

- 352.00 KB
- 2022-04-22 11:36:04 发布

- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
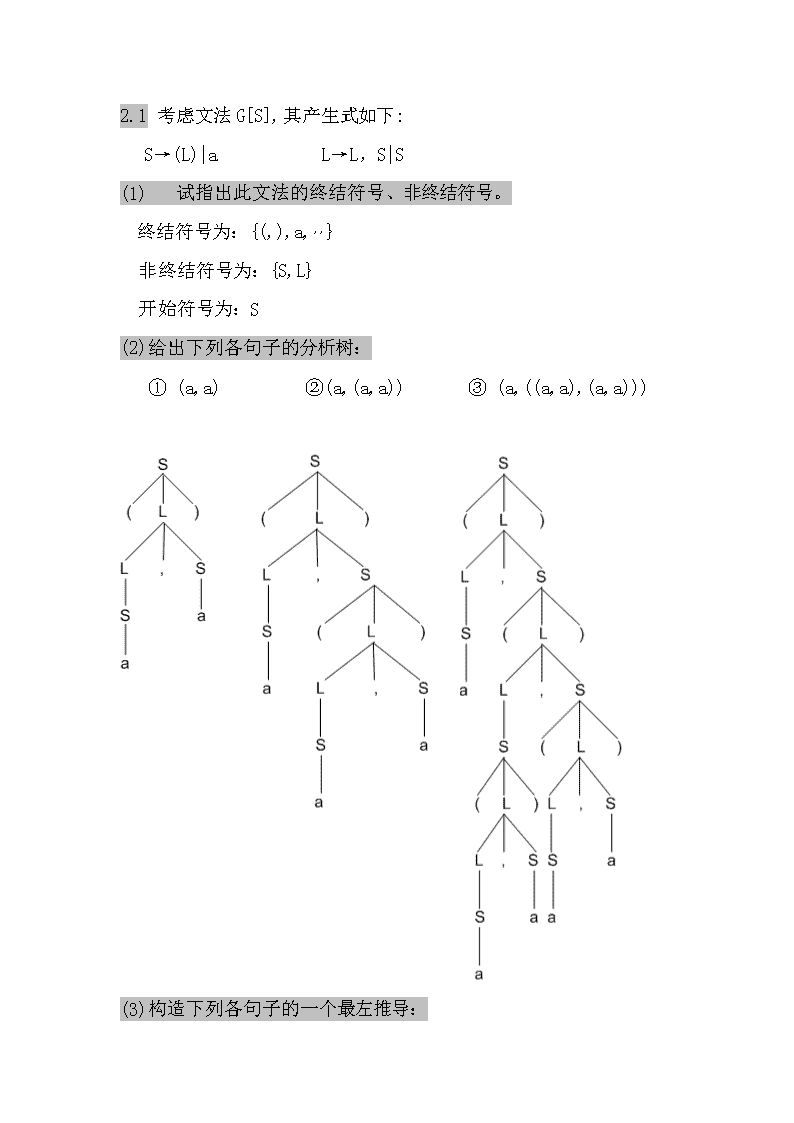
'2.1考虑文法G[S],其产生式如下:S→(L)|aL→L,S|S(1)试指出此文法的终结符号、非终结符号。终结符号为:{(,),a,,,}非终结符号为:{S,L}开始符号为:S(2)给出下列各句子的分析树:①(a,a) ②(a,(a,a))③(a,((a,a),(a,a))) (3)构造下列各句子的一个最左推导:
①(a,a)S(L)(L,S)(S,S)(a,S)(a,a)②(a,(a,a))S(L)(L,S)(S,S)(a,S)(a,(L)(a,(L,S)) (a,(S,S))(a,(a,S))(a,(a,a))③(a,((a,a),(a,a)))S(L)(L,S)(S,S)(a,S)(a,(L))(a,(L,S)) (a,(S,S))(a,((L),S))(a,((L,S),S))(a,((S,S),S)) (a,((a,S),S))(a,((a,a),S))(a,((a,a),(L))) (a,((a,a),(L,S)))(a,((a,a),(S,S)))(a,((a,a),(a,S)))(a,((a,a),(a,a)))(4)构造下列各句子的一个最右推导:①(a,a)S(L)(L,S)(L,a)(S,a)(a,a)②(a,(a,a))S(L)(L,S)(L,(L))(L,(L,S))(L,(L,a)) (L,(S,a))(L,(a,a))(S,(a,a))(a,(a,a)③(a,((a,a),(a,a)) S(L)(L,S)(L,(L))(L,(L,S))(L,(L,(L)))(L,(L,(L,S)))(L,(L,(L,a)))(L,(L,(S,a)))(L,(L,(a,a)))(L,(S,(a,a)))(L,((L),(a,a)))(L,((L,S),(a,a)))(L,((L,a),(a,a)))(L,((S,a),(a,a)))(L,((a,a),(a,a)))(S,((a,a),(a,a)))(a,((a,a),(a,a)))(5)这个文法生成的语言是什么?
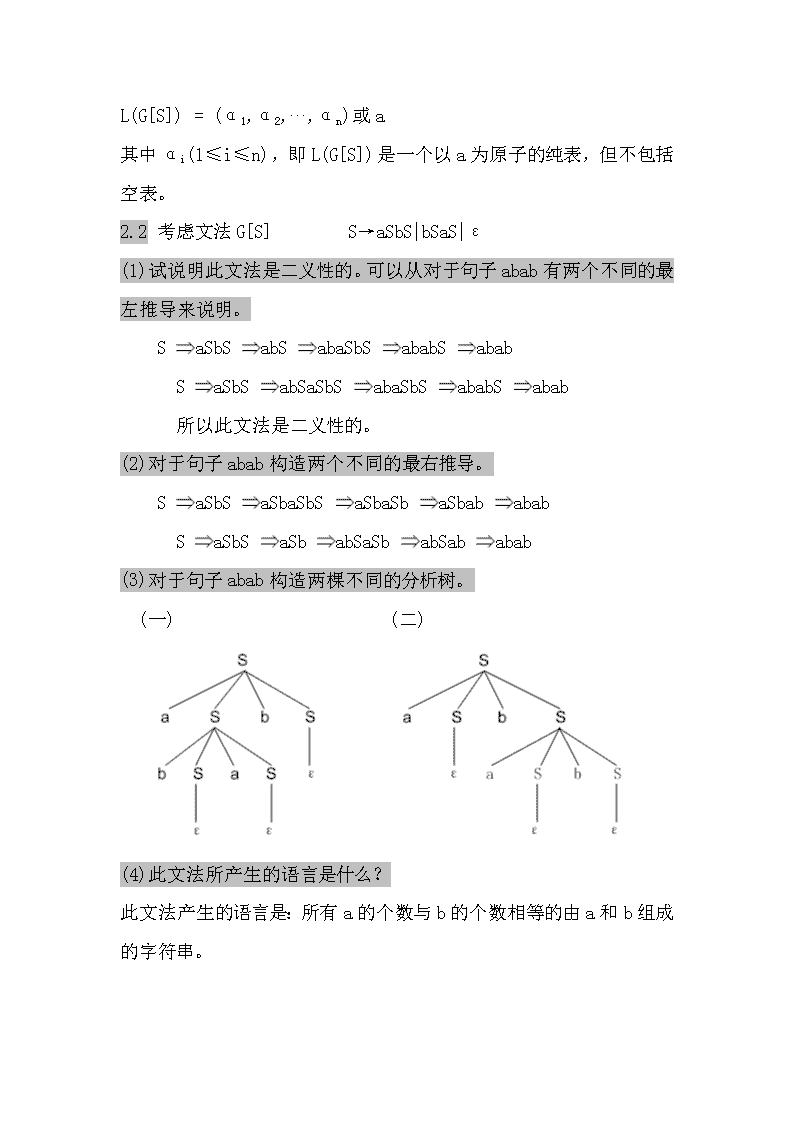
L(G[S])=(α1,α2,...,αn)或a其中αi(1≤i≤n),即L(G[S])是一个以a为原子的纯表,但不包括空表。2.2考虑文法G[S]S→aSbS|bSaS|ε(1)试说明此文法是二义性的。可以从对于句子abab有两个不同的最左推导来说明。SaSbSabSabaSbSababSabab SaSbSabSaSbSabaSbSababSabab 所以此文法是二义性的。(2)对于句子abab构造两个不同的最右推导。SaSbSaSbaSbSaSbaSbaSbababab SaSbSaSbabSaSbabSababab(3)对于句子abab构造两棵不同的分析树。 (一) (二) (4)此文法所产生的语言是什么?此文法产生的语言是:所有a的个数与b的个数相等的由a和b组成的字符串。
2.4已知文法G[S]的产生式如下:S→(L)|aL→L,S|S属于L(G[S])的句子是A,(a,a)是L(G[S])的句子,这个句子的最左推导是B,最右推导是C,分析树是D,句柄是E。A:①a ②a,a ③(L) ④(L,a)B,C:①S(L)(L,S)(L,a)(S,a)(a,a) ②S(L)(L,S)(S,S)(S,a)(a,a) ③S(L)(L,S)(S,S)(a,S)(a,a)D: E:①(a,a) ②a,a ③(a) ④a解答:A:①B:③C:①D:②E:④3.1 有限状态自动机可用五元组(VT,Q,δ,q0,Qf)来描述,设有一有限状态自动机M的定义如下: VT={0,1},Q={q0,q1,q2},Qf={q2},δ的定义为:δ(q0,0)=q1 δ(q1,0)=q2δ(q2,1)=q2 δ(q2
,0)=q2 M是一个A有限状态自动机,它所对应的状态转换图为B,它所能接受的语言可以用正则表达式表示为C。其含义为D。A: ①歧义的 ②非歧义的 ③确定的 ④非确定的B:C:①(0|1)* ②00(0|1)* ③(0|1)*00 ④0(0|1)*0D:①由0和1所组成的符号串的集合; ②以0为头符号和尾符号、由0和1所组成的符号串的集合; ③以两个0结束的,由0和1所组成的符号串的集合; ④以两个0开始的,由0和1所组成的符号串的集合。答案A:③ B:② C:② D:④
3.2 (1)有穷自动机接受的语言是正则语言。()(2)若r1和r2是Σ上的正规式,则r1|r2也是。()(3)设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。(4)令Σ={a,b},则Σ上所有以b为首的字构成的正规集的正规式为b*(a|b)*。(5)对任何一个NFAM,都存在一个DFAM",使得L(M")=L(M)。()(6)对一个右线性文法G,必存在一个左线性文法G",使得L(G)=L(G"),反之亦然。()答案(1) T (2) T (3) F (4) F (5) T3.3 描述下列各正规表达式所表示的语言。(1) 0(0|1)*0(2) ((ε|0)1*)*(3) (0|1)*0(0|1)(0|1)(4) 0*10*10*10*(5) (00|11)*((01|10)(00|11)*(01|10)(00|11)*)*答案(1) 以0开头并且以0结尾的,由0和1组成的所有符号串(2) {α|α∈{0,1}*}即由0和1组成的所有符号串。(3) 由0和1组成的符号串,且从右边开始数第3位为0。(4) 含3个1的由0和1组成的所有符号串。 {α|α∈{0,1}+,且α中含有3个1}(5) {α|α∈{0,1}*,α中含0和1的数目为偶数。}
4.10已知文法G[S],其产生式如下:S→(L)|a L→L,S|S文法G[S]的算符优先关系由下表给出。建立与下表相应的算符优先函数并用算符优先分析法分析句子(a,(a,a))。文法G[S]的算符优先关系表:解:对每个终结符或$建立符号f与g,把f(和g)分成一组。根据G[S]的算符优先关系表,画出如下的有向图:优先函数如下:用算符优先分析法分析句子(a,(a,a))
4.19(1)存在有左递归规则的文法是LL(1)的。 (2)任何算符优先文法的句型中不会有两个相邻的非终结符号。 (3)算符优先文法中任何两个相邻的终结符号之间至少满足三种 关系(<·,·>,)之一。 (4)任何LL(1)文法都是无二义性的。 (5)每一个SLR(1)文法也都是LR(1)文法。 (6)存在一种算法,能判定任何上下文无关文法是否是LL(1)的。 (7)任何一个LL(1)文法都是一个LR(1)文法,反之亦然。 (8)"LR(1)"括号中的1是指,在选用产生式A→α进行分析,看当前读入符号是否在FIRST(α)中。答案:(1)×(2)√(3)×(4)√(5)√(6)√(7)×(8)×4.20
在编译程序中,语法分析分为自顶向下分析和自底向上分析两类。__A__和LL(1)分析法属于自顶向下分析;__B__和LR分析法属于自底向上分析。自顶向下分析试图为输入符号串构造一个__C__;自底向上分析试图为输入符号串构造一个__D__。采用自顶向下分析方法时,要求文法中不含有__E__。A、B:①深度分析法②宽度优先分析法③算符优先分析法④预测递归分析法C、D:①语法树②有向无环图③最左推导④最右推导E:①右递归②左递归③直接右递归④直接左递归A:④B:③C:③D:④E:②4.21自底向上语法分析采用__A__分析法,常用的是自底向上语法分析有算符优先分析法和LR分析法。LR分析是寻找右句型的__B__;而算符优先分析是寻找右句型的__C__。LR分析法中分析能力最强的是__D__;分析能力最弱的是__E__。A:①递归②回溯③枚举④移进-规约B、C:①短语②素短语③最左素短语④句柄D、E:①SLR(1)②LR(0)③LR(1)④LALR(1)
A:④B:④C:③D:③E:②5.5用S的综合属性val给出在下面的文法中的S产生的二进制数的值(例如,对于输入 101.101,S.val=5.625): S→L.L|L L→LB|BB→0|1(1)试用各有关综合属性决定S.val。(2)试用一个语法制导定义来决定S.val,在这个定义中仅有B的综合属性,设为c,它给出由B生成的位对于最后的数值的贡献。例如,在101.101中的第一位和最后一位对于值5.625的贡献分别为4和0.125。解答:(1)用综合属性决定s.val的语法制导定义:产生式语义规则 S->LS.val:=L.val; S->L1.L2S.val:=L1.val+L2.val*L2.p; L->BL.val:=B.val; L.p:=2-1; L->L1BL.val:=L1.val*2+B.val;L.p:=L.p*2-1; B->0B.val:=0; B->1B.val:=1;
注:L.p表示恢复L.val的因子。(2)分析:设B.c是B的综合属性,是B产生的位对最终值的贡献。要求出B.c,必须求出B产生位的权,设B.i。B.i的求法请参看下面的图示:另外,设L.fi为继承因子,L.fs为综合因子,语法制导定义如下:产生式语义规则 S->LL.i:=1;L.fi:=2;L.fs:=1;S.val:=L.val; S->L1.L2L1.i=1;L1.fi=2;L1.fs:=1;L2.i=2-1;L2.fi=1;L2.fs:=2-1;S.val:=L1.val+L2.val; L->BL.s:=L.i;B.i:=L.s;L.val:=B.c;
L->L1BL1.i:=L.i*L1.fi;L.s:=L1.s*L1.fs;B.i:=L.s;L.val:=L1.val+B.c; B->0B.c:=0; B->1B.c:=B.i;5.15描述文法符号语义的属性有两种,一种称为(A),另一种称为(B)。(A)值的计算依赖于分析树中它的(C)的属性值;(B)的值的计算依赖于分析树中它的(D)的属性值。 A,B:①L-属性②R-属性③综合属性④继承属性 C,D:①父结点②子结点③兄弟结点④父结点与子结点⑤父结点与兄弟结点解答:A③ B④ C② D⑤5.16(1)语法制导定义中某文法符号的一个属性,既可以是综合属性,又可以是继承属性。(2)只使用综合属性的语法制导定义称为S-属性定义。(3)把L-属性定义变换成翻译模式,在构造翻译程序的过程中前进了一大步。(4)一个特定的翻译模式既适于自顶向下分析,又适于自底向上分析。(5)用于自顶向下分析的翻译模式,其基础文法中不能含有左递归。(6)在基础文法中增加标记非终结符不会导致新的语法分析冲突。解答:(1)FALSE (2)TRUE (3)TRUE (4)FALSE (5)TRUE (6)FALSE
6.7 (1)对于允许递归调用的程序语言,程序运行时的存储分配策略不能采用静态的存储分配策略。() (2)若一个程序语言的任何变量的存储空间大小和相互位置都能在编译时确定,则可采用静态分配策略。() (3)在不含嵌套过程的词法作用域中,若一个过程中有对名字a的非局部引用,则a必须在任何过程(或函数)外被说明。()(4)在允许嵌套的词法作用域的语言中,过程不能作为参数,原因时不能建立其运行环境的存取链。()(5)在堆式存储分配中,一个堆中存活的活动记录不一定是邻接的。()(6)如果源程序正文中过程p直接嵌入在过程q中,那么,p的一个活动记录中的存取链接指向q的最近的活动记录。()解答:(1)(TRUE)(2)(FALSE)(3)(TRUE)(4)(FALSE) (5)(TRUE)(6)(TRUE) 6.8运行时的存储分配策略分( A )和( B )两类。( B )又分( C )和( D )。一个语言中不同种类的变量根据定义域和生存期的不同往往采用不同的存储分配策略,C语言中的静态变量往往采用( A ),而自动(out)类变量往往采用( C )。使用mallac中申请的内存单元采用( D )。A,B,C,D:①栈式分配 ②最佳分配 ③堆式分配④静态分配 ⑤随机分配 ⑥动态分配 解答:A:④ B:⑥ C:① D:③
7.2翻译算术表达式一(a+b)*(c+d)+(a+b+c)为 (1)四元式, (2)三元式 (3)间接三元式解答:(1)四元式序列为: oparg1arg2result(1)+abt1(2)+cd t2(3)*t1t2t3(4)uminust3 t4(5)+abt5(6)+t5ct6(7)+t4t6t7(2)三元式序列为: oparg1arg2(1)+ab(2)+cd(3)*(1)(2)(4)uminus(3) (5)+ab
(6)+(5)c(7)+(4)(6)(3)间接三元式表示: statement oparg1arg2(1)(11)(11)+ab(2)(12)(12)+cd(3)(13)(13)*(11)(12)(4)(14)(14)uminus(13) (5)(11)(15)+(11)c(6)(15)(16)+(14)(15)(7)(16) 9.1试构造下面的程序的流图,并找出其中所有回边及循环。 readP x:=1 c:=P*P ifc<100gotoL1 B:=P*P x:=x+1 B:=B+
x writex halt L1:B:=10 x:=x+2 B:=B+x writeB ifB<100gotoL2 halt L2:x:=x+1 gotoL1解:程序的流图如下
9.2对本题中所示的流图,求出其各结点n的控制结点集D(n)、回边及循环(n0为首结点)。解:各结点n的控制结点集D(n)如下: D(n0)={n0} D(n1)={n0,n1} D(n2)={n0,n1,n2} D(n3)={n0,n1,n2,n3} D(n4)={n0,n1,n2,n4} D(n5)={n0,n1,n2,n5} D(n6)={n0,n1,n2,n5,n6} D(n7)={n0,n1,n2,n5,n6,n7}回边和循环:因为D(n5)={n0,n1,n2,n5},且n5->n2,所以n5->n2为一条回边。根据它求出的循环L1={n2,n5,n3,n4}。
因为D(n6)={n0,n1,n2,n5,n6},且n6->n1,所以n6->n1为一条回边。根据这条回边,求出的循环L2={n6,n1,n5,n3,n4,n2}。9.8在对编译程序产生的中间代码进行优化时,就实施优化的范围来说,分 A 优化和 B 优化。循环优化属于 B 优化,它对于提高目标代码的运行速度是非常有效的。循环优化主要采用的三项优化措施是 C 、 D 、 E 。答案:A:局部B:全局C:代码外提D:削减运算强度E:删除归纳变量'
您可能关注的文档
- 《统计学》练习题及答案.doc
- 《统计学》课后练习题参考答案.doc
- 《统计学》高等教育出版社第三版课后习题答案.doc
- 《统计学原理》复习参考(完整答案).doc
- 《统计学原理》课后习题答案.doc
- 《统计学概论》习题解答.doc
- 《统计预测与决策》第四版 徐国祥 复习试卷及答案.doc
- 《编译原理》习题解答081202[xiwang].pdf
- 《编译原理》第八章习题答案下载.pdf
- 《编译原理实践及应用》习题的参考答案.doc
- 《网络协议分析 寇晓 机械工程出版社课后习题答案.pdf
- 《自动控制原理(第2版)》李晓秀(习题参考答案).doc
- 《自动控制原理》(李晓秀)习题参考答案 (修复的).docx
- 《自动控制原理》(李晓秀)习题参考答案-改.doc
- 《自动控制原理》(李晓秀)习题参考答案.doc
- 《自动控制原理》5章课后习题参考答案.doc
- 《自动控制原理》习题及解答.doc
- 《自动控制原理》清华大学出版社、北京交通大学出版社;姚佩阳主编,曹锦、常永昌等副主编,课后习题详解.doc
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明