
- 5.65 MB
- 2022-04-22 11:26:53 发布


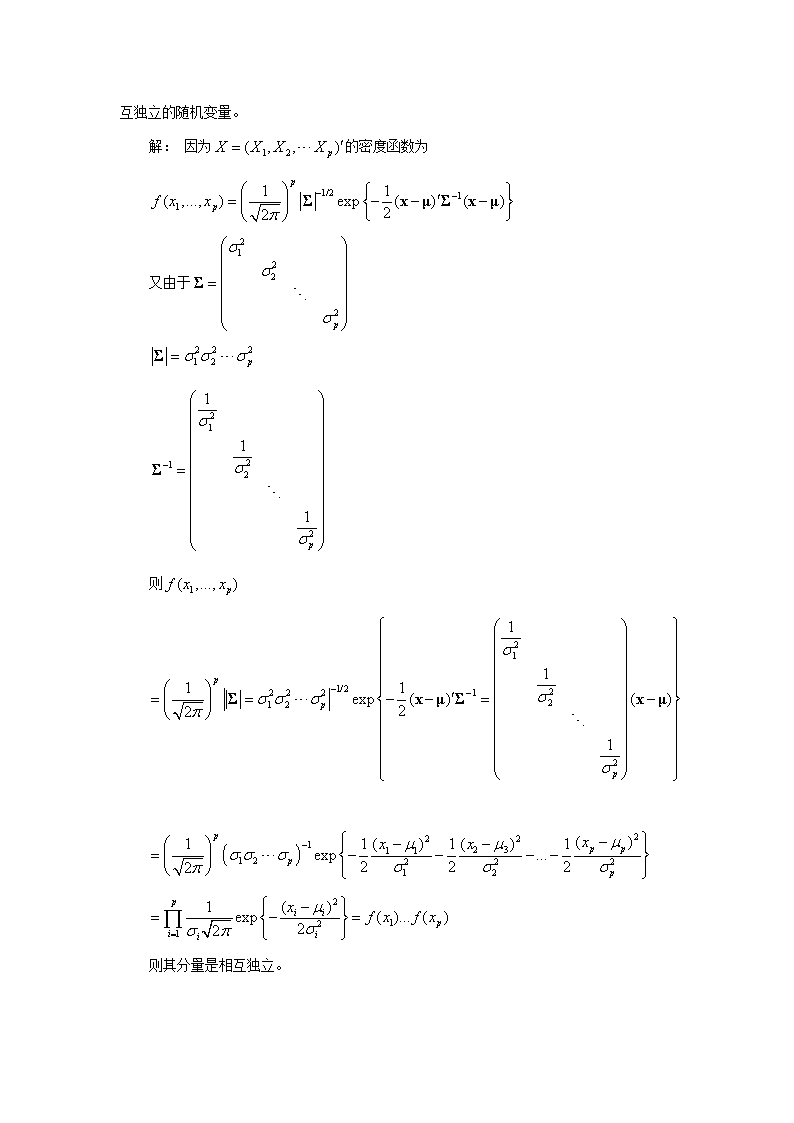
- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'第二章2.1.试叙述多元联合分布和边际分布之间的关系。解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,的联合分布密度函数是一个p维的函数,而边际分布讨论是的子向量的概率分布,其概率密度函数的维数小于p。2.2设二维随机向量服从二元正态分布,写出其联合分布。解:设的均值向量为,协方差矩阵为,则其联合分布密度函数为。2.3已知随机向量的联合密度函数为其中,。求(1)随机变量和的边缘密度函数、均值和方差;(2)随机变量和的协方差和相关系数;(3)判断和是否相互独立。(1)解:随机变量和的边缘密度函数、均值和方差;
所以由于服从均匀分布,则均值为,方差为。同理,由于服从均匀分布,则均值为,方差为。(2)解:随机变量和的协方差和相关系数;(3)解:判断和是否相互独立。和由于,所以不独立。2.4设服从正态分布,已知其协方差矩阵S
为对角阵,证明其分量是相互独立的随机变量。解:因为的密度函数为又由于则则其分量是相互独立。
2.5由于多元正态分布的数学期望向量和均方差矩阵的极大似然分别为注:利用,S其中在SPSS中求样本均值向量的操作步骤如下:1.选择菜单项Analyze→DescriptiveStatistics→Descriptives,打开Descriptives对话框。将待估计的四个变量移入右边的Variables列表框中,如图2.1。图2.1Descriptives对话框2.单击Options按钮,打开Options子对话框。在对话框中选择Mean复选框,即计算样本均值向量,如图2.2所示。单击Continue按钮返回主对话框。
图2.2Options子对话框1.单击OK按钮,执行操作。则在结果输出窗口中给出样本均值向量,如表2.1,即样本均值向量为(35.3333,12.3333,17.1667,1.5250E2)。表2.1样本均值向量在SPSS中计算样本协差阵的步骤如下:1.选择菜单项Analyze→Correlate→Bivariate,打开BivariateCorrelations对话框。将三个变量移入右边的Variables列表框中,如图2.3。图2.3BivariateCorrelations对话框2.单击Options按钮,打开Options子对话框。选择Cross-productdeviationsandcovariances复选框,即计算样本离差阵和样本协差阵,如图2.4。单击Continue按钮,返回主对话框。
图2.4Options子对话框1.单击OK按钮,执行操作。则在结果输出窗口中给出相关分析表,见表2.2。表中Covariance给出样本协差阵。(另外,PearsonCorrelation为皮尔逊相关系数矩阵,SumofSquaresandCross-products为样本离差阵。)2.6渐近无偏性、有效性和一致性;2.7设总体服从正态分布,,有样本。由于是相互独立的正态分布随机向量之和,所以也服从正态分布。又所以。
2.8方法1:。方法2:。故为的无偏估计。2.9.设是从多元正态分布抽出的一个简单随机样本,试求的分布。证明:设
为一正交矩阵,即。令,所以。且有,,。所以独立同分布。又因为因为
又因为所以原式故,由于独立同正态分布,所以2.10.设是来自的简单随机样本,,(1)已知且,求和的估计。(2)已知求和的估计。解:(1),(2)
解之,得,第三章3.1试述多元统计分析中的各种均值向量和协差阵检验的基本思想和步骤。其基本思想和步骤均可归纳为:答:第一,提出待检验的假设和H1;第二,给出检验的统计量及其服从的分布;第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域;第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。均值向量的检验:统计量拒绝域均值向量的检验:在单一变量中当已知当未知(作为的估计量)一个正态总体协差阵已知协差阵未知
()两个正态总体有共同已知协差阵有共同未知协差阵(其中)协差阵不等协差阵不等多个正态总体单因素方差多因素方差协差阵的检验检验检验统计量3.2试述多元统计中霍特林分布和威尔克斯分布分别与一元统计中t分布和F分布的关系。答:(!)霍特林分布是t分布对于多元变量的推广。而若设,且与
相互独立,,则称统计量的分布为非中心霍特林T2分布。若,且与相互独立,令,则。(2)威尔克斯分布在实际应用中经常把统计量化为统计量进而化为统计量,利用统计量来解决多元统计分析中有关检验问题。与统计量的关系统计量及分别任意任意1任意任意21任意任意2任意任意3.3试述威尔克斯统计量在多元方差分析中的重要意义。答:威尔克斯统计量在多元方差分析中是用于检验均值的统计量。用似然比原则构成的检验统计量为给定检验水平,查Wilks分布表,确定临界值,然后作出统计判断。
第四章4.1简述欧几里得距离与马氏距离的区别和联系。答:设p维欧几里得空间中的两点X=和Y=。则欧几里得距离为。欧几里得距离的局限有①在多元数据分析中,其度量不合理。②会受到实际问题中量纲的影响。设X,Y是来自均值向量为,协方差为的总体G中的p维样本。则马氏距离为D(X,Y)=。当即单位阵时,D(X,Y)==即欧几里得距离。因此,在一定程度上,欧几里得距离是马氏距离的特殊情况,马氏距离是欧几里得距离的推广。4.2试述判别分析的实质。答:判别分析就是希望利用已经测得的变量数据,找出一种判别函数,使得这一函数具有某种最优性质,能把属于不同类别的样本点尽可能地区别开来。设R1,R2,…,Rk是p维空间Rp的k个子集,如果它们互不相交,且它们的和集为,则称为的一个划分。判别分析问题实质上就是在某种意义上,以最优的性质对p维空间构造一个“划分”,这个“划分”就构成了一个判别规则。4.3简述距离判别法的基本思想和方法。答:距离判别问题分为①两个总体的距离判别问题和②多个总体的判别问题。其基本思想都是分别计算样本与各个总体的距离(马氏距离),将距离近的判别为一类。①两个总体的距离判别问题设有协方差矩阵∑相等的两个总体G1和G2,其均值分别是m1和m2,对于一个新的样品X,要判断它来自哪个总体。计算新样品X到两个总体的马氏距离D2(X,G1)和D2(X,G2),则X,D2(X,G1)D2(X,G2)X,D2(X,G1)>D2(X,G2,具体分析,
记则判别规则为X,W(X)X,W(X)<0②多个总体的判别问题。设有个总体,其均值和协方差矩阵分别是和,且。计算样本到每个总体的马氏距离,到哪个总体的距离最小就属于哪个总体。具体分析,取,,。可以取线性判别函数为,相应的判别规则为若4.4简述贝叶斯判别法的基本思想和方法。基本思想:设k个总体,其各自的分布密度函数,假设k个总体各自出现的概率分别为,,。设将本来属于总体的样品错判到总体时造成的损失为,。设个总体相应的维样本空间为。在规则下,将属于的样品错判为的概率为则这种判别规则下样品错判后所造成的平均损失为
则用规则来进行判别所造成的总平均损失为贝叶斯判别法则,就是要选择一种划分,使总平均损失达到极小。基本方法:令,则若有另一划分,则在两种划分下的总平均损失之差为因为在上对一切成立,故上式小于或等于零,是贝叶斯判别的解。从而得到的划分为4.5简述费希尔判别法的基本思想和方法。答:基本思想:从个总体中抽取具有个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数系数可使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的个指标值代入线性判别函数式中求出值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。4.6试析距离判别法、贝叶斯判别法和费希尔判别法的异同。答:①费希尔判别与距离判别对判别变量的分布类型无要求。二者只是要求有各类母体的两阶矩存在。而贝叶斯判别必须知道判别变量的分布类型。因此前两者相对来说较为简单。②当k=2时,若则费希尔判别与距离判别等价。当判别变量服从正态分布时,二者与贝叶斯判别也等价。③当时,费希尔判别用作为共同协差阵,实际看成等协差阵,此与距离判别、贝叶斯判别不同。
④距离判别可以看为贝叶斯判别的特殊情形。贝叶斯判别的判别规则是X,W(X)X,W(X)
您可能关注的文档
- 一元函数微积分 (魏贵民 胡灿 著) 高等教育出版社 课后答案《一元函数微积分》习题解答第一章
- 医学统计学 第二版 颜虹主编 课后答案 人民卫生出版社-
- 医用物理学 (李旭光 著) 北京出版社邮电大学 课后答案
- 医用物理学 第七版 (胡新珉 著) 人民卫生出版社 课后答案
- 医用有机化学 (唐玉海 著) 高等教育出版社 课后答案
- 医用有机化学 第二版 (唐玉海 著) 高等教育出版社 课后答案
- 仪器分析 (董慧茹 著) 化学工业出版社 课后答案
- 仪器分析 第二版 (石杰 著) 郑州大学出版社 课后答案
- 英语国家社会与文化入门 第二版 (朱永涛 王立礼 著) 高等教育出版社 课后答案
- 应用数理统计_施雨_课后习题答案_
- 应用数学基础习题答案+熊洪允+天津大学出版社
- 应用随机过程 (林元烈 著) 清华大学出版社 课后答案
- 应用随机过程 (张波 著) 清华大学出版社 课后答案
- 应用随机过程 概率模型导论 英文版 第九版 (SheldonM.Ross 著) 人民邮电出版社 课后答案
- 优化学习 暑假40天 七年级 语文 第六版 (江足宁 著) 天津科学技术出版社 课后答案
- 油藏工程_李传亮_第二版课后习题答案
- 有机化学 (付建龙 李红 著) 化学工业出版社 课后答案
- 有机化学 第二版 (陆国元 著) 南京大学出版社 课后答案
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明
-
 关注微信公众号售出明细实时看
关注微信公众号售出明细实时看