

- 1.59 MB
- 2022-04-22 11:50:23 发布
- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
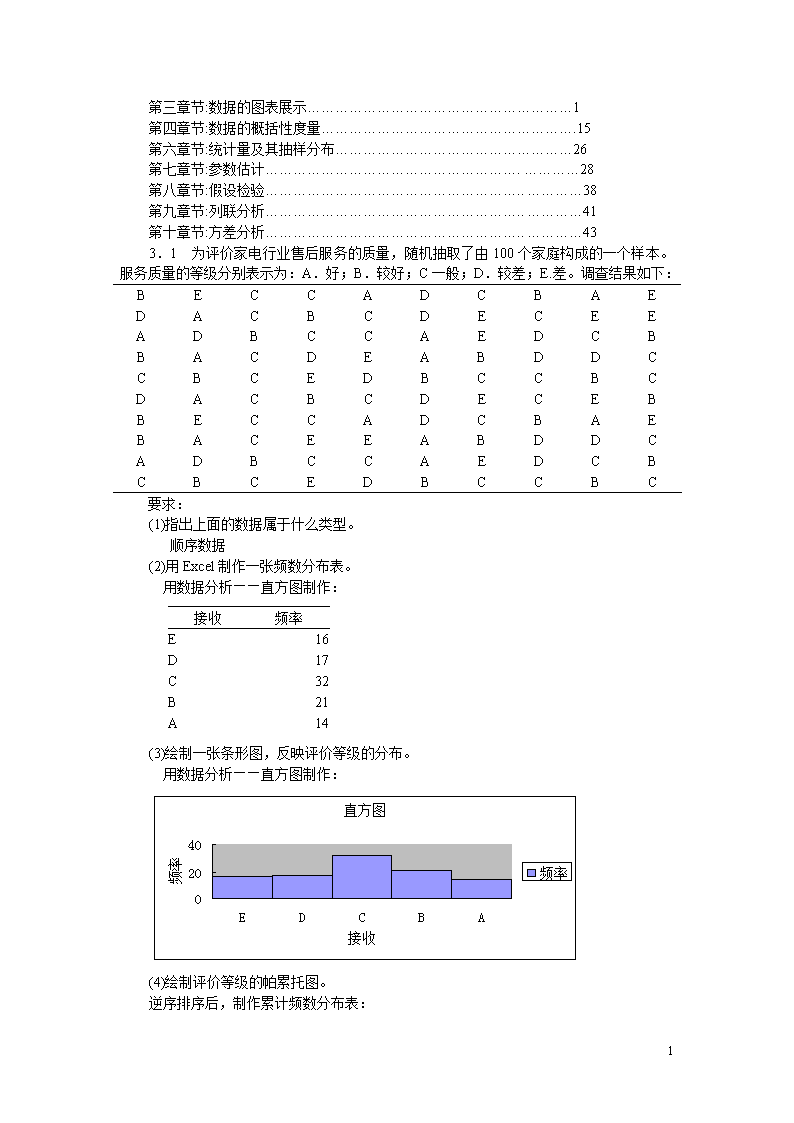
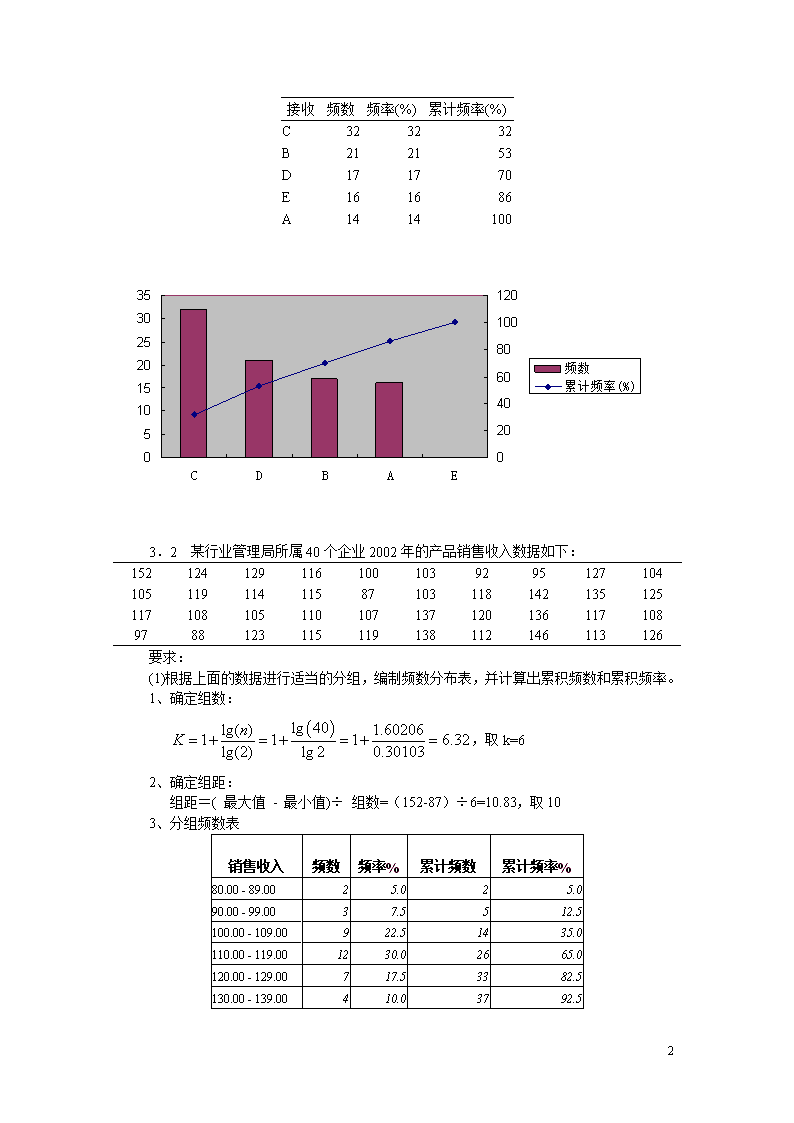
'第三章节:数据的图表展示…………………………………………………1第四章节:数据的概括性度量……………………………………………….15第六章节:统计量及其抽样分布……………………………………………26第七章节:参数估计……………………………………………….…………28第八章节:假设检验………………………………………………..…………38第九章节:列联分析………………………………………………..…………41第十章节:方差分析………………………………………………..…………433.1为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下:BECCADCBAEDACBCDECEEADBCCAEDCBBACDEABDDCCBCEDBCCBCDACBCDECEBBECCADCBAEBACEEABDDCADBCCAEDCBCBCEDBCCBC要求:(1)指出上面的数据属于什么类型。顺序数据(2)用Excel制作一张频数分布表。用数据分析——直方图制作:接收频率E16D17C32B21A14(3)绘制一张条形图,反映评价等级的分布。用数据分析——直方图制作:(4)绘制评价等级的帕累托图。逆序排序后,制作累计频数分布表:43
接收频数频率(%)累计频率(%)C323232B212153D171770E161686A14141003.2某行业管理局所属40个企业2002年的产品销售收入数据如下:1521241291161001039295127104105119114115871031181421351251171081051101071371201361171089788123115119138112146113126要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。1、确定组数:,取k=62、确定组距:组距=(最大值-最小值)÷组数=(152-87)÷6=10.83,取103、分组频数表销售收入频数频率%累计频数累计频率%80.00-89.0025.025.090.00-99.0037.5512.5100.00-109.00922.51435.0110.00-119.001230.02665.0120.00-129.00717.53382.5130.00-139.00410.03792.543
140.00-149.0025.03997.5150.00+12.540100.0总和40100.0 (2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。 频数频率%累计频数累计频率%先进企业1025.01025.0良好企业1230.02255.0一般企业922.53177.5落后企业922.540100.0总和40100.0 3.3某百货公司连续40天的商品销售额如下:单位:万元41252947383430384340463645373736454333443528463430374426384442363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。1、确定组数:,取k=62、确定组距:组距=(最大值-最小值)÷组数=(49-25)÷6=4,取53、分组频数表销售收入(万元)频数频率%累计频数累计频率%<=2512.512.526-30512.5615.031-35615.01230.036-401435.02665.041-451025.03690.046+410.040100.0总和40100.0 43
3.4利用下面的数据构建茎叶图和箱线图。57292936312347232828355139184618265029332146415228214319422043
dataStem-and-LeafPlotFrequencyStem&Leaf3.001.8895.002.011337.002.68889992.003.133.003.5693.004.1233.004.6673.005.0121.005.7Stemwidth:10Eachleaf:1case(s)3.6一种袋装食品用生产线自动装填,每袋重量大约为50g,但由于某些原因,每袋重量不会恰好是50g。下面是随机抽取的100袋食品,测得的重量数据如下:单位:g574649545558496151495160525451556056474743
5351485350524045575352514648475347534447505253474548545248464952595350435346574949445752424943474648515945454652554749505447484457475358524855535749565657534148要求:(1)构建这些数据的频数分布表。(2)绘制频数分布的直方图。(3)说明数据分布的特征。解:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。1、确定组数:,取k=6或72、确定组距:组距=(最大值-最小值)÷组数=(61-40)÷6=3.5,取3或者4、5组距=(最大值-最小值)÷组数=(61-40)÷7=3,3、分组频数表组距3,上限为小于频数百分比累计频数累积百分比有效40.00-42.0033.033.043.00-45.0099.01212.046.00-48.002424.03636.049.00-51.001919.05555.052.00-54.002424.07979.055.00-57.001414.09393.058.00+77.0100100.0合计100100.0 直方图:43
组距4,上限为小于等于频数百分比累计频数累积百分比有效<=40.0011.011.041.00-44.0077.088.045.00-48.002828.03636.049.00-52.002828.06464.053.00-56.002222.08686.057.00-60.001313.09999.061.00+11.0100100.0合计100100.0 直方图:43
组距5,上限为小于等于频数百分比累计频数累积百分比有效<=45.001212.012.012.046.00-50.003737.049.049.051.00-55.003434.083.083.056.00-60.001616.099.099.061.00+11.0100.0100.0合计100100.0 直方图:43
分布特征:左偏钟型。3.8下面是北方某城市1——2月份各天气温的记录数据:-32-4-7-11-1789-614-18-15-9-6-105-4-96-8-12-16-19-15-22-25-24-19-8-6-15-11-12-19-25-24-18-17-14-22-13-9-60-15-4-9-32-4-4-16-175-6-5要求:(1)指出上面的数据属于什么类型。数值型数据(2)对上面的数据进行适当的分组。1、确定组数:,取k=72、确定组距:组距=(最大值-最小值)÷组数=(14-(-25))÷7=5.57,取53、分组频数表43
温度频数频率%累计频数累计频率%-25--21610.0610.0-20--16813.31423.3-15--11915.02338.3-10--61220.03558.3-5--11220.04778.30-446.75185.05-9813.35998.310+11.760100.0合计60100.0 (3)绘制直方图,说明该城市气温分布的特点。3.11对于下面的数据绘制散点图。x234187y252520301618解:43
3.12甲乙两个班各有40名学生,期末统计学考试成绩的分布如下:考试成绩人数甲班乙班优良中及格不及格361894615982要求:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。43
(2)比较两个班考试成绩分布的特点。甲班成绩中的人数较多,高分和低分人数比乙班多,乙班学习成绩较甲班好,高分较多,而低分较少。(3)画出雷达图,比较两个班考试成绩的分布是否相似。分布不相似。3.14已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):单位:亿元年份国内生产总值第一产业第二产业第三产业43
199519961997199819992000200120022003200458478.167884.674462.678345.282067.589468.197314.8105172.3117390.2136875.91199313844.214211.214552.414471.9614628.215411.816117.316928.120768.072853833613372233861940558449354875052980612747238717947204282302925174270382990533153360753918843721要求:(1)用Excel绘制国内生产总值的线图。(2)绘制第一、二、三产业国内生产总值的线图。(3)根据2004年的国内生产总值及其构成数据绘制饼图。43
43
第四章统计数据的概括性描述4.1一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:24710101012121415要求:(1)计算汽车销售量的众数、中位数和平均数。(2)根据定义公式计算四分位数。(3)计算销售量的标准差。(4)说明汽车销售量分布的特征。解:Statistics汽车销售数量NValid10Missing0Mean9.60Median10.00Mode10Std.Deviation4.169Percentiles256.255010.007512.5043
4.2随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19152925242321382218302019191623272234244120311723要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄FrequencyPercentCumulativeFrequencyCumulativePercentValid1514.014.01614.028.01714.0312.01814.0416.019312.0728.02028.0936.02114.01040.043
2228.01248.023312.01560.02428.01768.02514.01872.02714.01976.02914.02080.03014.02184.03114.02288.03414.02392.03814.02496.04114.025100.0Total25100.0 从频数看出,众数Mo有两个:19、23;从累计频数看,中位数Me=23。(2)根据定义公式计算四分位数。Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。(3)计算平均数和标准差;Mean=24.00;Std.Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。如需看清楚分布形态,需要进行分组。为分组情况下的直方图:43
为分组情况下的概率密度曲线:分组:1、确定组数:,取k=62、确定组距:组距=(最大值-最小值)÷组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄(Binned)FrequencyPercentCumulativeFrequencyCumulativePercentValid<=1514.014.016-20832.0936.021-25936.01872.026-30312.02184.031-3528.02392.036-4014.02496.041+14.025100.0Total25100.0 分组后的均值与方差:Mean23.3000Std.Deviation7.02377Variance49.333Skewness1.16343
Kurtosis1.302分组后的直方图:4.3某银行为缩短顾客到银行办理业务等待的时间。准备采用两种排队方式进行试验:一种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。为比较哪种排队方式使顾客等待的时间更短.两种排队方式各随机抽取9名顾客。得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟。第二种排队方式的等待时间(单位:分钟)如下:5.56.66.76.87.17.37.47.87.8要求:(1)画出第二种排队方式等待时间的茎叶图。第二种排队方式的等待时间(单位:分钟)Stem-and-LeafPlotFrequencyStem&Leaf1.00Extremes(=<5.5)3.006.6783.007.1342.007.88Stemwidth:1.00Eachleaf:1case(s)(2)计算第二种排队时间的平均数和标准差。Mean7Std.Deviation0.714143Variance0.5143
(3)比较两种排队方式等待时间的离散程度。第二种排队方式的离散程度小。(4)如果让你选择一种排队方式,你会选择哪—种?试说明理由。选择第二种,均值小,离散程度小。4.4某百货公司6月份各天的销售额数据如下:单位:万元257276297252238310240236265278271292261281301274267280291258272284268303273263322249269295要求:(1)计算该百货公司日销售额的平均数和中位数。(2)按定义公式计算四分位数。(3)计算日销售额的标准差。解:Statistics百货公司每天的销售额(万元)NValid30Missing0Mean274.1000Median272.5000Std.Deviation21.17472Percentiles25260.250050272.500075291.25004.5甲乙两个企业生产三种产品的单位成本和总成本资料如下:产品单位成本总成本(元)名称(元)甲企业乙企业ABC152030210030001500325515001500要求:比较两个企业的总平均成本,哪个高,并分析其原因。产品名称单位成本(元)甲企业乙企业总成本(元)产品数总成本(元)产品数A1521001403255217B203000150150075C30150050150050平均成本(元)19.4117647118.28947368调和平均数计算,得到甲的平均成本为19.41;乙的平均成本为18.29。甲的中间成本的产品多,乙的低成本的产品多。43
4.6在某地区抽取120家企业,按利润额进行分组,结果如下:按利润额分组(万元)企业数(个)200~300300~400400~500500~600600以上1930421811合计120要求:(1)计算120家企业利润额的平均数和标准差。(2)计算分布的偏态系数和峰态系数。解:Statistics企业利润组中值Mi(万元)NValid120Missing0Mean426.6667Std.Deviation116.48445Skewness0.208Std.ErrorofSkewness0.221Kurtosis-0.625Std.ErrorofKurtosis0.43843
4.7为研究少年儿童的成长发育状况,某研究所的一位调查人员在某城市抽取100名7~17岁的少年儿童作为样本,另一位调查人员则抽取了1000名7~17岁的少年儿童作为样本。请回答下面的问题,并解释其原因。(1)两位调查人员所得到的样本的平均身高是否相同?如果不同,哪组样本的平均身高较大?(2)两位调查人员所得到的样本的标准差是否相同?如果不同,哪组样本的标准差较大?(3)两位调查人员得到这l100名少年儿童身高的最高者或最低者的机会是否相同?如果不同,哪位调查研究人员的机会较大?解:(1)不一定相同,无法判断哪一个更高,但可以判断,样本量大的更接近于总体平均身高。(2)不一定相同,样本量少的标准差大的可能性大。(3)机会不相同,样本量大的得到最高者和最低者的身高的机会大。4.8一项关于大学生体重状况的研究发现.男生的平均体重为60kg,标准差为5kg;女生的平均体重为50kg,标准差为5kg。请回答下面的问题:(1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg×43
2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1===-1;Z2===1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1===-2;Z2===2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。4.9一家公司在招收职员时,首先要通过两项能力测试。在A项测试中,其平均分数是100分,标准差是15分;在B项测试中,其平均分数是400分,标准差是50分。一位应试者在A项测试中得了115分,在B项测试中得了425分。与平均分数相比,该应试者哪一项测试更为理想?解:应用标准分数来考虑问题,该应试者标准分数高的测试理想。ZA===1;ZB===0.5因此,A项测试结果理想。4.10一条产品生产线平均每天的产量为3700件,标准差为50件。如果某一天的产量低于或高于平均产量,并落人士2个标准差的范围之外,就认为该生产线“失去控制”。下面是一周各天的产量,该生产线哪几天失去了控制?时间周一周二周三周四周五周六周日产量(件)3850367036903720361035903700时间周一周二周三周四周五周六周日产量(件)3850367036903720361035903700日平均产量3700日产量标准差50标准分数Z3-0.6-0.20.4-1.8-2.20标准分数界限-2-2-2-2-2-2-22222222周六超出界限,失去控制。4.11对10名成年人和10名幼儿的身高进行抽样调查,结果如下:成年组166169l72177180170172174168173幼儿组686968707l7372737475要求:(1)如果比较成年组和幼儿组的身高差异,你会采用什么样的统计量?为什么?均值不相等,用离散系数衡量身高差异。(2)比较分析哪一组的身高差异大?43
成年组幼儿组平均172.1平均71.3标准差4.201851标准差2.496664离散系数0.024415离散系数0.035016幼儿组的身高差异大。4.12一种产品需要人工组装,现有三种可供选择的组装方法。为检验哪种方法更好,随机抽取15个工人,让他们分别用三种方法组装。下面是15个工人分别用三种方法在相同的时间内组装的产品数量:单位:个方法A方法B方法C164167168165170165164168164162163166167166165129130129130131]30129127128128127128128125132125126126127126128127126127127125126116126125要求:(1)你准备采用什么方法来评价组装方法的优劣?(2)如果让你选择一种方法,你会作出怎样的选择?试说明理由。解:对比均值和离散系数的方法,选择均值大,离散程度小的。方法A方法B方法C平均165.6平均128.7333333平均125.5333333标准差2.131397932标准差1.751190072标准差2.774029217离散系数:VA=0.01287076,VB=0.013603237,VC=0.022097949均值A方法最大,同时A的离散系数也最小,因此选择A方法。4.1343
在金融证券领域,一项投资的预期收益率的变化通常用该项投资的风险来衡量。预期收益率的变化越小,投资风险越低;预期收益率的变化越大,投资风险就越高。下面的两个直方图,分别反映了200种商业类股票和200种高科技类股票的收益率分布。在股票市场上,高收益率往往伴随着高风险。但投资于哪类股票,往往与投资者的类型有一定关系。(1)你认为该用什么样的统计量来反映投资的风险?标准差或者离散系数。(2)如果选择风险小的股票进行投资,应该选择商业类股票还是高科技类股票?选择离散系数小的股票,则选择商业股票。(3)如果进行股票投资,你会选择商业类股票还是高科技类股票?考虑高收益,则选择高科技股票;考虑风险,则选择商业股票。43
6.1调节一个装瓶机使其对每个瓶子的灌装量均值为盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差盎司的正态分布。随机抽取由这台机器灌装的9个瓶子形成一个样本,并测定每个瓶子的灌装量。试确定样本均值偏离总体均值不超过0.3盎司的概率。解:总体方差知道的情况下,均值的抽样分布服从的正态分布,由正态分布,标准化得到标准正态分布:z=~,因此,样本均值不超过总体均值的概率P为:====2-1,查标准正态分布表得=0.8159因此,=0.63186.3,,……,表示从标准正态总体中随机抽取的容量,n=6的一个样本,试确定常数b,使得解:由于卡方分布是由标准正态分布的平方和构成的:设Z1,Z2,……,Zn是来自总体N(0,1)的样本,则统计量服从自由度为n的χ2分布,记为χ2~χ2(n)因此,令,则,那么由概率,可知:b=,查概率表得:b=12.596.4在习题6.1中,假定装瓶机对瓶子的灌装量服从方差的标准正态分布。假定我们计划随机抽取10个瓶子组成样本,观测每个瓶子的灌装量,得到10个观测值,用这10个观测值我们可以求出样本方差,确定一个合适的范围使得有较大的概率保证S2落入其中是有用的,试求b1,b2,使得43
解:更加样本方差的抽样分布知识可知,样本统计量:此处,n=10,,所以统计量根据卡方分布的可知:又因为:因此:则:查概率表:=3.325,=19.919,则=0.369,=1.8843
7.2某快餐店想要估计每位顾客午餐的平均花费金额。在为期3周的时间里选取49名顾客组成了一个简单随机样本。(1)假定总体标准差为15元,求样本均值的抽样标准误差。=2.143(2)在95%的置信水平下,求边际误差。,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=因此,=1.96×2.143=4.2(3)如果样本均值为120元,求总体均值的95%的置信区间。置信区间为:==(115.8,124.2)7.4从总体中抽取一个n=100的简单随机样本,得到=81,s=12。要求:大样本,样本均值服从正态分布:或置信区间为:,==1.2(1)构建的90%的置信区间。==1.645,置信区间为:=(79.03,82.97)(2)构建的95%的置信区间。==1.96,置信区间为:=(78.65,83.35)(3)构建的99%的置信区间。==2.576,置信区间为:=(77.91,84.09)7.7某大学为了解学生每天上网的时间,在全校7500名学生中采取重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据(单位:小时):3.33.16.25.82.34.15.44.53.24.42.05.42.66.41.83.55.72.32.11.91.25.14.34.23.60.81.543
4.71.41.22.93.52.40.53.62.5求该校大学生平均上网时间的置信区间,置信水平分别为90%,95%和99%。解:(1)样本均值=3.32,样本标准差s=1.61;(2)抽样平均误差:重复抽样:==1.61/6=0.268不重复抽样:===0.268×=0.268×0.998=0.267(3)置信水平下的概率度:=0.9,t===1.645=0.95,t===1.96=0.99,t===2.576(4)边际误差(极限误差):=0.9,=重复抽样:==1.645×0.268=0.441不重复抽样:==1.645×0.267=0.439=0.95,=重复抽样:==1.96×0.268=0.525不重复抽样:==1.96×0.267=0.523=0.99,=重复抽样:==2.576×0.268=0.69不重复抽样:==2.576×0.267=0.688(5)置信区间:43
=0.9,重复抽样:==(2.88,3.76)不重复抽样:==(2.88,3.76)=0.95,重复抽样:==(2.79,3.85)不重复抽样:==(2.80,3.84)=0.99,重复抽样:==(2.63,4.01)不重复抽样:==(2.63,4.01)7.9某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是:103148691211751015916132假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。解:小样本,总体方差未知,用t统计量均值=9.375,样本标准差s=4.11置信区间:=0.95,n=16,==2.13==(7.18,11.57)7.11某企业生产的袋装食品采用自动打包机包装,每袋标准重量为l00g。现从某天生产的一批产品中按重复抽样随机抽取50包进行检查,测得每包重量(单位:g)如下:每包重量(g)包数96~9898~100100~102233443
102~104104~10674合计50已知食品包重量服从正态分布,要求:(1)确定该种食品平均重量的95%的置信区间。解:大样本,总体方差未知,用z统计量样本均值=101.4,样本标准差s=1.829置信区间:=0.95,==1.96==(100.89,101.91)(2)如果规定食品重量低于l00g属于不合格,确定该批食品合格率的95%的置信区间。解:总体比率的估计大样本,总体方差未知,用z统计量样本比率=(50-5)/50=0.9置信区间:=0.95,==1.96==(0.8168,0.9832)7.1343
一家研究机构想估计在网络公司工作的员工每周加班的平均时间,为此随机抽取了18个员工。得到他们每周加班的时间数据如下(单位:小时):63218171220117902182516152916假定员工每周加班的时间服从正态分布。估计网络公司员工平均每周加班时间的90%的置信区间。解:小样本,总体方差未知,用t统计量均值=13.56,样本标准差s=7.801置信区间:=0.90,n=18,==1.7369==(10.36,16.75)7.15在一项家电市场调查中.随机抽取了200个居民户,调查他们是否拥有某一品牌的电视机。其中拥有该品牌电视机的家庭占23%。求总体比例的置信区间,置信水平分别为90%和95%。解:总体比率的估计大样本,总体方差未知,用z统计量样本比率=0.23置信区间:=0.90,==1.64543
==(0.1811,0.2789)=0.95,==1.96==(0.1717,0.2883)7.20顾客到银行办理业务时往往需要等待一段时间,而等待时间的长短与许多因素有关,比如,银行业务员办理业务的速度,顾客等待排队的方式等。为此,某银行准备采取两种排队方式进行试验,第一种排队方式是:所有顾客都进入一个等待队列;第二种排队方式是:顾客在三个业务窗口处列队三排等待。为比较哪种排队方式使顾客等待的时间更短,银行各随机抽取10名顾客,他们在办理业务时所等待的时间(单位:分钟)如下:方式16.56.66.76.87.17.37.47.77.77.7方式24.25.45.86.26.77.77.78.59.310要求:(1)构建第一种排队方式等待时间标准差的95%的置信区间。解:估计统计量经计算得样本标准差=3.318置信区间:=0.95,n=10,==19.02,==2.7==(0.1075,0.7574)因此,标准差的置信区间为(0.3279,0.8703)(2)构建第二种排队方式等待时间标准差的95%的置信区间。解:估计统计量43
经计算得样本标准差=0.2272置信区间:=0.95,n=10,==19.02,==2.7==(1.57,11.06)因此,标准差的置信区间为(1.25,3.33)(3)根据(1)和(2)的结果,你认为哪种排队方式更好?第一种方式好,标准差小!7.23下表是由4对观察值组成的随机样本。配对号来自总体A的样本来自总体B的样本1234251080765(1)计算A与B各对观察值之差,再利用得出的差值计算和。=1.75,=2.62996(2)设分别为总体A和总体B的均值,构造的95%的置信区间。解:小样本,配对样本,总体方差未知,用t统计量均值=1.75,样本标准差s=2.62996置信区间:=0.95,n=4,==3.18243
==(-2.43,5.93)7.25从两个总体中各抽取一个=250的独立随机样本,来自总体1的样本比例为=40%,来自总体2的样本比例为=30%。要求:(1)构造的90%的置信区间。(2)构造的95%的置信区间。解:总体比率差的估计大样本,总体方差未知,用z统计量样本比率p1=0.4,p2=0.3置信区间:=0.90,==1.645==(3.02%,16.98%)=0.95,==1.96=43
=(1.68%,18.32%)7.26生产工序的方差是工序质量的一个重要度量。当方差较大时,需要对序进行改进以减小方差。下面是两部机器生产的袋茶重量(单位:g)的数据:机器1机器23.453.223.93.223.283.353.22.983.73.383.193.33.223.753.283.33.23.053.53.383.353.33.293.332.953.453.23.343.353.273.163.483.123.283.163.283.23.183.253.33.343.25要求:构造两个总体方差比/的95%的置信区间。解:统计量:置信区间:=0.058,=0.006n1=n2=21=0.95,==2.4645,====0.4058=(4.05,24.6)43
7.27根据以往的生产数据,某种产品的废品率为2%。如果要求95%的置信区间,若要求边际误差不超过4%,应抽取多大的样本?解:=0.95,==1.96==47.06,取n=48或者50。7.28某超市想要估计每个顾客平均每次购物花费的金额。根据过去的经验,标准差大约为120元,现要求以95%的置信水平估计每个顾客平均购物金额的置信区间,并要求边际误差不超过20元,应抽取多少个顾客作为样本?解:,=0.95,==1.96,=138.3,取n=139或者140,或者150。7.29假定两个总体的标准差分别为:,,若要求误差范围不超过5,相应的置信水平为95%,假定,估计两个总体均值之差时所需的样本量为多大?解:n1=n2=,=0.95,==1.96,n1=n2===56.7,取n=58,或者60。7.30假定,边际误差E=0.05,相应的置信水平为95%,估计两个总体比例之差时所需的样本量为多大?解:n1=n2=,=0.95,=43
=1.96,取p1=p2=0.5,n1=n2===768.3,取n=769,或者780或800。8.2一种元件,要求其使用寿命不得低于700小时。现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。已知该元件寿命服从正态分布,=60小时,试在显著性水平0.05下确定这批元件是否合格。解:H0:μ≥700;H1:μ<700已知:=680=60由于n=36>30,大样本,因此检验统计量:==-2当α=0.05,查表得=1.645。因为z<-,故拒绝原假设,接受备择假设,说明这批产品不合格。8.4糖厂用自动打包机打包,每包标准重量是100千克。每天开工后需要检验一次打包机工作是否正常。某日开工后测得9包重量(单位:千克)如下:99.398.7100.5101.298.399.799.5102.1100.5已知包重服从正态分布,试检验该日打包机工作是否正常(a=0.05)?解:H0:μ=100;H1:μ≠100经计算得:=99.9778S=1.21221检验统计量:==-0.055当α=0.05,自由度n-1=9时,查表得=2.262。因为<,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明打包机工作正常。8.5某种大量生产的袋装食品,按规定不得少于250克。今从一批该食品中任意抽取50袋,发现有6袋低于250克。若规定不符合标准的比例超过5%就不得出厂,问该批食品能否出厂(a=0.05)?解:解:H0:π≤0.05;H1:π>0.05已知:p=6/50=0.12检验统计量:43
==2.271当α=0.05,查表得=1.645。因为>,样本统计量落在拒绝区域,故拒绝原假设,接受备择假设,说明该批食品不能出厂。8.7某种电子元件的寿命x(单位:小时)服从正态分布。现测得16只元件的寿命如下:159280101212224379179264222362168250149260485170问是否有理由认为元件的平均寿命显著地大于225小时(a=0.05)?解:H0:μ≤225;H1:μ>225经计算知:=241.5s=98.726检验统计量:==0.669当α=0.05,自由度n-1=15时,查表得=1.753。因为t<,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明元件寿命没有显著大于225小时。8.10装配一个部件时可以采用不同的方法,所关心的问题是哪一个方法的效率更高。劳动效率可以用平均装配时间反映。现从不同的装配方法中各抽取12件产品,记录各自的装配时间(单位:分钟)如下:甲方法:313429323538343029323126乙方法:262428293029322631293228两总体为正态总体,且方差相同。问两种方法的装配时间有无显著不同(a=0.05)?解:建立假设H0:μ1-μ2=0H1:μ1-μ2≠0总体正态,小样本抽样,方差未知,方差相等,检验统计量根据样本数据计算,得=12,=12,=31.75,=3.19446,=28.6667,=2.46183。==8.132643
=2.648α=0.05时,临界点为==2.074,此题中>,故拒绝原假设,认为两种方法的装配时间有显著差异。8.11调查了339名50岁以上的人,其中205名吸烟者中有43个患慢性气管炎,在134名不吸烟者中有13人患慢性气管炎。调查数据能否支持“吸烟者容易患慢性气管炎”这种观点(a=0.05)?解:建立假设H0:π1≤π2;H1:π1>π2p1=43/205=0.2097n1=205p2=13/134=0.097n2=134检验统计量==3当α=0.05,查表得=1.645。因为>,拒绝原假设,说明吸烟者容易患慢性气管炎。8.12为了控制贷款规模,某商业银行有个内部要求,平均每项贷款数额不能超过60万元。随着经济的发展,贷款规模有增大的趋势。银行经理想了解在同样项目条件下,贷款的平均规模是否明显地超过60万元,故一个n=144的随机样本被抽出,测得=68.1万元,s=45。用a=0.01的显著性水平,采用p值进行检验。解:H0:μ≤60;H1:μ>60已知:=68.1s=45由于n=144>30,大样本,因此检验统计量:==2.16由于>μ,因此P值=P(z≥2.16)=1-,查表的=0.9846,P值=0.0154由于P>α=0.01,故不能拒绝原假设,说明贷款的平均规模没有明显地超过60万元。8.13有一种理论认为服用阿司匹林有助于减少心脏病的发生,为了进行验证,研究人员把自愿参与实验的2243
000人随机平均分成两组,一组人员每星期服用三次阿司匹林(样本1),另一组人员在相同的时间服用安慰剂(样本2)持续3年之后进行检测,样本1中有104人患心脏病,样本2中有189人患心脏病。以a=0.05的显著性水平检验服用阿司匹林是否可以降低心脏病发生率。解:建立假设H0:π1≥π2;H1:π1<π2p1=104/11000=0.00945n1=11000p2=189/11000=0.01718n2=11000检验统计量==-5当α=0.05,查表得=1.645。因为<-,拒绝原假设,说明用阿司匹林可以降低心脏病发生率。8.15有人说在大学中男生的学习成绩比女生的学习成绩好。现从一个学校中随机抽取了25名男生和16名女生,对他们进行了同样题目的测试。测试结果表明,男生的平均成绩为82分,方差为56分,女生的平均成绩为78分,方差为49分。假设显著性水平α=0.02,从上述数据中能得到什么结论?解:首先进行方差是否相等的检验:建立假设H0:=;H1:≠n1=25,=56,n2=16,=49==1.143当α=0.02时,=3.294,=0.346。由于<F<,检验统计量的值落在接受域中,所以接受原假设,说明总体方差无显著差异。检验均值差:建立假设H0:μ1-μ2≤0H1:μ1-μ2>0总体正态,小样本抽样,方差未知,方差相等,检验统计量43
根据样本数据计算,得=25,=16,=82,=56,=78,=49=53.308=1.711α=0.02时,临界点为==2.125,t<,故不能拒绝原假设,不能认为大学中男生的学习成绩比女生的学习成绩好。43
43'
您可能关注的文档
- 统计学导论-曾五一课后习题答案打印版.doc
- 统计学徐国祥第二版课后题答案.docx
- 统计学袁卫期末复习及课后练习参考答案.doc
- 统计学课后习题答案(统计学 第三版.doc
- 统计学课后习题答案.doc
- 统计学课后习题答案.pdf
- 统计学课后习题答案_(第四版)4.5.7.8章.doc
- 统计学课后答案.doc
- 统计学课后练习答案.pdf
- 统计学课后题2到10单元答案(袁卫).doc
- 统计学部分习题参考答案.doc
- 统计建模与R软件课后答案.docx
- 继电保护模拟试题及答案.doc
- 继续教育《心理健康与心理调适》题库和答案大全.doc
- 继续教育考试阳光心态试题及答案(完整版).doc
- 绪论习题及参考答案.doc
- 综合教程3册语块练习答案1-8单元.doc
- 综合素质部分思考题(含答案).pdf
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明