

- 2.96 MB
- 2022-04-22 11:20:20 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'第二章练习题及参考解答2.1为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2007年中国货币供应量(M2)和国内生产总值(GDP)的有关数据:表2.91990年—2007年中国货币供应量和国内生产总值(单位:亿元)年份货币供应量M2国内生产总值GDP199015293.418718.3199119349.921826.2199225402.226937.3199334879.835260.0199446923.548108.5199560750.559810.5199676094.970142.5199790995.378060.81998104498.583024.31999119897.988479.22000134610.498000.52001158301.9108068.22002185007.0119095.72003221222.8135174.02004254107.0159586.72005298755.7184088.62006345603.6213131.72007403442.2251483.2资料来源:中国统计年鉴2008,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明相关分析结果的经济意义。练习题2.1参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:nXiYiXiYi计算方法:rXY2222nXi(Xi)nYi(Yi)(XiX)(YiY)或rX,Y22(XiX)(YiY)计算结果:M2GDPM210.996426148646GDP0.9964261486461
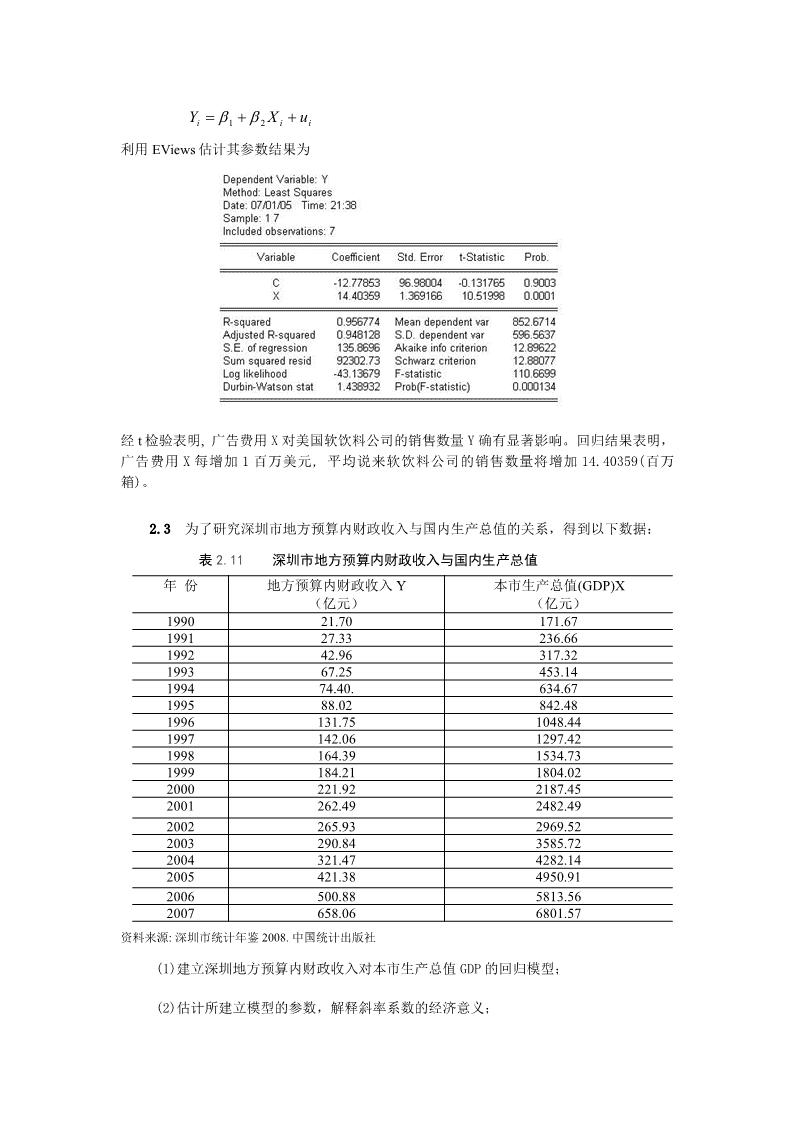
经济意义:这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。2.2为研究美国软饮料公司的广告费用X与销售数量Y的关系,分析七种主要品牌软饮料公司的有关数据表2.10美国软饮料公司广告费用与销售数量品牌名称广告费用X(百万美元)销售数量Y(百万箱)Coca-ColaClassic131.31929.2Pepsi-Cola92.41384.6Diet-Coke60.4811.4Sprite55.7541.5Dr.Pepper40.2546.9MoutainDew29.0535.67-Up11.6219.5资料来源:(美)AndersonDR等.商务与经济统计.机械工业出版社.1998.405绘制美国软饮料公司广告费用与销售数量的相关图,并计算相关系数,分析其相关程度。能否在此基础上建立回归模型作回归分析?练习题2.2参考解答美国软饮料公司的广告费用X与销售数量Y的散点图为说明美国软饮料公司的广告费用X与销售数量Y正线性相关。相关系数为:xyx10.978148015384y0.9781480153841说明美国软饮料公司的广告费用X与销售数量Y的正相关程度相当高。若以销售数量Y为被解释变量,以广告费用X为解释变量,可建立线性回归模型
YXui12ii利用EViews估计其参数结果为经t检验表明,广告费用X对美国软饮料公司的销售数量Y确有显著影响。回归结果表明,广告费用X每增加1百万美元,平均说来软饮料公司的销售数量将增加14.40359(百万箱)。2.3为了研究深圳市地方预算内财政收入与国内生产总值的关系,得到以下数据:表2.11深圳市地方预算内财政收入与国内生产总值年份地方预算内财政收入Y本市生产总值(GDP)X(亿元)(亿元)199021.70171.67199127.33236.66199242.96317.32199367.25453.14199474.40.634.67199588.02842.481996131.751048.441997142.061297.421998164.391534.731999184.211804.022000221.922187.452001262.492482.492002265.932969.522003290.843585.722004321.474282.142005421.384950.912006500.885813.562007658.066801.57资料来源:深圳市统计年鉴2008.中国统计出版社(1)建立深圳地方预算内财政收入对本市生产总值GDP的回归模型;(2)估计所建立模型的参数,解释斜率系数的经济意义;
(3)对回归结果进行检验。(4)若是2008年深圳市的本市生产总值为8000亿元,试对2008年深圳市的财政收入作出点预测和区间预测(0.05)。练习题2.3参考解答:1、建立深圳地方预算内财政收入对GDP的回归模型,建立EViews文件,利用地方预算内财政收入(Y)和GDP的数据表,作散点图可看出地方预算内财政收入(Y)和GDP的关系近似直线关系,可建立线性回归模型:YGDPut12tt利用EViews估计其参数结果为即Yˆ20.46110.0850GDPtt(9.8674)(0.0033)t=(2.0736)(26.1038)R2=0.9771F=681.40642经检验说明,深圳市的GDP对地方财政收入确有显著影响。R0.9771,说明GDP解释
了地方财政收入变动的近98%,模型拟合程度较好。模型说明当GDP每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。当2008年GDP为7500亿元时,地方财政收入的点预测值为:Yˆ20.46110.08508000700.4611(亿元)2008区间预测:为了作区间预测,取0.05,Y平均值置信度95%的预测区间为:f21(XX)Yˆtˆff22nxi利用EViews由GDP数据的统计量得到2031.266X2300.773n=18x222则有xix(n1)2031.266(181)70142706.566922(XX)(80002300.773)32481188.3976f1取0.05,Yˆ700.4611,t(18-2)=2.120平均值置信度95%的预测区间为:20080.0252^^1(XX)fYtf22nxi132481188.3976GDP8000时700.46112.12027.260220081870142706.5669700.461141.6191(亿元)Y个别值置信度95%的预测区间为:f2^^1(XX)fYt1f22nxi132481188.3976即700.46112.12027.260211870142706.5669700.461171.2181(亿元)2.4为研究中国改革开放以来国民总收入与最终消费的关系,搜集到以下数据:表2.12中国国民总收入与最终消费(单位:亿元)年份国民总收入最终消费年份国民总收入最终消费XYXY19783645.2172239.1199335260.0221899.919794062.5792633.7199448108.4629242.219804545.6243007.9199559810.5336748.219814889.4613361.5199670142.4943919.5
19825330.4513714.8199778060.8348140.619835985.5524126.4199883024.2851588.219847243.7524846.3199988479.1555636.919859040.7375986.3200098000.4561516198610274.386821.82001108068.266878.3198712050.627804.62002119095.771691.2198815036.829839.5200313517477449.5198917000.9211164.22004159586.787032.9199018718.3212090.52005184088.697822.7199121826.214091.92006213131.7110595.3199226937.2817203.32007251483.2128444.6资料来源:中国统计年鉴2008.中国统计出版社,2008.(1)以分析国民总收入对消费的推动作用为目的,建立线性回归方程,并估计其参数。2(2)计算回归估计的标准误差ˆ和可决系数R。(3)对回归系数进行显著性水平为5%的显著性检验。(4)如果2008年全年国民总收入为300670亿元,比上年增长9.0%,预测可能达到的最终消费水平,并对最终消费的均值给出置信度为95%的预测区间。练习题2.4参考解答:(1)以最终消费为被解释变量Y,以国民总收入为解释变量X,建立线性回归模型:YXui12ii利用EViews估计参数并检验回归分析结果为:Yˆ3044.3430.530112Xtt(895.4040)(0.00967)t=(3.3999)(54.8208)2R0.9908n=302(2)回归估计的标准误差即估计的随机扰动项的标准误差ˆet(n2),由EViews
估计参数和检验结果得ˆ3580.903,可决系数为0.9908。(3)由t分布表可查得t(302)2.048,由于t54.8208t(28)2.048,或由0.02520.025P值=0.000可以看出,对回归系数进行显著性水平为5%的显著性检验表明,国民总收入对最终消费有显著影响。(4)如果2008年全年国民总收入为300670亿元,预测可能达到的最终消费水平为:Yˆ3044.3430.530112300670162433.1180(亿元)2008对最终消费的均值置信度为95%的预测区间为:2^^1(XX)fYtf22nxi由Eviews计算国民总收入X变量样本数据的统计量得:68765.51X63270.07n=30x222则有xix(n1)68765.51(301)137132165601.242922(XX)(30067063270.07)56358726764.0049f取0.05,Yˆ162433.1180,t(30-2)=2.048,已知ˆ3580.903,平均值置信20080.025度95%的预测区间为:2^^1(XX)fYtf22nxi156358726764.0049=162433.11802.0483580.90330137132165601.2429=162433.11884888.4110(亿元)2.5美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》(TheWallStreetJournalAlmanac1999)上。航班正点到达的比率和每10万名乘客投诉的次数的数据如下1。表2.13美国各航空公司业绩的统计数据航空公司名称航班正点率(%)投诉率(次/10万名乘客)西南(Southwest)航空公司81.80.21大陆(Continental)航空公司76.60.58西北(Northwest)航空公司76.60.851资料来源:(美)DavidR.Anderson等《商务与经济统计》,第405页,机械工业出版社
美国(USAirways)航空公司75.70.68联合(United)航空公司73.80.74美洲(American)航空公司72.20.93德尔塔(Delta)航空公司71.20.72美国西部(Americawest)航空公司70.81.22环球(TWA)航空公司68.51.25资料来源:(美)AndersonDR等.商务与经济统计.机械工业出版社.1998,405.(1)画出这些数据的散点图(2)根据散点图。表明二变量之间存在什么关系?(3)估计描述投诉率如何依赖航班按时到达正点率的回归方程。(4)对估计的回归方程斜率的意义作出解释。(5)如果航班按时到达的正点率为80%,估计每10万名乘客投诉的次数是多少?练习题2.5参考解答:美国各航空公司航班正点到达比率X和每10万名乘客投诉次数Y的散点图为由图形看出航班正点到达比率和每10万名乘客投诉次数呈现负相关关系,利用EViews计算线性相关系数为:XYX1-0.882607Y-0.882607建立描述投诉率(Y)依赖航班按时到达正点率(X)的回归方程:YXui12ii利用EViews估计其参数结果为
即Yˆ6.0178320.070414Xii(1.017832)(-0.014176)t=(5.718961)(-4.967254)R2=0.778996F=24.67361从检验结果可以看出,航班正点到达比率对乘客投诉次数确有显著影响。这说明当航班正点到达比率每提1个百分点,平均说来每10万名乘客投诉次数将下降0.07次。如果航班按时到达的正点率为80%,估计每10万名乘客投诉的次数为Yˆ6.0178320.070414800.384712(次)i2.6表2.34中是16支公益股票某年的每股帐面价值Y和当年红利X的数据:表2.14某年16支公益股票每股帐面价值和当年红利帐面价值Y红利X帐面价值Y公司序号公司序号红利X(元)(元)(元)(元)122.442.4912.140.80220.892.981023.311.94322.092.061116.233.00414.481.09120.560.28520.731.96130.840.84619.251.551418.051.80720.372.161512.451.21826.431.601611.331.07(1)分析每股帐面价值和当年红利的相关性?(2)建立每股帐面价值和当年红利的回归方程;(3)解释回归系数的经济意义。练习题2.6参考解答:
1.分析每股帐面价值和当年红利的相关性作散布图:从图形看似乎具有一定正相关性,计算相关系数:每股帐面价值和当年红利的相关系数为0.7086472.建立每股帐面价值X和当年红利Y的回归方程:YXui12ii回归结果:参数的t检验:t值为3.7580,查表t(162)2.145F(3,10)3.71方程线性显著,0.05但各t检验值都小于2,不显著。模型存在多重共线性。(2)模型估计得到如下方程(输出结果见附录图4):Yˆ24.5370.678Zttt值3.579.5122R0.88R0.87F=90.5根据0.75,0.625,ZX0.75X0.625X,得到24.537,3242t2t3t4t10.678,0.509,0.424。234(3)对Z可以理解为某种意义上的总收入,它是由全部的工资收入、75%的非工资、非农业收入和62.5%的农业收入之和构成。就是说,在对收入构成的分类中,存在某种程度的重复,亦即它们之间存在某种程度的相关性,不能把所有的非工资、非农业收入和所有的农业收入加入模型。但须注意,工资收入与非工资、非农业收入及农业收入之间不存在因果关系。习题八解答(1)估计模型得到如下方程(输出结果见附录图5):Yˆ15327.65.488X0.393X0.009X0.123X0.112X23456t值-0.462.21.02-0.11-0.4430.22822R0.937R0.893F=20.93结果分析:解释能力较好,达到89.3%,F检验显著(F临界值3.97),但t检验值通不过
检验。可能存在多重共线性。(2)先做解释变量的相关系数得到表1:表1相关系数(correlation)x2x3x4x5x6x21-0.351830.567240.970460.687849x3-0.351831-0.67609-0.399580.216498x40.56724-0.6760910.6624760.287787x50.97046-0.399580.66247610.627399x60.6878490.2164980.2877870.6273991可以看到,变量之间高度相关,X2与X5之间相关系数达到0.97。因此模型存在多重共线性。当然还有其他检验方法,如辅助回归,即自变量之间做回归,检验其显著性判别是否存在多重共线性;还有可以计算VIF或TOL来判断。在此不一一列出。但需提醒一个问题,解释变量之间简单相关系大小不是判别多重共线性的充要条件。就是说,如果存在存在多重共线性,解释变量之间不一定存在很高的简单相关系数,反之则成立。因此简单相关系数判别多重共线性不能当做教条!用相关系数检验多重共线性时,还需要考虑偏相关系数,这样才能准确的判别。(3)本题使用逐步回归法进行修正。首先做Y对每一个解释变量的个别回归(输出结果见附录图6-图10),选取回归效果最好的一个方程。经对比,选取Y对X2的回归方程如下:Yˆ31605.34.228X2t值25.478.6522R0.872R0.86F=74.85其次,在上述模型下分别加入其它解释变量回归(输出结果见附录图11-图14),选取效果最好的方程,经对比,选取Y对X2、X3的回归,方程如下:Yˆ24206.584.648X0.492X23t值-1.30411.723.0122R0.933R0.919F=69.37可以看到,解释能力显著提高,而且F检验和t检验都显著(常数项除外,无实际意义)。再次,在上述模型下,继续照搬上述方法,进行回归(输出结果见附录图15-图17),选取效果最好的。经分析,没有得到较好回归结果,逐步回归法停止。因此最终模型为Y对X2、X3的回归模型。不过为了模型得到跟好结果,采取无截距项的回归(输出见附录图18),回归方程如下:Yˆ4.442X0.279X23t值11.83532.61322R0.921R0.914
结果分析:对比有截距项和无截距项的回归,发现解释能力为发生显著的下降,因此无截距项回归,在方方程F检验和t检验全部显著的条件下获得了较好的效果。多重共线性的修正方法还有岭回归,数据结合等。最后说明:对于多重共线性的修正不能盲目进行,要考虑经济意义,多重共线性是一种样本现象,多数情况下的多重共线性,只要增大样本都会取得较好的效果,但不可奢求消除多重共线性,只能说可以减小其程度,使模型在误差项容许的范围下达到最好。第五章异方差性习题五解答(1)估计回归模型得到如下方程(输出结果见附录图19):Yˆ9.3470.637Xt值2.5693222R0.946R0.9455F=1024.6结果分析:模型拟合较好,解释能力达到94.6%,显著性均通过。(2)检验异方差性的方法有多种,以下采取①图示法,②怀特检验。首先图示法检验得到:图1Y与X散点图图2误差项平方和R与X的散点图200301802016014010Y120R010080-106040-205010015020025030050100150200250300XX从图1可以看出,Y与X得散点图似乎看不出异方差性,但从残差项与X的散点图可以看出存在异方差。其次再用怀特检验得到:图3white检验输出结果HeteroskedasticityTest:WhiteF-statistic6.301373Prob.F(2,57)0.0034Obs*R-squared10.86401Prob.Chi-Square(2)0.0044ScaledexplainedSS9.912825Prob.Chi-Square(2)0.007
TestEquationDependentVariable:RESID^2Method:LeastSquaresDate:12/21/09Time:00:41Sample:160Includedobservations:60VariableCoefficientStd.Errort-StatisticProb.C-10.03614131.1424-0.0765290.9393X0.1659771.6198560.1024640.9187X^20.00180.0045870.3924690.6962R-squared0.181067Meandependentvar78.86225AdjustedR-squared0.152332S.D.dependentvar111.1375S.E.ofregression102.3231Akaikeinfocriterion12.14285Sumsquaredresid596790.5Schwarzcriterion12.24757Loglikelihood-361.2856Hannan-Quinncriter.12.18381F-statistic6.301373Durbin-Watsonstat1.442328Prob(F-statistic)0.00337从表中的前四行可以看出,模型存在异方差,Obs*R-squared值为10.86,大于临界值。(3)对异方差性修正有多种方法,本题采取①WLS,②对数变换法两种方法。首先采用WLS法,取W=1/resid,得到如下方程(输出结果见附录图20):Yˆ10.2510.633Xt值28.59372.5122R0.999R0.999F=138766.3对比加权和为加权的两个回归结果,发现,结果大有改进,DW统计量都显著改善!接下来对数变换法进行修正,最后把钟方法的输出结果做对比。对数变换得到如下方程(输出结果见附录图21):log(Y)ˆ0.140.902log(X)t值1.0534.4522R0.953R0.9952F=1186.9结果分析:我们看到,对数变换并没有显著改善模型,解释能力提高不到1%。因此对数
变换不适合本题的修正,我们最好采用WLS修正。当然这只是本题的结论。由凯恩斯消费理论知,消费和收入之间大致成线性关系。习题六解答(1)首先做散点图分析数据之间的关系,得到下图:图4Y与X、Z散点图300,000250,000200,000X150,000Z100,00050,000004,0008,00012,00016,000Y我们看到,Y与利润Z、Y与销量X之间大致呈线性关系,但是,Y对销量X的回归明显存在异方差,这符合本题的出题目的。因此我们建立线性回归模型:YXu,i12ii估计得到如下方程(输出结果见附录图22):Yˆ192.990.03Xt值0.1953.8322R0.478R0.446F=14.67结果分析:拟合效果不太好,解释能力才47.8%,不到50%,虽然显著性检验通过。在截面数据的回归中,异方差性一直是个萦绕心头的问题。本题抽取的不同部门的销售量和R&D费用的数据,因为不同部分用于R&D费用的比列不同,所以在销量中,R&D费用占有的比列就存在差异。(2)为了说明如何运用Glerjser方法检验异方差,下面以本题为例说明。其基本思想是用残差项的绝对值对解释变量的不同形式做回归,判断回归方程的显著性,以此来界定原回归模型是否存在异方差。依次做如下模型的回归估计(输出结果见附录图23-图27):1eXu,eXu,eu,eXu,i12iii2iii2ii2iiXi1eu。经估计得到,对解释变量平方根的回归最为显著,系数通过检验。必i2iXi须说明,Glerjser检验只有在大样本情况下才会得到较好的拟合效果,在小样本情况下,则只能作为了解异方差性某种信息的一种手段。(3)采用WLS和对数变换法进行修正。WLS修正,W=1/X,得到如下方程(输出结果见
附录图28):Yˆ*243.50.037X*t值-1.85.52522R0.656R0.635F=30.5对比原回归结果,解释能力有显著改善。在用对数变换法做修正,得到如下方程(输出结果见附录图29):log(Y)ˆ7.3651.32log(X)t值-3.9857.86922R0.795R0.782F=61.92可以看出,在本题的修正中,对数变换方法比加权得到得到了更好的效果。这就说明,不同的数据模型,其适应的修正方法也不同。习题七解答(1)首先做散点图分析,通过图示粗略地分析Y与X得关系,散点图如下:图5Y与X的散点图图6LOG(Y)与LOG(X)散点图302520Y151050051015202530X
3.53.02.5)2.0(YGOL1.51.00.50.00.51.01.52.02.53.03.5LOG(X)从散点图分析我们发现,股票价格Y与X之间,线性关系相当微弱,其对数化后的线性关系也不见得好转,但这也只是粗略地分析而已,具体的需要回归估计。分别估计以下两模型:YXu,log(Y)Xui12iii12ii得到如下两方程(输出结果见附录图30-图31):Yˆ4.610.757Xt值4.255.0522R0.586R0.563F=25.52log(Y)ˆ1.3230.458log(X)t值3.5971.9122R0.169R0.123F=3.66结果分析:由估计可以看出,Y对X的线性回归显著,但拟合效果不太好,对数化后的模型估计效果更次,不能通过检验。对残差进行分析:画出残差对解释变量的散点图,试着分析两者关系:图7残差项与X得散点图
8642R0-2-4-6-8051015202530X从散点图看不出残差与X得关系,因为存在异常点干扰整体关系。(2)重做回归得到如下方程(输出结果见附录图32):Yˆ6.7380.22Xt值2.830.39822R0.009R0.049F=0.16结果分析:结果非常令人意想不到!剔除点后,居然模型回归由显著变为不显著!,可以说原模型是个伪回归。也即说明,Y与X之间的线性关系微弱,或者说消费者价格变化率会影响股票价格,但是影响股票价格的主要因素不是消费者价格变化率,而是其他因素。所以,本题找的两个数据没有实质意义,无非是锻炼我们掌握异方差性的相关内容。但是这样的工作可能会影响同学们的现实思考能力,以为回归模型可以利用在任何场合,也就是说方法能论!实事求是才是解决问题的前提和出发点。习题八解答(1)先验分析,12个样本,有五个解释变量,如把所有解释变量都纳入进来估计结果肯定不显著,存在多重共线性,为了更合理的分析,先做产值Y对所有解释变量的回归,得到如下方程(输出结果见附录图33):Yˆ4.720.04X0.04X0.26X0.01X0.03X12345t值0.521.45-0.470.482.711.6322R0.975R0.953F=45.93结果分析:模型整体拟合效果较好,F检验显著,但是大部分t值却不显著,这是多重共线性的典型现象,为此运用逐步回归法得到如下较好的方程(简要输出结果见附录,步骤省略):Yˆ0.881X0.01X0.029X345t值3.462.62.522R0.963R0.955对比上述两方程,我们看到逐步回归法得到的方程,所有系数都显著,解释能力相比于原
方程并没有显著下降。这可以作为最终建立的模型,下面的分析将基于上述模型进行。(2)运用Glejser检验和white检验分析异方差,得到如下结果(图8、图9):图8Glejser检验结果HeteroskedasticityTest:GlejserF-statistic1.671343Prob.F(3,8)0.2494Obs*R-squared4.623345Prob.Chi-Square(3)0.2015ScaledexplainedSS2.702259Prob.Chi-Square(3)0.4398TestEquation:DependentVariable:ARESIDMethod:LeastSquaresDate:12/21/09Time:15:41Sample:112Includedobservations:12VariableCoefficientStd.Errort-StatisticProb.C7.7598203.9188321.9801360.0830X3-0.1642620.121134-1.3560330.2121X4-0.0019300.001782-1.0829890.3104X50.0121510.0062191.9539690.0865R-squared0.385279Meandependentvar11.94158AdjustedR-squared0.154758S.D.dependentvar7.839495S.E.ofregression7.207399Akaikeinfocriterion7.049295Sumsquaredresid415.5728Schwarzcriterion7.210930Loglikelihood-38.29577Hannan-Quinncriter.6.989452F-statistic1.671343Durbin-Watsonstat1.985993Prob(F-statistic)0.249381图9white检验结果HeteroskedasticityTest:WhiteF-statistic9.463925Prob.F(6,5)0.0130Obs*R-squared11.02887Prob.Chi-Square(6)0.0875ScaledexplainedSS5.292628Prob.Chi-Square(6)0.5069TestEquation:DependentVariable:RESID^2Method:LeastSquaresDate:12/21/09Time:15:47Sample:112Includedobservations:12VariableCoefficientStd.Errort-StatisticProb.C-29.0542156.72871-0.5121610.6304X3^20.6986110.2295393.0435420.0286X3*X4-0.0054540.008398-0.6494160.5447X3*X5-0.0626640.023860-2.6262930.0467X4^25.25E-065.38E-050.0976760.9260X4*X50.0002900.0003020.9613910.3805X5^20.0013400.0005532.4255060.0597R-squared0.919072Meandependentvar198.9376AdjustedR-squared0.821959S.D.dependentvar271.4158S.E.ofregression114.5236Akaikeinfocriterion12.61064
Sumsquaredresid65578.31Schwarzcriterion12.89350Loglikelihood-68.66382Hannan-Quinncriter.12.50591F-statistic9.463925Durbin-Watsonstat1.459409Prob(F-statistic)0.013029结果分析,两种检验,在0.05的显著性水平下(95%置信水平),均不能拒绝无异方差性的假设。因此逐步回归法得到的模型在0.05的显著性水平下不能拒绝无异方差性的假设。(3)如果把显著性水平降低到0.1,则white检验将得到异方差性的结果。这时如果要修正模型,可采用WLS法。下面以WLS作简要修正,W=1/resid,resid为Y对X3、X4、X5回归得到的残差。修正得到如下结果(输出结果见附录图34):Yˆ1.04X0.009X0.02X345t值5.54.32.6222R0.992R0.99结果分析:虽然加权之后回归拟合效果提高了3%,但是,必须看到,这里做的修正是在降低显著性水平条件下进行的,即只是一个练习操作而已,没有实质意义。在实际研究中,当原模型可以很好的拟合数据时,我们再继续对它做些画蛇添足的行为时愚蠢的。附录图1DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:20:25Sample:110Includedobservations:10VariableCoefficientStd.Errort-StatisticProb.C24.551586.9523483.5314080.0096X20.5684250.7160980.7937810.4534X3-0.0058330.070294-0.0829750.9362R-squared0.962099Meandependentvar111.0000AdjustedR-squared0.951270S.D.dependentvar31.42893S.E.ofregression6.937901Akaikeinfocriterion6.955201Sumsquaredresid336.9413Schwarzcriterion7.045976Loglikelihood-31.77600F-statistic88.84545Durbin-Watsonstat2.708154Prob(F-statistic)0.000011图2DependentVariable:Y
Method:LeastSquaresDate:12/20/09Time:20:40Sample:110Includedobservations:10VariableCoefficientStd.Errort-StatisticProb.C24.454556.4138173.8127910.0051X20.5090910.03574314.243170.0000R-squared0.962062Meandependentvar111.0000AdjustedR-squared0.957319S.D.dependentvar31.42893S.E.ofregression6.493003Akaikeinfocriterion6.756184Sumsquaredresid337.2727Schwarzcriterion6.816701Loglikelihood-31.78092F-statistic202.8679Durbin-Watsonstat2.680127Prob(F-statistic)0.000001图3DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:21:39Sample:114Includedobservations:14VariableCoefficientStd.Errort-StatisticProb.C22.734637.5505873.0109760.0131X20.4110800.3433391.1973030.2588X31.3028420.7929391.6430550.1314X40.1959431.5442240.1268880.9015R-squared0.894442Meandependentvar87.76429AdjustedR-squared0.862774S.D.dependentvar18.06057S.E.ofregression6.690349Akaikeinfocriterion6.874166Sumsquaredresid447.6078Schwarzcriterion7.056753Loglikelihood-44.11916Hannan-Quinncriter.6.857264F-statistic28.24485Durbin-Watsonstat1.439495Prob(F-statistic)0.000034图4DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:21:52Sample:114Includedobservations:14VariableCoefficientStd.Errort-StatisticProb.C24.537476.8642673.5746670.0038Z0.6784000.0713059.5141170.0000R-squared0.882948Meandependentvar87.76429AdjustedR-squared0.873194S.D.dependentvar18.06057S.E.ofregression6.431349Akaikeinfocriterion6.691809Sumsquaredresid496.3470Schwarzcriterion6.783103Loglikelihood-44.84266Hannan-Quinncriter.6.683358F-statistic90.51842Durbin-Watsonstat1.446036Prob(F-statistic)0.000001图5
DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:22:28Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C-15327.6033512.84-0.4573650.6613X25.4876152.4948432.1995840.0638X30.3930320.3839941.0235370.3401X4-0.0093480.084285-0.1109100.9148X5-0.1230430.277870-0.4428060.6713X60.1122540.4931960.2276060.8265R-squared0.937310Meandependentvar42010.15AdjustedR-squared0.892532S.D.dependentvar2948.714S.E.ofregression966.6556Akaikeinfocriterion16.88960Sumsquaredresid6540962.Schwarzcriterion17.15035Loglikelihood-103.7824Hannan-Quinncriter.16.83600F-statistic20.93228Durbin-Watsonstat2.807954Prob(F-statistic)0.000444图6DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:12Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C31605.331240.94225.468830.0000X24.2277540.4886818.6513610.0000R-squared0.871864Meandependentvar42010.15AdjustedR-squared0.860215S.D.dependentvar2948.714S.E.ofregression1102.461Akaikeinfocriterion16.98912Sumsquaredresid13369621Schwarzcriterion17.07603Loglikelihood-108.4293Hannan-Quinncriter.16.97125F-statistic74.84604Durbin-Watsonstat2.366188Prob(F-statistic)0.000003图7DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:13Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C62268.0362353.060.9986360.3394X3-0.1820290.560228-0.3249200.7513R-squared0.009506Meandependentvar42010.15AdjustedR-squared-0.080539S.D.dependentvar2948.714S.E.ofregression3065.158Akaikeinfocriterion19.03422Sumsquaredresid1.03E+08Schwarzcriterion19.12114Loglikelihood-121.7225Hannan-Quinncriter.19.01636F-statistic0.105573Durbin-Watsonstat0.493997
Prob(F-statistic)0.751337图8DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:13Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C38647.752569.91815.038510.0000X40.1559160.1134111.3747780.1966R-squared0.146626Meandependentvar42010.15AdjustedR-squared0.069047S.D.dependentvar2948.714S.E.ofregression2845.094Akaikeinfocriterion18.88522Sumsquaredresid89040158Schwarzcriterion18.97213Loglikelihood-120.7539Hannan-Quinncriter.18.86735F-statistic1.890015Durbin-Watsonstat0.865140Prob(F-statistic)0.196557图9DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:13Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C29425.912129.91813.815510.0000X50.4660810.0773956.0221060.0001R-squared0.767273Meandependentvar42010.15AdjustedR-squared0.746116S.D.dependentvar2948.714S.E.ofregression1485.765Akaikeinfocriterion17.58588Sumsquaredresid24282463Schwarzcriterion17.67280Loglikelihood-112.3083Hannan-Quinncriter.17.56802F-statistic36.26576Durbin-Watsonstat1.551952Prob(F-statistic)0.000086图10DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:14Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C-16028.2414238.56-1.1256920.2843X61.8017820.4417154.0790640.0018R-squared0.602008Meandependentvar42010.15AdjustedR-squared0.565827S.D.dependentvar2948.714S.E.ofregression1942.961Akaikeinfocriterion18.12245Sumsquaredresid41526060Schwarzcriterion18.20937Loglikelihood-115.7959Hannan-Quinncriter.18.10459F-statistic16.63876Durbin-Watsonstat0.900150
Prob(F-statistic)0.001823图11DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:23Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C-24206.5818567.18-1.3037300.2215X24.6477380.39661111.718640.0000X30.4922160.1635363.0098270.0131R-squared0.932769Meandependentvar42010.15AdjustedR-squared0.919323S.D.dependentvar2948.714S.E.ofregression837.5463Akaikeinfocriterion16.49800Sumsquaredresid7014837.Schwarzcriterion16.62838Loglikelihood-104.2370Hannan-Quinncriter.16.47121F-statistic69.37022Durbin-Watsonstat2.618267Prob(F-statistic)0.000001图12DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:24Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C32137.561166.30827.554960.0000X24.7834060.5397748.8618660.0000X4-0.0880910.048541-1.8147790.0996R-squared0.903609Meandependentvar42010.15AdjustedR-squared0.884331S.D.dependentvar2948.714S.E.ofregression1002.862Akaikeinfocriterion16.85828Sumsquaredresid10057321Schwarzcriterion16.98865Loglikelihood-106.5788Hannan-Quinncriter.16.83148F-statistic46.87216Durbin-Watsonstat2.303967Prob(F-statistic)0.000008图13DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:24Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C33449.241981.11216.884080.0000X26.5084731.9901493.2703450.0084X5-0.2761810.233876-1.1808880.2650R-squared0.887545Meandependentvar42010.15AdjustedR-squared0.865054S.D.dependentvar2948.714S.E.ofregression1083.208Akaikeinfocriterion17.01242
Sumsquaredresid11733403Schwarzcriterion17.14279Loglikelihood-107.5807Hannan-Quinncriter.16.98562F-statistic39.46238Durbin-Watsonstat2.551133Prob(F-statistic)0.000018图14DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:24Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C14578.089048.5531.6110950.1382X23.4378780.6055795.6770090.0002X60.5889540.3105891.8962470.0872R-squared0.905753Meandependentvar42010.15AdjustedR-squared0.886903S.D.dependentvar2948.714S.E.ofregression991.6488Akaikeinfocriterion16.83579Sumsquaredresid9833673.Schwarzcriterion16.96616Loglikelihood-106.4326Hannan-Quinncriter.16.80899F-statistic48.05189Durbin-Watsonstat2.862048Prob(F-statistic)0.000007图15DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:32Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C-18285.7724890.72-0.7346420.4813X24.7334400.47205410.027330.0000X30.4410920.2175562.0274870.0732X4-0.0205030.053931-0.3801670.7126R-squared0.933831Meandependentvar42010.15AdjustedR-squared0.911775S.D.dependentvar2948.714S.E.ofregression875.8469Akaikeinfocriterion16.63592Sumsquaredresid6903970.Schwarzcriterion16.80975Loglikelihood-104.1335Hannan-Quinncriter.16.60019F-statistic42.33870Durbin-Watsonstat2.551112Prob(F-statistic)0.000012图16DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:34Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C-19387.0119995.69-0.9695590.3576X25.8219831.5933053.6540300.0053X30.4582900.1729062.6505130.0265
X5-0.1456990.191196-0.7620410.4655R-squared0.936844Meandependentvar42010.15AdjustedR-squared0.915792S.D.dependentvar2948.714S.E.ofregression855.6773Akaikeinfocriterion16.58932Sumsquaredresid6589653.Schwarzcriterion16.76315Loglikelihood-103.8306Hannan-Quinncriter.16.55359F-statistic44.50128Durbin-Watsonstat2.795472Prob(F-statistic)0.000010图17DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:34Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.C-22269.1220711.67-1.0751970.3103X24.4724430.7587275.8946640.0002X30.4488400.2326001.9296660.0857X60.1031090.3731060.2763530.7885R-squared0.933334Meandependentvar42010.15AdjustedR-squared0.911113S.D.dependentvar2948.714S.E.ofregression879.1292Akaikeinfocriterion16.64340Sumsquaredresid6955813.Schwarzcriterion16.81723Loglikelihood-104.1821Hannan-Quinncriter.16.60767F-statistic42.00078Durbin-Watsonstat2.679392Prob(F-statistic)0.000013图18DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:17:42Sample:19831995Includedobservations:13VariableCoefficientStd.Errort-StatisticProb.X24.4422350.37533911.835260.0000X30.2792840.00856432.612900.0000R-squared0.921341Meandependentvar42010.15AdjustedR-squared0.914191S.D.dependentvar2948.714S.E.ofregression863.7738Akaikeinfocriterion16.50114Sumsquaredresid8207158.Schwarzcriterion16.58805Loglikelihood-105.2574Hannan-Quinncriter.16.48327Durbin-Watsonstat2.680964图19DependentVariable:YMethod:LeastSquaresDate:12/20/09Time:23:59Sample:160Includedobservations:60VariableCoefficientStd.Errort-StatisticProb.
C9.3475223.6384372.5691040.0128X0.6370690.01990332.008810.0000R-squared0.946423Meandependentvar119.6667AdjustedR-squared0.945500S.D.dependentvar38.68984S.E.ofregression9.032255Akaikeinfocriterion7.272246Sumsquaredresid4731.735Schwarzcriterion7.342058Loglikelihood-216.1674Hannan-Quinncriter.7.299553F-statistic1024.564Durbin-Watsonstat1.790431Prob(F-statistic)0.000000图20DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:10:26Sample:160Includedobservations:60Weightingseries:1/RESIDVariableCoefficientStd.Errort-StatisticProb.C10.205070.35693328.591030.0000X0.6331700.001700372.51350.0000WeightedStatisticsR-squared0.999582Meandependentvar120.4524AdjustedR-squared0.999575S.D.dependentvar931.0901S.E.ofregression1.729654Akaikeinfocriterion3.966484Sumsquaredresid173.5187Schwarzcriterion4.036296Loglikelihood-116.9945Hannan-Quinncriter.3.993792F-statistic138766.3Durbin-Watsonstat0.192262Prob(F-statistic)0.000000UnweightedStatisticsR-squared0.946365Meandependentvar119.6667AdjustedR-squared0.945441S.D.dependentvar38.68984S.E.ofregression9.037146Sumsquaredresid4736.860Durbin-Watsonstat1.794290图21DependentVariable:LOG(Y)Method:LeastSquaresDate:12/21/09Time:10:41Sample:160Includedobservations:60VariableCoefficientStd.Errort-StatisticProb.C0.1401990.1335721.0496170.2982LOG(X)0.9015470.02616834.452160.0000R-squared0.953412Meandependentvar4.730314AdjustedR-squared0.952609S.D.dependentvar0.339103S.E.ofregression0.073821Akaikeinfocriterion-2.341577Sumsquaredresid0.316075Schwarzcriterion-2.271765Loglikelihood72.24731Hannan-Quinncriter.-2.314270F-statistic1186.951Durbin-Watsonstat1.947104Prob(F-statistic)0.000000
图22DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:11:02Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.C192.9944990.98450.1947500.8480X0.0319000.0083293.8300440.0015R-squared0.478305Meandependentvar3056.861AdjustedR-squared0.445699S.D.dependentvar3705.973S.E.ofregression2759.150Akaikeinfocriterion18.78767Sumsquaredresid1.22E+08Schwarzcriterion18.88660Loglikelihood-167.0890Hannan-Quinncriter.18.80131F-statistic14.66924Durbin-Watsonstat3.015597Prob(F-statistic)0.001476图23DependentVariable:RMethod:LeastSquaresDate:12/21/09Time:11:23Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.C578.5686678.69490.8524720.4065X0.0119390.0057042.0930560.0526R-squared0.214951Meandependentvar1650.427AdjustedR-squared0.165885S.D.dependentvar2069.045S.E.ofregression1889.657Akaikeinfocriterion18.03062Sumsquaredresid57132855Schwarzcriterion18.12955Loglikelihood-160.2756Hannan-Quinncriter.18.04426F-statistic4.380883Durbin-Watsonstat1.743304Prob(F-statistic)0.052634图24DependentVariable:RMethod:LeastSquaresDate:12/21/09Time:12:02Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.SQRX6.4435141.4112684.5657620.0003R-squared0.248189Meandependentvar1650.427AdjustedR-squared0.248189S.D.dependentvar2069.045S.E.ofregression1794.007Akaikeinfocriterion17.87624Sumsquaredresid54713861Schwarzcriterion17.92571Loglikelihood-159.8862Hannan-Quinncriter.17.88306Durbin-Watsonstat1.742094图25DependentVariable:R
Method:LeastSquaresDate:12/21/09Time:12:06Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.X19589750.126400820.7586780.4584R-squared-0.618902Meandependentvar1650.427AdjustedR-squared-0.618902S.D.dependentvar2069.045S.E.ofregression2632.572Akaikeinfocriterion18.64326Sumsquaredresid1.18E+08Schwarzcriterion18.69273Loglikelihood-166.7894Hannan-Quinncriter.18.65008Durbin-Watsonstat0.794335图26DependentVariable:RMethod:LeastSquaresDate:12/21/09Time:11:26Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.X0.0156080.0037134.2034670.0006R-squared0.179294Meandependentvar1650.427AdjustedR-squared0.179294S.D.dependentvar2069.045S.E.ofregression1874.406Akaikeinfocriterion17.96392Sumsquaredresid59727790Schwarzcriterion18.01339Loglikelihood-160.6753Hannan-Quinncriter.17.97074Durbin-Watsonstat1.713357图27DependentVariable:RMethod:LeastSquaresDate:12/21/09Time:12:01Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.1/SQRX174610.9104554.51.6700470.1132R-squared-0.437823Meandependentvar1650.427AdjustedR-squared-0.437823S.D.dependentvar2069.045S.E.ofregression2480.977Akaikeinfocriterion18.52465Sumsquaredresid1.05E+08Schwarzcriterion18.57411Loglikelihood-165.7218Hannan-Quinncriter.18.53147Durbin-Watsonstat0.894315图28DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:12:38Sample:118Includedobservations:18Weightingseries:1/X
VariableCoefficientStd.Errort-StatisticProb.C-243.4910135.2946-1.7997090.0908X0.0366980.0066425.5254750.0000WeightedStatisticsR-squared0.656142Meandependentvar929.6678AdjustedR-squared0.634651S.D.dependentvar738.5199S.E.ofregression694.2181Akaikeinfocriterion16.02789Sumsquaredresid7711020.Schwarzcriterion16.12682Loglikelihood-142.2510Hannan-Quinncriter.16.04153F-statistic30.53087Durbin-Watsonstat2.643088Prob(F-statistic)0.000046UnweightedStatisticsR-squared0.467483Meandependentvar3056.861AdjustedR-squared0.434201S.D.dependentvar3705.973S.E.ofregression2787.620Sumsquaredresid1.24E+08Durbin-Watsonstat2.963758图29DependentVariable:LOG(Y)Method:LeastSquaresDate:12/21/09Time:12:43Sample:118Includedobservations:18VariableCoefficientStd.Errort-StatisticProb.C-7.3646981.847999-3.9852290.0011LOG(X)1.3222400.1680377.8687330.0000R-squared0.794653Meandependentvar7.109988AdjustedR-squared0.781819S.D.dependentvar1.606121S.E.ofregression0.750216Akaikeinfocriterion2.367529Sumsquaredresid9.005196Schwarzcriterion2.466459Loglikelihood-19.30776Hannan-Quinncriter.2.381170F-statistic61.91696Durbin-Watsonstat2.398776Prob(F-statistic)0.000001图30DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:13:11Sample:120Includedobservations:20VariableCoefficientStd.Errort-StatisticProb.C4.6102821.0849064.2494780.0005X0.7574330.1499415.0515590.0001R-squared0.586380Meandependentvar8.530000AdjustedR-squared0.563402S.D.dependentvar5.131954S.E.ofregression3.390969Akaikeinfocriterion5.374748Sumsquaredresid206.9761Schwarzcriterion5.474321Loglikelihood-51.74748Hannan-Quinncriter.5.394186F-statistic25.51825Durbin-Watsonstat2.607212Prob(F-statistic)0.000083
图31DependentVariable:LOG(Y)Method:LeastSquaresDate:12/21/09Time:13:12Sample:120Includedobservations:20VariableCoefficientStd.Errort-StatisticProb.C1.3226240.3676533.5974800.0021LOG(X)0.4578650.2393111.9132590.0718R-squared0.168997Meandependentvar1.982564AdjustedR-squared0.122830S.D.dependentvar0.607609S.E.ofregression0.569070Akaikeinfocriterion1.805014Sumsquaredresid5.829139Schwarzcriterion1.904587Loglikelihood-16.05014Hannan-Quinncriter.1.824452F-statistic3.660559Durbin-Watsonstat2.643006Prob(F-statistic)0.071757图32DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:13:35Sample:120IFX<=26Includedobservations:19VariableCoefficientStd.Errort-StatisticProb.C6.7380822.3848602.8253580.0117X0.2214840.5555680.3986630.6951R-squared0.009262Meandependentvar7.636842AdjustedR-squared-0.049016S.D.dependentvar3.310457S.E.ofregression3.390619Akaikeinfocriterion5.379203Sumsquaredresid195.4371Schwarzcriterion5.478618Loglikelihood-49.10243Hannan-Quinncriter.5.396028F-statistic0.158932Durbin-Watsonstat2.656146Prob(F-statistic)0.695105图33DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:15:10Sample:112Includedobservations:12VariableCoefficientStd.Errort-StatisticProb.C4.7171989.1257550.5169100.6237X10.0396150.0272701.4526970.1965X2-0.0368950.077705-0.4748130.6517X30.2632560.5494760.4791040.6488X40.0134630.0049632.7129970.0350X50.0254690.0156631.6259930.1551R-squared0.974539Meandependentvar96.62750AdjustedR-squared0.953321S.D.dependentvar77.06446S.E.ofregression16.65001Akaikeinfocriterion8.769552
Sumsquaredresid1663.338Schwarzcriterion9.012005Loglikelihood-46.61731Hannan-Quinncriter.8.679787F-statistic45.93047Durbin-Watsonstat1.969898Prob(F-statistic)0.000105图34DependentVariable:YMethod:LeastSquaresDate:12/21/09Time:15:59Sample:112Includedobservations:12Weightingseries:1/BVariableCoefficientStd.Errort-StatisticProb.X31.0374460.1885275.5029030.0004X40.0089590.0020874.2936450.0020X50.0211620.0080892.6162610.0280WeightedStatisticsR-squared0.992089Meandependentvar82.95636AdjustedR-squared0.990332S.D.dependentvar239.5237S.E.ofregression17.52356Akaikeinfocriterion8.777287Sumsquaredresid2763.675Schwarzcriterion8.898514Loglikelihood-49.66372Hannan-Quinncriter.8.732405Durbin-Watsonstat0.474622UnweightedStatisticsR-squared0.959618Meandependentvar96.62750AdjustedR-squared0.950644S.D.dependentvar77.06446S.E.ofregression17.12075Sumsquaredresid2638.082Durbin-Watsonstat1.923690计量经济学(庞浩)第二版第五章练习题及参考解答5.1设消费函数为YXXui122i33ii式中,Y为消费支出;X为个人可支配收入;X为个人的流动资产;u为随机误差i2i3ii222项,并且E(u)0,Var(u)X(其中为常数)。试解答以下问题:ii2i(1)选用适当的变换修正异方差,要求写出变换过程;(2)写出修正异方差后的参数估计量的表达式。练习题5.1参考解答:21(1)因为f(X)X,所以取W,用W乘给定模型两端,得i2i2i2iX2i
Y1Xui3ii123XXXX2i2i2i2i上述模型的随机误差项的方差为一固定常数,即ui12Var()Var(u)2iXX2i2i(2)根据加权最小二乘法,可得修正异方差后的参数估计式为ˆY*ˆX*ˆX*12233***2****ˆW2iyix2iW2ix3iW2iyix3iW2ix2ix3i22*2*2**W2ix2iW2ix3iW2ix2ix3i***2****ˆW2iyix3iW2ix2iW2iyix2iW2ix2ix3i32*2*2**W2ix2iW2ix3iW2ix2ix3i其中*W2iX2i*W2iX3i*W2iYiX,X,Y23W2iW2iW2i******xXXxXXyYY2i2i23i3i3i5.2下表是消费Y与收入X的数据,试根据所给数据资料完成以下问题:(1)估计回归模型YXu中的未知参数和,并写出样本回归模1212型的书写格式;(2)试用Goldfeld-Quandt法和White法检验模型的异方差性;(3)选用合适的方法修正异方差。表5.8某地区消费Y与收入X的数据(单位:亿元)YXYXYX5580152220951406510014421010814570851752451131508011018026011016079120135190125165841151402051151809813017826513018595140191270135190901251372301202007590189250140205
7410555801402101101607085152220113150759014022512516565100137230108145741051452401151808011017524514022584115189250120200791201802601452409012517826513018598130191270练习题5.2参考解答:(1)该模型样本回归估计式的书写形式为Yˆ9.347522+0.637069Xiit=(2.569104)(32.00881)22R=0.946423R=0.945500F=1024.564DW=1.790431(2)首先,用Goldfeld-Quandt法进行检验。将样本X按递增顺序排序,去掉中间1/4的样本,再分为两个部分的样本,即nn2212。分别对两个部分的样本求最小二乘估计,得到两个部分的残差平方和,即2e1603.01482e22495.840求F统计量为2e22495.84F4.13902e1603.0148给定0.05,查F分布表,得临界值为F(20,20)2.12。0.05c.比较临界值与F统计量值,有F=4.1390>F(20,20)2.12,说明该模型的随机0.05误差项存在异方差。其次,用White法进行检验。具体结果见下表WhiteHeteroskedasticityTest:F-statistic6.301373Probability0.003370Obs*R-squared10.86401Probability0.004374TestEquation:DependentVariable:RESID^2Method:LeastSquaresDate:08/05/05Time:12:37Sample:160Includedobservations:60VariableCoefficientStd.Errort-StatisticProb.
C-10.03614131.1424-0.0765290.9393X0.1659771.6198560.1024640.9187X^20.0018000.0045870.3924690.6962R-squared0.181067Meandependentvar78.86225AdjustedR-squared0.152332S.D.dependentvar111.1375S.E.ofregression102.3231Akaikeinfocriterion12.14285Sumsquaredresid596790.5Schwarzcriterion12.24757Loglikelihood-361.2856F-statistic6.301373Durbin-Watsonstat0.937366Prob(F-statistic)0.0033702给定0.05,在自由度为2下查卡方分布表,得5.9915。比较临界值与卡方22统计量值,即nR10.86405.9915,同样说明模型中的随机误差项存在异方差。1(2)用权数W1,作加权最小二乘估计,得如下结果XDependentVariable:YMethod:LeastSquaresDate:08/05/05Time:13:17Sample:160Includedobservations:60Weightingseries:W1VariableCoefficientStd.Errort-StatisticProb.C10.370512.6297163.9435870.0002X0.6309500.01853234.046670.0000WeightedStatisticsR-squared0.211441Meandependentvar106.2101AdjustedR-squared0.197845S.D.dependentvar8.685376S.E.ofregression7.778892Akaikeinfocriterion6.973470Sumsquaredresid3509.647Schwarzcriterion7.043282Loglikelihood-207.2041F-statistic1159.176Durbin-Watsonstat0.958467Prob(F-statistic)0.000000UnweightedStatisticsR-squared0.946335Meandependentvar119.6667AdjustedR-squared0.945410S.D.dependentvar38.68984S.E.ofregression9.039689Sumsquaredresid4739.526Durbin-Watsonstat0.800564用White法进行检验得如下结果:WhiteHeteroskedasticityTest:F-statistic3.138491Probability0.050925Obs*R-squared5.951910Probability0.0509992给定0.05,在自由度为2下查卡方分布表,得5.9915。比较临界值与卡方22统计量值,即nR5.951910<5.9915,说明加权后的模型中的随机误差项不存在异方差。其估计的书写形式为
Yˆ10.37050.6309Xt(3.943587)(34.04667)22R0.211441R=0.197845DW=0.958467F=1159.1765.3下表是2007年我国各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据表5.9各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据(单位:元)家庭人均纯收家庭生活消费家庭人均纯收家庭生活消费地区地区入支出入支出北京9439.636399.27湖北3997.483090天津7010.063538.31湖南3904.23377.38河北4293.432786.77广东5624.044202.32山西3665.662682.57广西3224.052747.47内蒙古3953.13256.15海南3791.372556.56辽宁4773.433368.16重庆3509.292526.7吉林4191.343065.44四川3546.692747.27黑龙江4132.293117.44贵州2373.991913.71上海10144.628844.88云南2634.092637.18江苏6561.014786.15西藏2788.22217.62浙江8265.156801.6陕西2644.692559.59安徽3556.272754.04甘肃2328.922017.21福建5467.084053.47青海2683.782446.5江西4044.72994.49宁夏3180.842528.76山东4985.343621.57新疆3182.972350.58河南3851.62676.41(1)试根据上述数据建立2007年我国农村居民家庭人均消费支出对人均纯收入的线性回归模型。(2)选用适当方法检验模型是否在异方差,并说明存在异方差的理由。(3)如果存在异方差,用适当方法加以修正。练习题5.3参考解答:解:(1)建立样本回归函数。Yˆ179.1916+0.7195X(0.808709)(15.74411)2R0.895260,F=247.8769(2)利用White方法检验异方差,则White检验结果见下表:HeteroskedasticityTest:WhiteF-statistic7.194463Prob.F(2,28)0.0030Obs*R-squared10.52295Prob.Chi-Square(2)0.0052
ScaledexplainedSS30.08105Prob.Chi-Square(2)0.0000由上述结果可知,该模型存在异方差。分析该模型存在异方差的理由是,从数据可以看出,一是截面数据;二是各省市经济发展不平衡,使得一些省市农村居民收入高出其它省市很多,如上海市、北京市、天津市和浙江省等。而有的省就很低,如甘肃省、贵州省、云南省和陕西省等。111(3)用加权最小二乘法修正异方差,分别选择权数w1,w2,w3,2XXX经过试算,认为用权数w3的效果最好。结果如下:书写结果为Yˆ787.28470.5615X(4.5325)(10.0747)2R0.9461,F101.49925.4下表是某一地区31年中个人储蓄和个人收入数据资料表5.10个人储蓄和个人收入数据(单位:元)时期储蓄额(Y)收入额(X)时期储蓄额(Y)收入额(X)12648777171578241272105921018165425604390995419140026500413110508201829276705122109792122002830061071191222201727430
740612747232105295608503134992416002815094311426925225032100105881552226242032500118981673027257035250129501766328172033500137791857529190036000148191963530210036200151222211633123003820016170222880(1)建立一元回归函数,判断有无异方差存在,并说明存在异方差的原因。(2)用适当方法修正异方差。练习题5.4参考解答:(1)建立样本回归函数。Yˆ-648.1236+0.0847X(-5.485018)(17.34164)2R0.912050,F=300.7324从估计的结果看,各项检验指标均显著。但由于收入通常存在不同的差异,因此需要判断模型是否存在异方差。首先,用图形法。从残差平方对解释变量散点图可以看出(见下图),模型很可能存在异方差。其次,用运用Goldfeld-Quanadt检验异方差。第一,对变量X取值以升序排序。第二,构造子样本。由于本例的样本容量为31,删除1/4观测值,约7个,余下部分
分得两个样本区间:1—12和20—31,它们的样本个数均是12个。2第三,在样本区为1—12,所计算得到的残茶平方和为e1i162899.2;在样本区2为20—31,所计算得到的残茶平方和为e2i981744.6。2e2i981744.6第四,根据Goldfeld-Quanadt检验,F统计量为F6.0267。2e1i162899.2第五,判断。在显著性水平为0.05条件下,分子分母的自由度均为10,查F分布表得临界值为F(10,10)2.98,因为F6.0267F(10,10)2.98,所以拒绝原假设,0.050.05表明模型存在异方差。最后,用ARCH方法检验异方差,则ARCH检验结果见下表:HeteroskedasticityTest:ARCHF-statistic6.172299Prob.F(1,28)0.0192Obs*R-squared5.418686Prob.Chi-Square(1)0.0199由上述结论可知,拒绝原假设,则模型中随机误差项存在异方差。111(2)分别用权数w1,w2,w3,发现用权数w2求加权最小二乘估2XXX计效果最好,即Yˆ706.69860.0873X(8.0399)(20.1399)2R0.8735,F405.61645.5下表的数据是2007年我国建筑业总产值(X)和建筑业企业利润总额(Y)。试根据资料建立回归模型,并对模型判断是否存在异方差,如果有异方差,选用适当方法修正。表5.11各地区建筑业总产值(X)和建筑业企业利润总额(Y)(单位:万元)建筑业总产值建筑业企业利建筑业总产值建筑业企业利地区地区x润总额yx润总额y北京25767692960256.4湖北21108043698837.4天津12219419379211.6湖南18288148545655.7河北16146909446520.8广东299951401388554.6山西10607041194565.9广西6127370126343.1
内蒙古6811038.3353362.6海南82183414615.7辽宁21000402836846.6重庆11287118386177.5吉林7383390.8102742四川21099840466176黑龙江8758777.898028.5贵州3487908.141893.1上海25241801794136.5云南7566795.1266333.1江苏701057242368711.7西藏602940.752895.2浙江697170521887291.7陕西11730972224646.6安徽15169772378252.8甘肃4369038.8152143.1福建15441660375531.9青海1254431.124468.3江西7861403.8188502.4宁夏1549486.525224.6山东328904501190084.1新疆4508313.768276.6河南21517230574938.7数据来源:国家统计局网站练习题5.5参考解答:(1)求Y对X的回归,得如下估计结果Yˆ28992.820.0323X(0.8009)(20.8233)2R0.9373,F433.6077用怀特检验的修正方法,即建立如下回归模型e2YˆYˆ2vi12i3ii通过计算得到如下结果:2注意,表中E2为残差平方e。t即eˆ26.34(E09)65144.33Yˆ0.0138Yˆ2iii对该模型系数作判断,运用F或LM检验,可发现存在异方差。22具体EViews操作如下:在得到Y的估计Yˆ后,进一步得到残差平方e,然后建立e对Yˆii
和Yˆ2的线性回归模型。再通过上述回归对Yˆ和Yˆ2前的系数是否为零进行判断,从而检验原模型中是否存在异方差。在上表界面,按路径:VIEW/COEFFIEICENTTESTS/REDUANDANTVARIABLES,得到如下窗口,并输入变量名“YFYF^2”,即然后“OK”即得到检验结果为从表中F统计量值和LM统计量值看,拒绝原假设,表明原模型存在异方差。1(2)通过对权数的试算,最后选择权数w,用加权最小二乘法得到如下估计lX(还原后的结果)
Yˆ9038.8750.0311X(0.5912)(17.6011)2R0.9144,F309.7983,DW2.0975对该模型进行检验,发现已无异方差。5.6下表为四川省农村人均纯收入、人均生活费支出、商品零售价格指数1978年至2008年时间序列数据。试根据该资料建立回归模型,并检验是否存在异方差,如果存在异方差,选用适当方法进行修正。表5.121978——2008四川省农村人均纯收入、人均生活费支出、商品零售价格指数时间农村人均农村人商品零售时间农村人均农村人商品零售纯收入X均生活消价格指数纯收入X均生活消价格指数费支出Y费支出Y1978127.1120.31001994946.33904.28310.21979155.9142.110219951158.291092.91356.11980187.9159.5108.119961453.421349.88377.81981221184110.719971680.691440.48380.81982256208.23112.819981731.761440.77370.91983258.4231.12114.519991843.471426.06359.81984286.8251.83117.720001903.601485.34354.41985315.07276.25128.120011986.991497.52351.61986337.9310.92135.820022107.641591.993471987369.46348.32145.720032229.861747.02346.71988448.85426.47172.720042580.282010.88356.41989494.07473.59203.420052802.782274.17359.31990557.76509.16207.720063002.382395.04362.91991590.21552.39213.720073546.692747.27376.71992634.31569.46225.220084121.23127.9398.91993698.27647.43254.9资料来源:中经网统计数据库练习题5.6参考解答:(1)设Y表示人均生活费支出,X表示农村人均纯收入,则建立样本回归函数^Y71.61407+0.761445X(3.944029)(69.98227)
2R0.994113,F=4897.518从估计结果看,各项检验指标均显著,但从经济意义看,改革开放以来,四川省农村经济发生了巨大变化,农村家庭纯收入的差距也有所拉大,使得农村居民的消费水平的差距也有所加大,在这种情况下,尽管是时间序列数据,也有可能存在异方差问题。而且从残差平方对解释变量的散点图可以看出,模型很可能存在异方差(见下图)。进一步作利用ARCH方法检验异方差,得ARCH检验结果(见下表)1(2)运用加权最小二乘法,选权数为w,得如下结果X^Y35.69419+0.789972X(3.435081)(59.91014)2R0.991985,F=3589.224经检验,时模型的异方差问题有了明显的改进。5.7在5.6题的数据表里,如果考虑物价因素,则对异方差性的修正应该怎样进行?练习题5.7参考解答:
剔除物价上涨因素后的回归结果如下Yˆ0.4310010.727487X11t(6.888037)(55.52690)22R0.990682R0.990361F=3083.237其中,Y代表实际消费支出,X代表实际可支配收入。11用ARCH方法来检验模型是否存在异方差:在显著性水平为0.01的条件下,接收原假设,模型不存在异方差。表明剔除物价上涨因素之后,异方差的问题有所改善。计量经济学(庞浩)第二版第六章练习题及参考解答6.1下表给出了美国1960-1995年36年间个人实际可支配收入X和个人实际消费支出Y的数据。表6.6美国个人实际可支配收入和个人实际消费支出(单位:百亿美元)个人实际可个人实际个人实际可个人实际年份支配收入消费支出年份支配收入消费支出XYXY196015714319783262951961162146197933530219621691531980337301196317616019813453051964188169198234830819652001801983358324196621119019843843411967220196198539635719682302071986409371196923721519874153821970247220198843239719712562281989440406197226824219904484131973287253199144941119742852511992461422197529025719934674341976301271199447844719773112831995493458注:资料来源于EconomicReportofthePresident,数据为1992年价格。要求:(1)用普通最小二乘法估计收入—消费模型;
YXut122t(2)检验收入—消费模型的自相关状况(5%显著水平);(3)用适当的方法消除模型中存在的问题。练习题6.1参考解答:(1)收入—消费模型为Yˆ9.42870.9359XttSe=(2.5043)(0.0075)t=(-3.7650)(125.3411)R2=0.9978,F=15710.39,df=34,DW=0.5234(2)对样本量为36、一个解释变量的模型、5%显著水平,查DW统计表可知,dL=1.411,dU=1.525,模型中DWdU,说明2广义差分模型中已无自相关。同时,可决系数R、t、F统计量均达到理想水平。ˆ3.783113.9366110.72855最终的消费模型为Yt=13.9366+0.9484Xt6.2在研究生产中劳动所占份额的问题时,古扎拉蒂采用如下模型模型1Ytut01t2模型2Yttut012t其中,Y为劳动投入,t为时间。据1949-1964年数据,对初级金属工业得到如下结果:模型1Yˆ0.45290.0041tt
t=(-3.9608)R2=0.5284DW=0.82522模型2Yˆ0.47860.0127t0.0005ttt=(-3.2724)(2.7777)R2=0.6629DW=1.82其中,括号内的数字为t统计量。问:(1)模型1和模型2中是否有自相关;(2)如何判定自相关的存在?(3)怎样区分虚假自相关和真正的自相关。练习题6.2参考解答:(1)模型1中有自相关,模型2中无自相关。(2)通过DW检验进行判断。模型1:dL=1.077,dU=1.361,DWdU,因此无自相关。(3)如果通过改变模型的设定可以消除自相关现象,则为虚假自相关,否则为真正自相关。6.3下表是北京市连续19年城镇居民家庭人均收入与人均支出的数据。表6.7北京市19年来城镇居民家庭收入与支出数据表(单位:元)年份人均收入人均生活消商品零售人均实人均实际顺序(元)费支出(元)物价指数(%)际收入(元)消费支出(元)1450.18359.86100.00450.18359.862491.54408.66101.50484.28402.623599.40490.44108.60551.93451.604619.57511.43110.20562.22464.095668.06534.82112.30594.89476.2467716.60574.06113.00634.16508.028837.65666.75115.40725.87577.7791158.84923.32136.80847.11674.94101317.331067.38145.90902.90731.58111413.241147.60158.60891.07723.58121767.671455.55193.30914.47753.00131899.571520.41229.10829.14663.64142067.331646.05238.50866.81690.1715162359.881860.17258.80911.85718.77172813.102134.65280.301003.60761.56183935.392939.60327.701200.91897.04195585.884134.12386.401445.621069.916748.685019.76435.101551.061153.707945.785729.45466.901701.821227.13要求:(1)建立居民收入—消费函数;(2)检验模型中存在的问题,并采取适当的补救措施预以处理;(3)对模型结果进行经济解释。
练习题6.3参考解答:(1)收入—消费模型为Yˆ79.9300.690X(6.38)ttSe(12.399)(0.013)t(6.446)(53.621)2R0.994DW0.575(2)DW=0.575,取5%,查DW上下界d1.18,d1.40,DW1.18,LU说明误差项存在正自相关。(3)采用广义差分法使用普通最小二乘法估计的估计值ˆ,得e0.657ett1Se(0.178)t(3.701)**Yˆ36.0100.669XttSe(8.105)(0.021)t(4.443)(32.416)2R0.985DW1.830DW=1.830,已知d1.40,dDW2。因此,在广义差分模型中已无自相关。据UUˆ(1ˆ)36.010,可得:1ˆ36.010104.985110.657因此,原回归模型应为Y104.9850.669Xtt其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加0.669元。6.4下表给出了日本工薪家庭实际消费支出与可支配收入数据表6.8日本工薪家庭实际消费支出与实际可支配收入单位:1000日元个人实际可个人实际个人实际可个人实际年份年份支配收入消费支出支配收入消费支出
XYXY1970239300198330438419712483111984308392197225832919853104001973272351198631240319742683541987314411197528036419883244281976279360198932643419772823661990332441197828537019913344491979293378199233645119802913741993334449198129437119943304491982302381注:资料来源于日本银行《经济统计年报》数据为1990年价格。要求:(1)建立日本工薪家庭的收入—消费函数;(2)检验模型中存在的问题,并采取适当的补救措施预以处理;(3)对模型结果进行经济解释。要求:(1)检测进口需求模型YXu的自相关性;t12tt(2)采用科克伦-奥克特迭代法处理模型中的自相关问题。练习题6.4参考解答:(1)收入—消费模型为Yˆ50.87450.6334Xttt=(6.1361)(30.0085)R2=0.9751DW=0.3528(2)对样本量为25、一个解释变量的模型、5%显著水平,查DW统计表可知,dL=1.288,dU=1.454,模型中DWdU,说明
广义差分模型中已无自相关。ˆ13.978493.7518110.8509最终的消费模型为Yt=93.7518+0.5351Xt(3)模型说明日本工薪居民的边际消费倾向为0.5351,即收入每增加1元,平均说来消费增加0.54元。6.5下表给出了某地区1980-2000年的地区生产总值(Y)与固定资产投资额(X)的数据。表6.9地区生产总值(Y)与固定资产投资额(X)单位:亿元地区生产固定资产地区生产固定资产年份年份总值(Y)投资额(X)总值(Y)投资额(X)19903124544198014022161991315852319811624254199235785481982138218719934067668198312851511994448369919841665246199548977451985208036819965120667198623754171997550684519872517412199860889511988274143819997042118519892730436200087561180要求:(1)使用对数线性模型LnYLnXu进行回归,并检验回归模型t12tt的自相关性;(2)采用广义差分法处理模型中的自相关问题。**(3)令XX/X(固定资产投资指数),YY/Y(地区生产总值增长指ttt1ttt1**数),使用模型LnYLnXv,该模型中是否有自相关?t12tt练习题6.5参考解答:(1)对数模型为ln(Y)=2.1710+0.9511ln(X)t=(9.0075)(24.4512)R2=0.9692DW=1.1598样本量n=21,一个解释变量的模型,5%显著水平,查DW统计表可知,dL=1.221,dU=1.420,模型中DWdU,说明广义差分模型中已无自相关。ˆ1.47722.4628110.4002最终的模型为Ln(Yt)=-2.468+0.9060ln(Xt)(3)回归模型为ln(Yt/Yt-1)=0.054+0.4422ln(Xt/Xt-1)t(4.0569)(6.6979)R2=0.7137DW=1.5904模型中DW=1.5904>dU,说明广义差分模型中已无自相关。'
您可能关注的文档
- 计算机网络试题库(含答案).doc
- 计算机网络课后习题答案.doc
- 计算机网络课后答案(第5版).doc
- 计算机网络课后答案_谢希仁.doc
- 计算机英语(第4版)课文翻译与课后答案.doc
- 计量练习部分答案.doc
- 计量经济学 庞皓 第三版课后答案.docx
- 计量经济学(庞浩)第二版 科学出版社 课后答案 二章.doc
- 庞浩)第二版_科学出版社_课后答案详解.doc
- 计量经济学(庞浩)第二版课后习题答案(1).doc
- 计量经济学(庞皓)_课后习题答案.pdf
- 量经济学书后答案__书第1-10章.doc
- 计量经济学第二版课后习题答案.docx
- 计量经济学答案 南开大学 张晓峒.doc
- 计量经济学题库(超完整版)及答案.doc
- 许同乐 课后习题及答案.pdf
- 许咨宗《核与粒子物理导论》习题解答.pdf
- 许振宇《计量经济学原理与应用》闯关习题答案.doc
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明