
- 522.50 KB
- 2022-04-22 11:44:09 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'广西工学院《计算机系统结构》习题及答案1.系统结构基础知识1.1有一个经解释实现的计算机,可以按功能划分4级。每一级为了执行一条指令需要下一级的N条指令解释。若执行第1级的一条指令需Kns时间,则执行第2、3、4级的一条指令各需要多少时间?【分析】注意“上一级”与“下一级”的关系,上一级程序在下一级上的实现不是经翻译完成,只能是解释。解:执行第1级的一条指令需Kns时间执行第2级的一条指令需KNns时间执行第3级的一条指令需KN2ns时间执行第4级的一条指令需KN3ns时间执行第n级的一条指令需KNn-1ns时间1.2有一计算机系统,可以按功能划分4级。每一级的指令互不相同。每一级的指令都比下一级的指令在效能上强M倍,即第i级的一条指令能完成第i-1级的M条指令的计算量。现若需第i级的N条指令解释第i+1级的一条指令,而有一段程序在第1级上运行需要Ks,问在第2、3、4级上一段等效的程序各需要运行多长时间?【分析】从指令功能意义上讲,每级的单条指令需下级N条指令来完成,从效能意义上讲,每级的指令都比下一级的指令强M倍,若某级上运行需Ks,则下一级上运行需KN/Ms。解:在第2级上一段等效的程序需要运行时间为:(N/M)Ks在第3级上一段等效的程序需要运行时间为:(N/M)2Ks在第4级上一段等效的程序需要运行时间为:(N/M)3Ks1.3什么是透明性概念?对于计算机系统结构,下列哪些是透明的?哪些是不透明的?存储器的模m交叉存取、浮点数据表示、I/O系统是采用通道方式还是外围处理机方式、数据总线宽度、字符行运算指令、阵列运算部件、通道是采用结合型还是独立型、PDP-11系列的单总线结构、访问方式保护、程序性中断、串行、重叠还是流水控制方式、堆栈指令、存储器最小编址单位、Cache存储器。【分析】凡是属于编写机器语言和汇编语言程序所必须面对的内容,都是不透明的。或者说有关系统结构属性所包括的内容,对系统结构都不透明。解:客观存在的事物或属性,从某个角度看,它好像不存在,称之为透明性。对于计算机系统结构,透明的是:存储器的模m交叉存取、数据总线宽度、阵列运算部件、通道是采用结合型还是独立型、PDP-11系列的单总线结构、串行、重叠还是流水控制方式、Cache存储器。对于计算机系统结构,不透明的是:浮点数据表示、I/O系统是采用通道方式还是外围处理机方式、字符行运算指令、访问方式保护、程序性中断、堆栈指令、存储器最小编址单位。1.4从机器(汇编)语言程序员的角度来看,以下哪些是透明的?指令地址寄存器、指令缓冲器、时标发生器、条件码寄存器、乘法器、主存地址寄存器、磁盘外设、先行进位链、移位器、通用寄存器、中断字寄存器。【分析】从机器(汇编)语言程序员的角度来看,实际上就是从计算机系统结构看的内容。在汇编语言程序中直接用到的,肯定是不透明的。解:对机器(汇编)语言程序员透明的:指令缓冲器、时标发生器、乘法器、主存地址寄存器、先行进位链、移位器。对机器(汇编)语言程序员不透明的:指令地址寄存器、条件码寄存器、磁盘外设、通用寄存器、中断字寄存器。1.5下列哪些对系统程序员是透明的?哪些对应用程序员是透明的?系列机各档不同的数据宽度、虚拟存储器、Cache存储器、程序状态字、“启动I/O”指令、“执行”指令、指令缓冲存储器【分析】系统程序员和应用程序员都有可能应用汇编语言或机器语言编程,当然也可能使用高级语言编程。所以,属全硬件实现的计算机组成所包含的方面,对他们都是透明的。解:对系统程序员(编写系统软件的人)和应用程序员透明的:系列机各档不同的数据宽度、Cache存储器、指令缓冲存储器。虚拟存储器、程序状态字、“启动I/O”指令对系统程序员不透明,对应用程序员透明。“执行”指令对系统程序员、应用程序员不透明。1.8用一台40MHz处理机执行标准测试程序,它含的混合指令数和相应所需的时钟周期数如下:求有效CPI、MIPS速率和程序的执行时间.指令类型指令数时钟周期数整数运算450001数据传送320002浮点150002控制传送80002解:时钟周期T=1/(40×106)=0.25×10-7s程序执行时钟周期数Tn=45000+2×32000+2×15000+2×8000=155000程序执行时间Ts=(45000+2×32000+2×15000+2×8000)×0.25×10-7=3.875msIC=45000+32000+15000+8000=1×105MIPS=IC/Ts×10-6=26CPI=Tn/IC=1.55
1.6想在系列机中发展一种新型号机器,你认为下列哪些设想可以考虑,哪些则不行,为什么?(1)新增加字符数据类型和若干条字符处理指令,以支持事务数据处理程序的编译。(2)为增强中断处理功能,将中断分级由原来的4级增加到5级,并重新调整中断响应的优先次序。(3)在CPU与主存之间增设Cache存储器,以克服访存速度过低的系统性能瓶颈。(4)为解决计算误差较大问题,将机器中浮点数的下溢处理方法由原来的“恒置1”法,改为增设用只读存储器存放下溢处理结果的查表舍入法。(5)为增加寻址灵活性和减少平均指令字长,将原来全部采用等长操作码的指令,改为具有3类不同码长的扩展操作码。(6)将CPU与主存之间的数据通路宽度由16位扩展成32位,以加快主机内部的数据传送。(7)为减少使用公用总线的冲突,将单总线改为双总线。(8)把原来的0号通用寄存器改作专用的堆栈指示器。【分析】系列机发展新型号机器最主要的是必须保证应用软件的向后兼容。一般属于计算机组成和实现的东西的改进不会影响系统结构。解:(1)可以。新增加数据类型和指令,不影响已有指令编写的程序的执行。(2)不可以。重新调整中断响应的优先次序,会影响原有程序工作的正确性。(3)可以。Cache存储器属于计算机组成。(4)可以。浮点数尾数的下溢处理属于计算机组成。(5)不可以。指令系统的改变,会直接导致原有程序不能正确运行。(6)可以。数据通路宽度属于计算机组成。(7)可以。单总线改为双总线属于计算机组成。(8)不可以。通用寄存器的改变无疑会影响原有相关指令的运行,以致程序不能正常工作。1.7假设Cache工作速度为主存的5倍,且Cache被访问命中的概率为90%,则采用Cache后,能使整个存储系统获得多高的加速比?解:∵Se=5Fe=0.9∴Sn=1/(1-Fe+Fe/Se)=3.571.8用一台40MHz处理机执行标准测试程序,它含的混合指令数和相应所需的时钟周期数如下:指令类型指令数时钟周期数整数运算450001数据传送320002浮点150002控制传送80002求有效CPI、MIPS速率和程序的执行时间解:时钟周期T=1/(40×106)=0.25×10-7s程序执行时钟周期数Tn=45000+2×32000+2×15000+2×8000=155000程序执行时间Ts=(45000+2×32000+2×15000+2×8000)×0.25×10-7=3.875msIC=45000+32000+15000+8000=1×105MIPS=IC/Ts×10-6=26CPI=Tn/IC=1.551.9已知四个程序在三台计算机上的执行时间如下:程序执行时间(s)计算机A计算机B计算机C程序111020程序2100010020程序3500100050程序4100800100假设三个程序中每一个都有1亿条指令要执行,计算这三台计算机中每台机器上每个程序的MIPS速率。根据这些速率值,你能否得出有关三台计算机相对性能的明确结论?你能否找到一种将它们统计排序的方法,试说明理由。解:这三台计算机分别执行相关三个程序的MIPS和总执行时间如下表:程序MIPS计算机A计算机B计算机C程序1100105程序20.115程序30.20.12程序410.1251总执行时间16011910190MIPS0.250.212.1平均性能:因为CAB,对不同程序速度不一样总的执行时间:一致的衡量标准
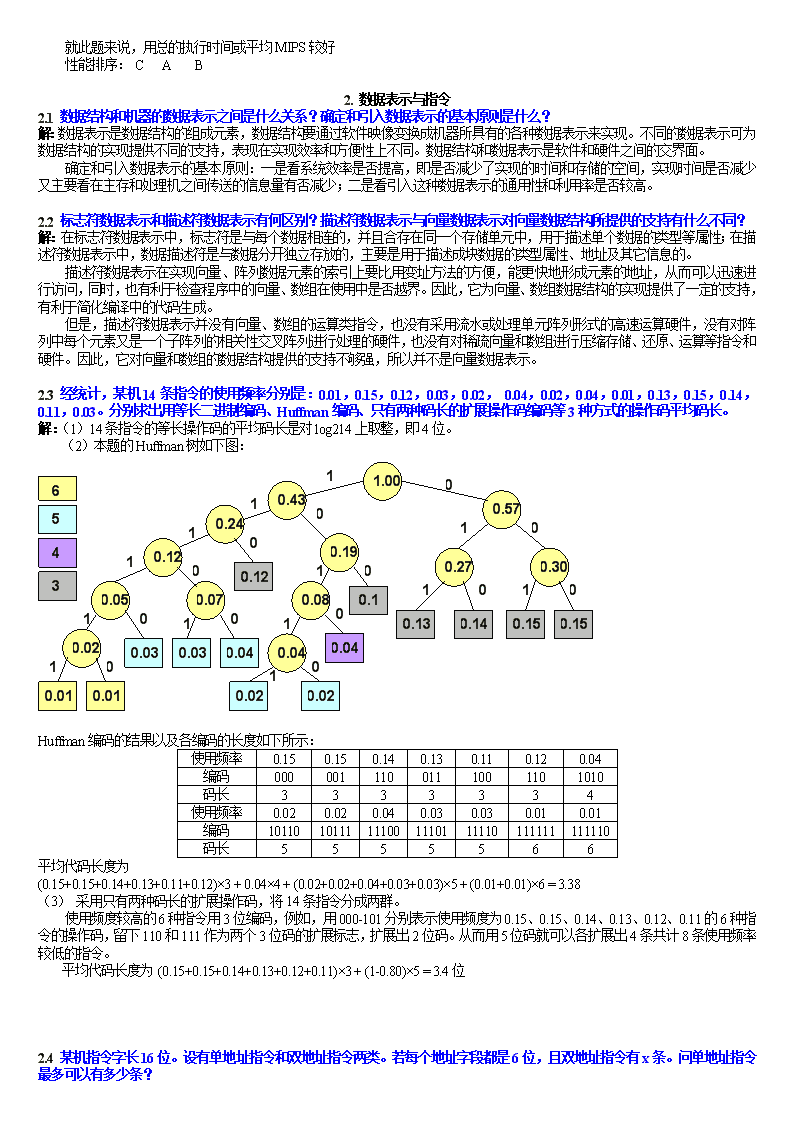
就此题来说,用总的执行时间或平均MIPS较好性能排序:CAB2.数据表示与指令2.1数据结构和机器的数据表示之间是什么关系?确定和引入数据表示的基本原则是什么?解:数据表示是数据结构的组成元素,数据结构要通过软件映像变换成机器所具有的各种数据表示来实现。不同的数据表示可为数据结构的实现提供不同的支持,表现在实现效率和方便性上不同。数据结构和数据表示是软件和硬件之间的交界面。确定和引入数据表示的基本原则:一是看系统效率是否提高,即是否减少了实现的时间和存储的空间,实现时间是否减少又主要看在主存和处理机之间传送的信息量有否减少;二是看引入这种数据表示的通用性和利用率是否较高。2.2标志符数据表示和描述符数据表示有何区别?描述符数据表示与向量数据表示对向量数据结构所提供的支持有什么不同?解:在标志符数据表示中,标志符是与每个数据相连的,并且合存在同一个存储单元中,用于描述单个数据的类型等属性;在描述符数据表示中,数据描述符是与数据分开独立存放的,主要是用于描述成块数据的类型属性、地址及其它信息的。描述符数据表示在实现向量、阵列数据元素的索引上要比用变址方法的方便,能更快地形成元素的地址,从而可以迅速进行访问,同时,也有利于检查程序中的向量、数组在使用中是否越界。因此,它为向量、数组数据结构的实现提供了一定的支持,有利于简化编译中的代码生成。但是,描述符数据表示并没有向量、数组的运算类指令,也没有采用流水或处理单元阵列形式的高速运算硬件,没有对阵列中每个元素又是一个子阵列的相关性交叉阵列进行处理的硬件,也没有对稀疏向量和数组进行压缩存储、还原、运算等指令和硬件。因此,它对向量和数组的数据结构提供的支持不够强,所以并不是向量数据表示。2.3经统计,某机14条指令的使用频率分别是:0.01,0.15,0.12,0.03,0.02,0.04,0.02,0.04,0.01,0.13,0.15,0.14,0.11,0.03。分别求出用等长二进制编码、Huffman编码、只有两种码长的扩展操作码编码等3种方式的操作码平均码长。解:(1)14条指令的等长操作码的平均码长是对log214上取整,即4位。(2)本题的Huffman树如下图:0.010.010.030.030.040.020.020.040.110.130.150.140.150.120.020.050.120.070.240.430.190.080.041.000.570.270.306位5位4位3位11001111111111100000000000Huffman编码的结果以及各编码的长度如下所示:使用频率0.150.150.140.130.110.120.04编码0000011100111001101010码长3333334使用频率0.020.020.040.030.030.010.01编码1011010111111001110111110111111111110码长5555566平均代码长度为(0.15+0.15+0.14+0.13+0.11+0.12)×3+0.04×4+(0.02+0.02+0.04+0.03+0.03)×5+(0.01+0.01)×6=3.38(3)采用只有两种码长的扩展操作码,将14条指令分成两群。使用频度较高的6种指令用3位编码,例如,用000-101分别表示使用频度为0.15、0.15、0.14、0.13、0.12、0.11的6种指令的操作码,留下110和111作为两个3位码的扩展标志,扩展出2位码。从而用5位码就可以各扩展出4条共计8条使用频率较低的指令。平均代码长度为(0.15+0.15+0.14+0.13+0.12+0.11)×3+(1-0.80)×5=3.4位2.4某机指令字长16位。设有单地址指令和双地址指令两类。若每个地址字段都是6位,且双地址指令有x条。问单地址指令最多可以有多少条?
解:根据题意,双地址指令格式为:4位操作码6位地址码16位地址码2其操作码占了4位,这样,共有24=16种短操作码。现双地址指令有X条,已占用了4位操作码中16种组合中的X个码点,所以剩下(16-X)个码点均可用作扩展标志。单地址指令的格式为10位扩展操作码6位地址码因此,(16-X)个扩展标志中的每一个码均可扩展出6位操作码来,所以单地址指令最多可以有(16-X)*26条。2.5某模型机有9条指令,其使用概率为:ADD(加):30%;CLA(清加):20%;JOM(按负转移):6%;SHR(右移):2%;STO(存):7%;SUB(减):24%;JMP(转移):7%;CIL(循环左移):3%;STP(停机):1%。要求有两种指令字长,都按双操作数指令编排。采用扩展操作码,并限制只能有两种操作码码长。设该机有若干个通用寄存器。主存为16位宽,按字节编址,采用按整数边界存储,任何指令都在一个主存周期中取得。短指令为寄存器—寄存器型,长指令为寄存器—主存型,主存地址应能变址寻址。(1)仅根据使用频度,不考虑其它要求,设计出全Huffman操作码,并计算其平均码长;(2)考虑题目全部要求,设计优化实用的操作码形式,并计算其操作码的平均码长;(3)该机允许使用多少个可编址的通用寄存器?(4)画出该机两种指令字格式,标出各字段之位数;(5)指出访存操作数地址寻址的最大相对位移量为多少个字节。解:(1)本题的Huffman树如下图:0.010.020.030.060.070.070.300.240.200.030.060.120.260.560.141.000.446位4位2位00111000001111105位由图可得Huffman编码为:ADD30%01SUB24%11CLA20%10JOM6%0001STO7%0011JMP7%0010CIL3%00001SHR2%000001STP1%000000操作码的平均码长为:2×(0.3+0.24+0.2)+4×(0.06+0.07+0.07)+5×0.03+6×(0.02+0.01)=2.61位(2)采用2-5扩展的操作码编码为:ADD30%00SUB24%01CLA20%10JOM6%11000STO7%11001JMP7%11010SHR2%11011CIL3%11100STP1%11101操作码的平均码长为:
2×(0.3+0.24+0.2)+5×(0.06+0.07+0.07+0.02+0.03+0.01)=2.78位(3)该机允许使用的可编址的通用寄存器个数为23=8个(4)短指令(1字节)格式为2位操作码3位寄存器码13位寄存器码2长指令(2字节)格式为5位操作码3位寄存器码13位变址寄存器码5位相对位移主存逻辑地址(5)访主存操作数地址寻址的最大相对位移量为32个字节(-16~+15个字节)2.6下面一段程序的功能是在主存A、B、C三个单元中找出最大的一个数送入主存MAX单元中,在某RISC处理机中,每条指令的执行过程分为“取指令”和“执行指令”两个阶段,并采用两级流水线。START:LOADR1,A;(A)->R1LOADR2,B;(B)->R2LOADR3,C;(C)->R3CMPR1,R2BGENEXT1;若R1>R2转NEXT1MOVER2,R1;R2->R1NEXT1:CMPR1,R3BGENEXT2;若R1>R3转NEXT2MOVER3,R1;R3->R1NEXT2:STORER1,MAX;存结果(1)如果在处理机中采用指令取消技术,问上述程序的执行结果是否正确?从中得到什么启示?(2)如果在处理机中采用延时转移技术,对上述指令序列进行适当的调整,在确保程序语义正确的前提下,尽可能缩短程序的执行时间。解:采用指令取消技术,程序执行结果正确,但在转移成功时,要取消下一条指令,相当于多执行了2条指令,假如两次都转移成功的话。START:LOADR1,ALOADR2,BLOADR3,CCMPR1,R2BGENEXT1;转移成功时,要取消下一条指令MOVER2,R1NEXT1:CMPR1,R3BGENEXT2;转移成功时,要取消下一条指令MOVER3,R1NEXT2:STORER1,MAX(2)程序适当调整如下:START:LOADR1,ALOADR2,BCMPR1,R2BGENEXT1LOADR3,CMOVER2,R1NEXT1:CMPR1,R3BGENEXT2NOPMOVER3,R1NEXT2:STORER1,MAX2.7下面是一个数据块搬家程序。在RISC处理机中,为了提高指令流水线的执行效率,通常要采用指令取消技术。START:MOVEAS,R1;源数组首地址送变址寄存器R1
MOVENUM,R2;数据个数送R2LOOP:MOVE(R1),AD-AS(R1);AD-AS为地址偏移量INCR1;R1增1DECR2;R2计数减1BGTLOOP;数据未送完,继续HALT;停机NUM:N;需要传送的数据总数(1)如果一条指令的执行过程分解为“取指令”和“分析指令”两个阶段,并采用两级流水线。为了采用指令取消技术,编译程序如何修改上面的程序。(2)如果N=100,采用指令取消技术后,在程序执行过程中,能节省多少个指令周期?(3)如果一条指令的执行过程分解为“取指令”、“分析指令”和“执行指令”三个阶段,并采用三级流水线。为了采用指令取消技术,编译程序如何修改上面的程序。解:(1)修改程序为START:MOVEAS,R1MOVENUM,R2MOVE(R1),AD-AS(R1)LOOP:INCR1DECR2BGTLOOPMOVE(R1),AD-AS(R1)HALTNUM:N(2)能节省99个指令周期。(3)修改程序为START:MOVEAS,R1MOVENUM,R2MOVE(R1),AD-AS(R1)INCR1LOOP:DECR2BGTLOOPMOVE(R1),AD-AS(R1)INCR1HALTNUM:N注:转移不成功,取消后两条指令2.8简要比较CISC机器和RISC机器各自的结构特点,它们分别存在哪些不足和问题?为什么说今后的发展应是CISC和RISC的结合?解:1.CISC的特点:(1)指令格式不固定,指令可长可短,操作数可多可少;(2)寻址方式复杂多样,操作数可来自寄存器,也可来自存储器;(3)采用微程序控制,执行每条指令均需完成一个微指令序列;(4)CPI>5,指令越复杂,CPI越大2.RISC的特点(1)大多数指令在单周期内完成(2)采用LOAD/STORE结构(3)硬布线控制逻辑(4)减少指令和寻址方式的种类(5)固定的指令格式(6)注重译码的优化3.CISC存在的问题:(1)未考虑20%与80%规律(2)CISC控制十分复杂,不规整,不符合VLSI发展的方向(3) 在CISC中,虽然增加了硬件指令,但并不能保证整个程序执行时间的缩短。因为这些复杂指令要消耗较多的CPU周期数,但又不常用。4.RISC的不足(1)加重汇编语言程序设计的负担(2)目标程序所占的存储空间可能加大(3)对浮点运算和虚拟存储器的支持还不够强(4)对编译程序的质量要求较高,难度较大5.今后计算机发展改进的总趋势是让RISC和CISC互相结合,取长补短。3.并行主存与存储3.1什么是存储系统?对于一个由两个存储器M1和M2构成的存储系统,设M1的命中率为h,两个存储器的容量分别为S1
和S2,访问速度分别为T1和T2,每千字节的价格分别为C1和C2。(1)在什么情况下,整个存储系统的每千字节的平均价格接近于C2?(2)写出这个存储系统的等效访问时间Ta的表达式。(3)假设存储系统的访问效率e=T1/Ta,两个存储器的速度比r=T2/T1。试以速度比r和命中率h来表示访问效率e。(4)写出r=5,20,100时,访问效率e和命中率h的关系式。(5)如果r=100,为了使访问效率e>0.95,要求命中率h是多少?(6)对于(4)所要求的命中率实际上很难达到。假设实际的命中率只能达到0.96。现采用一种缓冲技术来解决这个问题。当访问M1不命中时,把包括被访问数据在内的一个数据块都从M2取到M1中,并假设被取到M1中的每个数据平均可以被重复访问5次。请设计缓冲深度(即每次从M2取到M1中的数据块的大小)。解:存储系统是指多个性能各不相同的存储器用硬件或软件方法连接成一个系统。这个系统对应用程序员透明。在应用程序员看来,它是一个存储器,其速度接近速度最快的那个存储器,存储容量与容量最大的那个存储器相等或接近,单位容量的价格接近最便宜的那个存储器。(1)当S2>>S1时,(2)Ta=h·T1+(1-h)·T2(3)e=T1/Ta=T1/(h·T1+(1-h)·T2)=1/(h+(1-h)·T2/T1)=1/(h+(1-h)·r)(4)r=5,e=1/(5-4h);r=20,e=1/(20-19h);r=100,e=1/(100-99h)。(5)由e=1/(h+(1-h)·r)=1/(h+(1-h)·100)>0.95得h>94/94.05=99.958%(6)h=0.96设缓冲深度为A,则n=5·A由h’=99.95%=(h+n-1)/n求得A=163.2由3个访问速度、存储容量和每位价格都不相同的存储器构成一个存储系统,其中M1靠近CPU。回答下列问题:M1(T1,S1,C1)M2(T2,S2,C2)M3(T3,S3,C3)(1)写出这个三级存储系统的等效访问时间T,等效存储容量S和等效每位价格C的表达式。(2)在什么条件下,整个存储系统的每位平均价格接近于C3?解:设S1C2>C3H1为在M1中访问的命中率H2为在M2中访问的命中率则(1)S=S3(利用地址映象和地址变换)T=H1·T1+(1-H1)·T23=H1·T1+(1-H1)·(H2·T2+(1-H2)·T3)当H1→1,H2→1时,T≈T1C=(C1·S1+C2·S2+C3·S3)/(S1+S2+S3)(2)当S3>>S2>>S1C=(C1·S1/S3+C2·S2/S3+C3)/(S1/S3+S2/S3+1)≈C33.6设二级虚拟存储系统的T1=10-7s,T2=10-2s,为使存储层次的访问效率e达到最大值的80%以上,命中率H至少要达到多少?实际上这样高的命中率很难达到,那么从存储层次上该如何改进?解:已知T1=0.1us,T2=10000us,e>=80%r=T2/T1=106设该存储系统的平均访问时间为T,由(4.6)得:H>=0.9999997由式(4.6)可知,要提高e,有两个途径:提高H,或者减小r。提高H的方法有:改进替换算法和调度策略,调整页面大小,提高主存容量等。减少r的方法有:采用多级存储系统,减少级间速度之比。3.3要求设计一个由Cache和主存构成的两级存储系统,已知Cache的容量有三种选择:64KB、128KB和256KB,它们的命中率分别为0.7、0.9和0.98。主存容量为4MB。设两个存储器的访问时间分别为t1和t2,每字节的价格分别为c1和c2。如果
c1=20c2时,t2=10t1。(1)在t1=20ns的条件下,分别计算三种Cache的等效访问时间。(2)如果c2=0.2美元/KB,分别计算三种Cache每字节的平均价格。(3)根据三种Cache的等效访问时间和每字节的平均价格排列次序。(4)根据等效访问时间和平均价格的乘积,选择最优的设计。解:已知c1=20c2,t2=10t1,s2=4MB,t1=20ns,C2=0.2美元/KB(1)1)h=0.7,t2=10t1=200nsTa=h×t1+(1-h)×t2=0.7×20+0.3×200=74ns2)h=0.9,t2=200nsTb=h×t1+(1-h)×t2=0.9×20+0.1×200=38ns3)h=0.98,t2=200nsTc=h×t1+(1-h)×t2=0.98×20+0.02×200=23.6ns(2)1)s1=64KB,c1=20c2=4美元/KBCa=(c1×s1+c2×s2)/(s1+s2)=(4×64+0.2×4K)/(64+4K)≈0.26美元/KB2)s1=128KB,c1=20c2=4美元/KBCb=(4×128+0.2×4K)/(128+4K)≈0.32美元/KB3)s1=256KB,c1=20c2=4美元/KBCc=(4×256+0.2×4K)/(256+4K)≈0.43美元/KB(3)Ta>Tb>TcCa>10us,说明此法不行(2)提高H。设T=10us,则H=(T-T2)/(T1-T2)=(10-1000)/(1-1000)=0.991为此,须从改进替换算法和调度策略,调整页面大小,提高主存容量等多方面综合采取措施。其中,替换算法和调度策略主要是在软件上增加代价,调整页面大小可能会增加辅助硬件的代价,而提高主存容量主要是增加硬件的代价,辅助硬件的代价也可能会略有增加。3.5由两级存储系统关于每位平均价格c及访问时间Ta之表达式进一步推广导出n级存储层次的相应表达式。解:先考虑三级存储系统。设S1C2>C3H1为在M1中访问的命中率H2为在M2中访问的命中率则(1)S=S3(利用地址映象和地址变换)T=H1·T1+(1-H1)·T23=H1·T1+(1-H1)·(H2·T2+(1-H2)·T3)当H1→1,H2→1时,T≈T1C=(C1·S1+C2·S2+C3·S3)/(S1+S2+S3)(2)当S3>>S2>>S1C=(C1·S1/S3+C2·S2/S3+C3)/(S1/S3+S2/S3+1)≈C3上述可推广至n级:存储系统的每位平均价格:存储系统的访问时间:其中,3.8在页式虚拟存储器中,一个程序由P1~P5共5个页面组成。在程序执行过程中依次访问到的页面如下:P2,P3,P2,P1,P5,P2,P4,P5,P3,P2,P5,P2
假设系统分配给这个程序的主存有3个页面,分别采用FIFO、LFU和OPT三种页面替换算法对这3页主存进行调度。(1)画出主存页面调入、替换和命中的情况表。(2)统计3种页面替换算法的页命中率。解:主存页面调入、替换和命中的情况及3种页面替换算法的页命中率如下表:页地址流P2P3P2P1P5P2P4P5P3P2P5P2命中率FIFO2222*5555*3333中30.25 3333*22222*55 111*44444*2入入中入换换换中换中换换LFU22222222*3333中50.42 333*55555555 111*444*222入入中入换中换中换换中中OPT222222*444*222中60.5 33333333333 1*55555555入入中入换中换中中换中中3.9一个程序由5个虚页组成,采用LFU替换算法,在程序执行过程中依次访问的页地址流如下:P4,P5,P3,P2,P5,P1,P3,P2,P3,P5,P1,P3(1)可能的最高页命中率是多少?(2)至少要分配给该程序多少个主存页面才能获得最高的命中率?(3)如果在程序执行过程中每访问一个页面,平均要对该页面内的存储单元访问1024次,求访问存储单元的命中率。解:(1)若分配给该程序5个页面,即程序全部装入主存,则可得到最高页命中率。需调入5次,命中7次,最高命中率为7/12≈0.58(2)至少分配4页可得到最高命中率,过程如下:P4P5P3P2P5P1P3P2P3P5P1P344444*1111111555555555553333333333命中7次222222222入入入入中换中中中中中中页地址流P4P5P3P2P5P1P3P2P2P5P1P3命中率堆S(1)栈S(2)内S(3)容S(4)S(5)4532513225134532513325145325113254432551324444444n=1n=2实n=3页数n=4n=5中中11/12中中中中22/12中中中中中中中中77/12中中中中中中中(3)命中率=7*1024/(7*1024+5)≈0.99933.10有一个Cache存储器,主存共分8个块(B0~B7),Cache为4个块(C0~C3),采用组相联映像,组内块数2块,替换算法为LFU。在程序执行过程中依次访问主存的块地址流如下:B6,B2,B4,B1,B4,B6,B3,B0,B4,B5,B7,B3(1)写出主存地址格式,并标出各字段长度。(2)写出Cache地址格式,并标出各字段长度。(3)画出主存与Cache之间各个块的映像对应关系。(4)列出程序执行过程中Cache的块地址流情况。(5)若用FIFO替换算法,计算Cache的块命中率。(6)若用LFU替换算法,计算Cache的块命中率。(7)若改用全相联映像方式,再做(5)和(6),可以得出什么结论?
(8)若在程序执行过程中,每从主存装入一块到Cache,则平均要对这个块访问16次,请计算在这种情况下的Cache命中率。解:(1)主存地址的格式(7位)B4B5B6B7C0C1C2C3B0B1B2B3Cache主存区号(1位)组号(1位)组内块号(1位)块内地址(4位)(2)Cache地址的格式(6位)组号(1位)组内块号(1位)块内地址(4位)(3)主存与Cache之间各个块的映像对应关系(4)Cache块地址流(按OPT法)C2,C3,C0,C1,C0,C2,C3,C1,C0,C1,C2,C3B6B2B4B1B4B6B3B0B4B5B7B3OPT法C2C3C0C1C0C2C3C1C0C1C2C3命中4次入入入入中中换换中换换中命中率0.333(5)FIFO法B6B2B4B1B4B6B3B0B4B5B7B3FIFO法C2C3C0C1C0C2C2C0C1C0C3C2命中3次入入入入中中换换换换换中命中率0.25(6)LFU法B6B2B4B1B4B6B3B0B4B5B7B3LFU法C2C3C0C1C0C2C2C1C0C1C3C2命中4次入入入入中中换换中换换中命中率0.333(7)全相联映像,重做(5)和(6)重做(5)B6B2B4B1B4B6B3B0B4B5B7B3FIFO法C0C1C2C3C2C0C0C1C2C2C3C0命中4次入入入入中中换换中换换中命中率0.333重做(6)B6B2B4B1B4B6B3B0B4B5B7B3LFU法C0C1C2C3C2C0C1C3C2C0C1C3命中3次入入入入中中换换中换换换命中率0.25(8)命中4次时,装入有8次,命中率为15*8+4/(16*8+4)=0.939=93.9%命中3次时,装入有9次,命中率为15*9+3/(16*9+3)=0.938=93.8%3.7一个页式虚拟存储器的虚存空间大小为4GB,页面大小为4KB,每个页表存储字长4个字节。(1)计算这个页式虚拟存储器需要采用几级页表?(2)如果要求页表所占总的主存页面数最小,请分配每一级页表的实际存储容量各为多少字节?(3)页表的哪些部分必须存放在主存中?哪些可以放在辅存中?解:依题意,已知Nv=4GB,Np=4KB,Nd=4B(1)(2)虚拟空间页面数为4GB/4KB=1M第1级页表为1页,存储容量4KB,可以有1K个存储字,指向第2级页表的1K页,每页1K个存储字,共计1M个字,4MB容量,存放1M个页面信息。(3)第1级页表必须驻留主存,第2级页表中与目前正在运行的程序的相关页表可放在主存,其余部分必须放在辅存中,因为其容量超过了1页的大小。3.11有一个Cache存储器,主存共分8个块(B0~B7),Cache为4个块(C0~C3),采用组相联映像,组内块数2块,替换算法为LRU。(1)画出主存、Cache地址的各字段对应关系(标出位数)图。
(2)画出主存与Cache之间各个块的映像对应关系。(3)在程序执行过程中依次访问主存的块地址流如下:B1,B2,B4,B1,B3,B7,B0,B1,B2,B5,B4,B6,B4,B7,B2。假定主存内容一开始未装入Cache中,请列出程序执行过程中Cache的块地址流情况。(4)对于(3),指出块失效又发生块争用的时刻。(5)对于(3),求出此期间Cache的命中率。解:(1)主存、Cache地址中各自段的含义、位数及其对应关系:主存地址的格式(7位)B4B5B6B7C0C1C2C3B0B1B2B3Cache主存区号(1位)组号(1位)组内块号(1位)块内地址(4位)组号(1位)组内块号(1位)块内地址(4位)相联查找直接Cache地址的格式(6位)(2)主存与Cache之间各个块的映像对应关系(3)Cache中各个块随时间使用的情况(LRU法,标红色为候选替换块)时间t123456789101112131415主存块地址124137012546472Cache块C0111111111144444C14444000555555C222227777776662C333332222277命中情况失失失中失换换中换换换换中换换(4)发生Cache块失效又发生块争用的时刻有:6、7、9、10、11、12、14、15(5)Cache的块命中率为H=3/15=0.24.标量处理机4.1假设指令的解释分取指、分析与执行3步,每步的时间相应为t取指、t分析、t执行,(1)分别计算下列几种情况下,执行完100条指令所需要时间的一般关系式:(i)顺序方式。(ii)仅执行k与取指k+1重叠。(iii)仅执行k、分析K+1与取指k+2重叠。(2)分别在t取指=t分析=2,t执行=1和t取指=t执行=5,t分析=2时,计算出上述各结果。解:(1)执行完100条指令所需要的时间:(i)顺序方式:100·(t取指+t分析+t执行)(ii)仅执行k与取指k+1重叠:t取指+100t分析+99·max{t取指,t执行}+t执行(iii)仅执行k、分析K+1与取指k+2重叠:t取指+max{t取指,t分析}+98·max{t取指,t分析,t执行}+max{t分析,t执行}+t执行(2)(i)当t取指=t分析=2,t执行=1时,代入上面各式,可求得100条指令执行所需的时间是:顺序方式为:100·(2+2+1)=500仅执行k与取指k+1重叠:2+100·2+99·max{2,1}+1=401仅执行k、分析K+1与取指k+2重叠:2+2+98·2+2+1=203(ii)当t取指=t执行=5,t分析=2时,代入上面各式,可求得100条指令执行所需的时间是:顺序方式为:100·(5+2+5)=1200仅执行k与取指k+1重叠:5+100·2+99·5+5=705仅执行k、分析K+1与取指k+2重叠:5+5+98·5+5+5=5104.2假设指令的解释分取指、分析与执行3段,每段的时间相应为Δt、2Δt、3Δt,在下列各情况下,分别写出连续执行n条指令所需要时间的一般关系式:(1)顺序方式。
(2)仅取指与执行重叠。(3)取指、分析与执行重叠。(4)先行控制方式。解:(1)Tk=n·6Δt(2)Tk=n·2Δt+(n-1)·3Δt+Δt+3Δt=(5n+1)Δt(3)Tk=Δt+2Δt+2Δt+3Δt+(n-1)·3Δt=(3n+3)Δt(4)采用先行控制方式,只有“分析”与“执行”两段:Tk=2Δt+3Δt+(n-1)·3Δt=(3n+2)Δt4.3在一台单流水线多操作部件的处理机上执行下面的程序,取指令、指令译码各需要1个时钟周期,MOVE、ADD和MUL操作各需要2个、3个和4个时钟周期。每个操作都在第一个时钟周期从通用寄存器中读操作数,在最后一个时钟周期把运算结果写到通用寄存器中。k:MOVER1,R0;R1←(R0)k+1:MULR0,R2,R1;R0←(R2)×(R1)k+2:ADDR0,R2,R3;R0←(R2)+(R3)(1)就程序本身而言,可能有哪几种数据相关?(2)在程序实际运行过程中,有哪几种数据相关会引起流水线停顿?(3)画出指令执行过程的流水线时空图,并计算执行完这三条指令共使用了多少个时钟周期。解:(1)就程序本身而言,存在通用寄存器数据相关:R1(k)=R1(k+1)读写R1相关R0(k+1)=R0(k+2)写R0冲突R2(k+1)=R2(k+2)读R2冲突(2)引起流水线停顿的数据相关:R1(k)=R1(k+1)(3)由时空图可知,执行完这三条指令共使用了9个时钟周期(设执行指令3和指令2译码时对R1采用先写后读)。取指令译码MOVEMULADD1231231320123456789t4.4流水线由4个功能段组成,每个功能段的延时时间都相等,为Δt。开始5个Δt,每间隔1个Δt向流水线输入一个任务,然后停顿2个Δt,如此重复。求流水线的实际吞吐率、加速比和效率。解:从输入端看,用7n个时钟周期输入3n个任务,1个周期排空。Tk=(7n+1)ΔtTP=3n/((7n+1)Δt)S=T0/Tk=12n/(7n+1)E=S/k=3n/(7n+1)4.5流水线由4个功能部件组成,每个功能部件的延时时间都为Δt。当输入10个数据后间歇5Δt又输入10个数据,如此周期性工作。求流水线的实际吞吐率,并画出时空图。解:已知k=4,n=10,按题意可画出时空图可知:Tk=15时间Tk5Δt空间S41234……910S31234……910S21234……9101S11234……91012按周期性工作的流水线平均吞吐率为:TP=10/(15Δt)=2/(3Δt)4.6用一条5个功能段的浮点加法器流水线计算每个功能段的延时时间
都相等,流水线的输出端与输入端之间有直接数据通路,而且设置足够的缓冲寄存器。要求用尽可能短的时间完成计算,求流水线的实际吞吐率、加速比和效率,并画出时空图。解:已知k=5,令B1=A1+A2,B2=A3+A4,B3=A5+A6,B4=A7+A8,B5=A9+A10C1=B1+B2,C2=B3+B4D1=C1+C2E=D1+B5可知n=9,按题意可画出时空图规格化123456789尾数加123456789对阶123456789求阶差123456789输入输出123456789A1A2A3A4A5A6A7A8A9A10B1B2B3B4C1C2B5D1时间空间得:Tk=19Δt,TP=9/(19Δt),S=45/19,E=9/194.7为提高流水线效率可用哪两种主要途径?现有3段流水线,各段经过时间依次为Δt,3Δt,Δt。(1)分别计算在连续输入3条指令时和30条指令时的吞吐率和效率。(2)按两种途径之一改进,画出你的流水线结构示意图,同时计算连续3条指令时和30条指令时的吞吐率和效率。(3)通过(1)、(2)两小题的计算比较可得出什么结论?解:(1)1)连续流入3条指令时,n=3,k=3,Δt1=Δt,Δt2=3Δt,Δt3=Δt,吞吐率为:效率为:2)连续流入30条指令时,n=30,k=3,Δt1=Δt,Δt2=3Δt,Δt3=Δt,吞吐率为:效率为:(2)改进途径1:将第二段分成3个子段,每个子段均为Δt,构成的流水线结构如下:ΔtΔtΔtΔtΔt输入输出段1段2段31)连续流入3条指令时,n=3,k=5,Δti=Δtj=Δt,吞吐率为:效率为:2)连续流入30条指令时,n=30,k=5,Δti=Δtj=Δt,吞吐率为:效率为:改进途径2:将3个段2并联构成的流水线结构如下:段1输入Δt段3输出ΔtΔtΔtΔt段2
连续流入3条指令与连续流入30条指令时的吞吐率和效率分别与(1)中子过程细分相同。(3)将(1)中n=3和n=30的计算结果进行比较可看出,只有当连续流入流水线的指令越多时,流水线的实际吞吐率和效率才会提高。将(1)、(2)题的计算结果进行比较,同样可看出,两种消除流水线瓶颈的方法,都只有当连续流入流水线的指令越多时,流水线的实际吞吐率和效率才会明显提高。若流入的指令数太少,消除流水线瓶颈虽可以提高吞吐率,而效率却可能下降。5.向量处理机5.3在CRAY1机上,按链接方式执行下述4条向量指令。所用向量功能执行部件的执行时间分别为:向量加需3拍,向量逻辑乘需2拍,从存储器读数需7拍,按A3左移需4拍,打入寄存器及启动功能部件(包括存储器)各需1拍。试求此链接流水线的流过时间为多少拍?若向量长度为64,计算出全部完成所需拍数。V0←存储器V2←V0+V1V3←V2
您可能关注的文档
- 幼儿科学在线作业答案.doc
- 广东专插本《管理学》真题及答案(2001-2011).doc
- 广东农信网络学院柜员综合测试考试练习题答案汇总(可搜索查询答案版)doc.doc
- 广东海洋大学往年(2007—2013)《高等数学》期末考试试题10套集锦(含A,B卷与答案,完整版).pdf
- 广东省新版《初级会计电算化》考试理论复习题集含答案.doc
- 广州医学院《推拿手法功法学》题库与答案.doc
- 广州大学考研复习资料《心理学概论》 实用练习题.pdf
- 广西2016年专业技术人员继续教育公需科目《专业技术人员创新与创业能力建设》考试题目与答案.doc
- 广西《生态文明与可持续发展》公需科目考题及答案库.doc
- 应用文写作习题及答案.doc
- 作教材_第2版_习题答案.pdf
- 应用概率统计课后习题答案详解.doc
- 应用物理化学习题解答.doc
- 应用经济学专业《微观经济学》练习册参考答案.docx
- 应用经济学课后习题答案.doc
- 应用统计学课后习题答案.doc
- 底盘习题答案.doc
- 庞浩版计量经济学课后习题答案.doc
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明
-
 关注微信公众号售出明细实时看
关注微信公众号售出明细实时看