的效果来确定。5.对第5章习题9的数据,逐步回归的结果只保留了3个自变量x1,x2,x5,用y对这3个自变量做岭回归分析?答:6.对习题3.12的问题,分别用普通最小二乘和岭回归建立GDP对第二产业增加值x2,和第三产业增加值x3的二元线性回归,解释所得到的回归系数?答:R-SQUAREANDBETACOEFFICIENTSFORESTIMATEDVALUESOFKKRSQx2x3____________________________.00000.99923.774524.225943.05000.99803.512296.463711.10000.99629.489067.463649.15000.99367.473860.456649.20000.99025.461162.448152.25000.98615.449761.439303.30000.98147.439219.430476.35000.97628.429332.421821.40000.97067.419984.413400.45000.96470.411101.405242.50000.95842.402632.397352.55000.95189.394536.389732.60000.94514.386782.382376.65000.93822.379344.375274.70000.93116.372200.368419.75000.92398.365330.361799.80000.91672.358717.355405.85000.90939.352345.349227.90000.90202.346201.343255.95000.89462.340271.3374801.0000.88720.334545.33189240
系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量)4352.859679.0656.410.000第二产业增加值1.438.151.7759.544.000第三产业增加值.679.244.2262.784.017a.因变量:GDPR-SQUAREANDBETACOEFFICIENTSFORESTIMATEDVALUESOFKKRSQx2x3____________________________.00000.99923.774524.225943.01000.99888.587428.408049.02000.99866.548878.44165940
.03000.99847.531054.454593.04000.99827.520110.460694.05000.99803.512296.463711.06000.99776.506176.465082.07000.99745.501080.465475.08000.99710.496653.465244.09000.99672.492691.464593.10000.99629.489067.463649RunMATRIXprocedure:******RidgeRegressionwithk=0.01******MultR.999439RSquare.998878AdjRSqu.998691SE1301.292455ANOVAtabledfSSMSRegress2.0001.81E+0109.04E+009Residual12.000203203451693362.1FvalueSigF5341.336020.000000--------------VariablesintheEquation----------------BSE(B)BetaB/SE(B)x21.090606.060219.58742818.110661x31.226660.097506.40804912.580325Constant3980.247846738.314258.0000005.390994------ENDMATRIX-----结合表及图形可知,用普通最小二乘法得到的回归方程为.显然回归系数=0.679明显不合理。从岭参数图来看,岭参数k在0.0到0.1之间,岭参数已基本稳定,再参照复决定系数,当k=0.01时,复决定系数=0.998691,仍然很大,固用k=0.01做回归得到的未标准化的岭回归方程为。40
5.一家大型商业银行有多家分行,近年来,该银行的贷款额平稳增长,但不良贷款额也有较大比例的提高,为弄清楚不良贷款形成的原因,希望利用银行业务的有关数据做些定量分析,以便找出控制不良贷款的办法,表7.5是该银行所属25家分行2002年的有关业务数据。(1)计算y与其余四个变量的简单相关系数。(2)建立不良贷款y对4个自变量的线性回归方程,所得的回归系数是否合理?(3)分析回归模型的共线性。(4)采用后退法和逐步回归法选择变量,所得回归方程的回归系数是否合理,是否还存在共线性?(5)建立不良贷款y对4个自变量的岭回归。(6)对第4步剔除变量后的回归方程再做岭回归。(7)某研究人员希望做y对各项贷款余额,本年累计应收贷款.贷款项目个数这三个变量的回归,你认为这种做是否可行,如果可行应该如何做?相关性不良贷款y各项贷款余额x1本年累计应收到款x2贷款项目个数x3本年固定资产投资额x4Pearson相关性不良贷款y1.000.844.732.700.519各项贷款余额x1.8441.000.679.848.780本年累计应收到款x2.732.6791.000.586.472贷款项目个数x3.700.848.5861.000.747本年固定资产投资额x4.519.780.472.7471.000Sig.(单侧)不良贷款y..000.000.000.004各项贷款余额x1.000..000.000.000本年累计应收到款x2.000.000..001.009贷款项目个数x3.000.000.001..00040
本年固定资产投资额x4.004.000.009.000.N不良贷款y2525252525各项贷款余额x12525252525本年累计应收到款x22525252525贷款项目个数x32525252525本年固定资产投资额x42525252525系数a模型非标准化系数标准系数tSig.共线性统计量B标准误差试用版容差VIF1(常量)-1.022.782-1.306.206各项贷款余额x1.040.010.8913.837.001.1885.331本年累计应收到款x2.148.079.2601.879.075.5291.890贷款项目个数x3.015.083.034.175.863.2613.835本年固定资产投资额x4-.029.015-.325-1.937.067.3602.781a.因变量:不良贷款y共线性诊断a模型维数特征值条件索引方差比例(常量)各项贷款余额x1本年累计应收到款x2贷款项目个数x3本年固定资产投资额x4114.5381.000.01.00.01.00.002.2034.733.68.03.02.01.093.1575.378.16.00.66.01.134.0668.287.00.09.20.36.725.03611.215.15.87.12.63.0540
a.因变量:不良贷款y后退法得系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量)-1.022.782-1.306.206各项贷款余额x1.040.010.8913.837.001本年累计应收到款x2.148.079.2601.879.075贷款项目个数x3.015.083.034.175.863本年固定资产投资额x4-.029.015-.325-1.937.0672(常量)-.972.711-1.366.186各项贷款余额x1.041.009.9144.814.000本年累计应收到款x2.149.077.2611.938.066本年固定资产投资额x4-.029.014-.317-2.006.0583(常量)-.443.697-.636.531各项贷款余额x1.050.0071.1206.732.000本年固定资产投资额x4-.032.015-.355-2.133.044a.因变量:不良贷款y逐步回归得40
系数a模型非标准化系数标准系数tSig.B标准误差试用版1(常量)-.830.723-1.147.263各项贷款余额x1.038.005.8447.534.0002(常量)-.443.697-.636.531各项贷款余额x1.050.0071.1206.732.000本年固定资产投资额x4-.032.015-.355-2.133.044a.因变量:不良贷款yR-SQUAREANDBETACOEFFICIENTSFORESTIMATEDVALUESOFKKRSQx1x2x3x4____________________________________________.00000.79760.891313.259817.034471-.324924.05000.79088.713636.286611.096624-.233765.10000.78005.609886.295901.126776-.174056.15000.76940.541193.297596.143378-.131389.20000.75958.491935.295607.153193-.099233.25000.75062.454603.291740.159210-.074110.30000.74237.425131.286912.162925-.053962.35000.73472.401123.281619.165160-.037482.40000.72755.381077.276141.166401-.023792.45000.72077.364000.270641.166949-.012279.50000.71433.349209.265211.167001-.002497.55000.70816.336222.259906.166692.005882.60000.70223.324683.254757.166113.013112.65000.69649.314330.249777.165331.019387.70000.69093.304959.244973.164397.024860.75000.68552.296414.240345.163346.029654.80000.68024.288571.235891.162207.033870.85000.67508.281331.231605.161000.037587.90000.67003.274614.227480.159743.040874.95000.66508.268353.223510.158448.0437871.0000.66022.262494.219687.157127.04637340
RunMATRIXprocedure:******RidgeRegressionwithk=0.4******MultR.802353780RSquare.643771588AdjRSqu.611387187SE2.249999551ANOVAtabledfSSMSRegress2.000201.275100.638Residual22.000111.3755.062FvalueSigF19.87906417.00001172--------------VariablesintheEquation----------------BSE(B)BetaB/SE(B)x1.025805860.003933689.5744623956.56021879840
x4.004531316.007867533.050434658.575951348Constant.357087614.741566536.000000000.481531456------ENDMATRIX-----Y对x1x2x3做岭回归RunMATRIXprocedure:******RidgeRegressionwithk=0.4******MultR.850373821RSquare.723135635AdjRSqu.683583583SE2.030268037ANOVAtabledfSSMSRegress3.000226.08975.363Residual21.00086.5624.122FvalueSigF18.28313822.00000456--------------VariablesintheEquation----------------BSE(B)BetaB/SE(B)x1.016739073.003359156.3726273164.983118685x2.156806656.047550034.2752138783.297719120x3.067110931.032703990.1592210052.052071673Constant-.819486727.754456246.000000000-1.086195166------ENDMATRIX-----由图及表可知,(1)y与x1x2x3x4的相关系数分别为0.844,0.732,0.700,0.519.(2)y对其余四个变量的线性回归方程为由于40
的系数为负,说明存在共线性,固所得的回归系数是不合理的。(2)由于条件数=11.25>10,说明存在较强的共线性。(3)由上表可知由后退法和逐步回归法所得到的线性回归方程为由于的系数为负,说明仍然存在共线性。(4)Y对其余四个自变量的岭回归如上表所示。(5)选取岭参数k=0.4,得岭回归方程,回归系数都能有合理的解释。(6)用y对x1x2x3做岭回归,选取岭参数k=0.4,岭回归方程为回归系数都能有合理的解释,由B/SE(B)得近似的t值可知,x1x2x3都是显著的,所以y对x1x2x3的岭回归是可行的。40'
您可能关注的文档
- 《市场营销学》最近最全习题及答案.doc
- 《市场营销学》课后习题及答案.pdf
- 《市场营销学通论》教材课后复习题全部答案.doc
- 《市政公用工程管理与实务》历年真题及答案(2004-2012)完整版 一级建造师考试参考.doc
- 《市政公用工程管理与实务》历年真题及答案解析.pdf
- 程》_(方道元_著)_课后习题答案__浙江大学出版社.pdf
- 《常微分方程》练习题库参考答案.doc
- 《常用文体写作教程》题库及答案.doc
- 《常见病、多发病基本诊断与治疗》试题答案最新整理.doc
- 《应用密码学》胡向东版习题和思考题答案.doc
- 《应用文书写作》习题参考答案.doc
- 《应用概率统计》课后习题解答.doc
- 《建筑工程定额与预算》练习题标准答案.doc
- 《建筑工程概预算B》复习题及参考答案.doc
- 《建筑工程相关法律法规》试题库答案.doc
- 《建筑工程管理与实务》历年真题及答案解析.doc
- 《建筑工程管理与实务》历年真题及答案解析.pdf
- 《建筑工程评估基础》试题及答案.doc
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明