

- 709.47 KB
- 2022-04-22 13:44:37 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
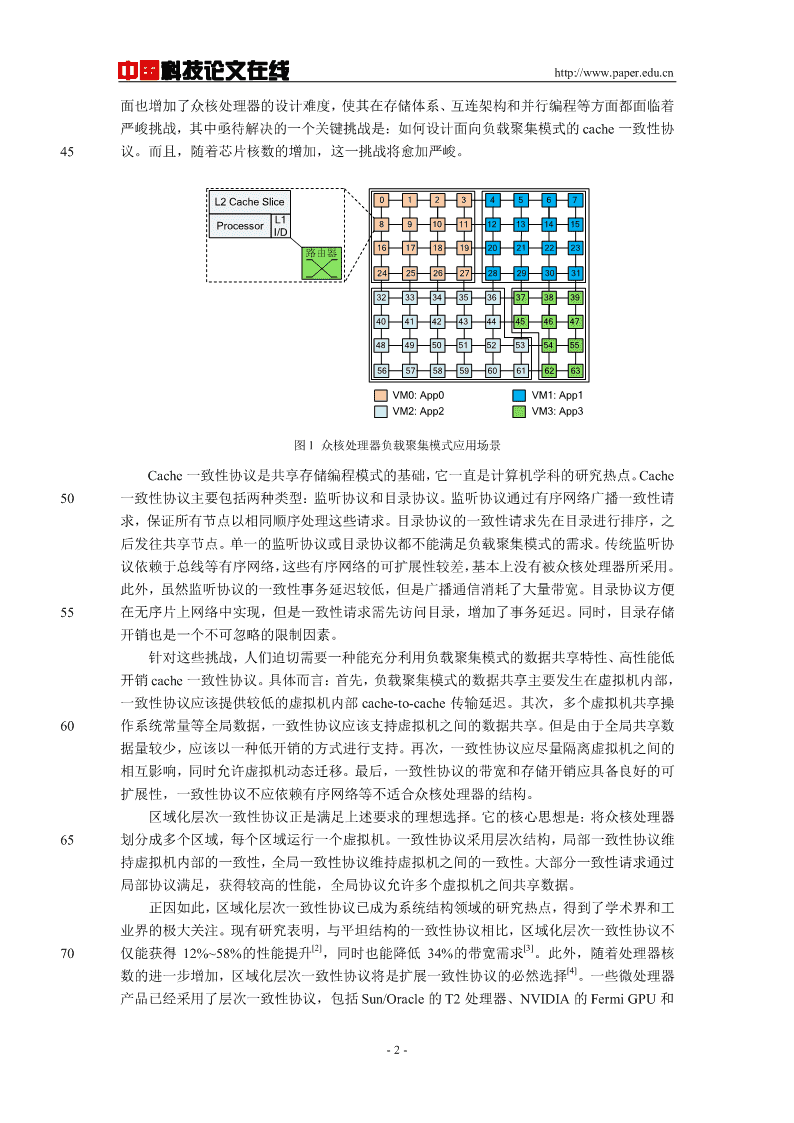
'中国科技论文在线http://www.paper.edu.cn面向众核负载聚集模式的Cache一致性协#议研究综述*马胜,王志英5(国防科技大学计算机学院)摘要:负载聚集模式给众核处理器结构,尤其是cache一致性协议的设计,带来了诸多挑战。高效一致性协议必须充分利用负载聚集模式的数据共享特性,在虚拟机内部提供低延迟的数据共享,在虚拟机之间提供低开销的数据共享,同时还应支持虚拟机动态迁移和区域隔离。针对上述需求,本综述深入分析负载聚集模式对处理器设计的影响,尤其关注对cache一致10性协议设计的影响。面向负载聚集模式的cache一致性协议需要与片上网络协同设计,因此,本文针对现有cache一致性协议与片上网络协同设计的研究成果进行了回顾。在上述分析的基础上,本文对未来设计面向负载聚集模式cache一致性协议的研究方向进行了展望,指出了研究动态区域层次化一致性协议是有效满足负载聚集模式cache一致性协议需求的有效途径。15关键词:Cache一致性协议负载聚集片上网络中图分类号:TP338ASurveyofResearchonCacheCoherenceProtocolsforWorkloadConsolidation20MASheng,WANGZhiying(SchoolofComputer,NationalUniversityofDefenseTechnology)Abstract:WorkloadConsolidationbringsseveralchallengestothedesignofmany-corearchitecture,especiallythecachecoherenceprotocol.Anefficientcoherenceprotocolmusttakefulladvantageofthedatasharingcharacteristicsofworkloadconsolidation;itmustprovideslowlatencydatasharing25withinavirtualmachine(VM),andsupportslowcostdatasharingbetweenseveralVMs.Besides,thecoherenceprotocolshouldallowtheVMmigrationandprovideregionisolation.Toaddresstheseissues,thissurveythoroughlyanalyzestherequirementsofdesigningcachecoherenceprotocolsforworkloadconsolidation.Thecoherenceprotocolsforworkloadconsolidationshouldbeco-designedwiththeNetworks-on-Chip(NoCs).Thus,wereviewtheresearchontheco-designofcachecoherence30protocolsandNoCs.Basedontheseanalysis,weprospectthefutureofdesigningcachecoherenceprotocolsforworkloadconsolidation,andsuggestthatthehierarchicalcoherenceprotocolwithdynamicregionshaspotentialtomeettherequirements.Keywords:Cachecoherentprotocol,WorkloadConsolidation,Networks-on-Chip350引言体系结构界已进入了众核处理器时代,相应的软件应用场景出现了新的变化。单个程序受限于自身有限的并行性,难以完全使用众核处理器数十甚至上百个计算核。比如,当PARSEC测试集使用的核数小于16个时,程序的性能随着核数的增加而上升,但是进一步[1]40增加核数带来的同步开销剧增反而导致程序性能出现下降。如图1所示,一种常见现象将是多个程序同时运行在一个众核平台上,这种负载聚集模式已成为众核处理器的重要应用场景。负载聚集模式一方面给众核处理器的性能提升和应用领域扩展带来了许多机遇,另一方基金项目:教育部博士点基金项目(20134307120028)作者简介:马胜(1986年-),男,助理研究员,主要研究计算机体系结构.E-mail:masheng@nudt.edu.cnmasheng@nudt.edu.cn-1-
中国科技论文在线http://www.paper.edu.cn面也增加了众核处理器的设计难度,使其在存储体系、互连架构和并行编程等方面都面临着严峻挑战,其中亟待解决的一个关键挑战是:如何设计面向负载聚集模式的cache一致性协45议。而且,随着芯片核数的增加,这一挑战将愈加严峻。L2CacheSlice01234567L1Processor89101112131415I/D1617181920212223路由器24252627282930313233343536373839404142434445464748495051525354555657585960616263VM0:App0VM1:App1VM2:App2VM3:App3图1众核处理器负载聚集模式应用场景Cache一致性协议是共享存储编程模式的基础,它一直是计算机学科的研究热点。Cache50一致性协议主要包括两种类型:监听协议和目录协议。监听协议通过有序网络广播一致性请求,保证所有节点以相同顺序处理这些请求。目录协议的一致性请求先在目录进行排序,之后发往共享节点。单一的监听协议或目录协议都不能满足负载聚集模式的需求。传统监听协议依赖于总线等有序网络,这些有序网络的可扩展性较差,基本上没有被众核处理器所采用。此外,虽然监听协议的一致性事务延迟较低,但是广播通信消耗了大量带宽。目录协议方便55在无序片上网络中实现,但是一致性请求需先访问目录,增加了事务延迟。同时,目录存储开销也是一个不可忽略的限制因素。针对这些挑战,人们迫切需要一种能充分利用负载聚集模式的数据共享特性、高性能低开销cache一致性协议。具体而言:首先,负载聚集模式的数据共享主要发生在虚拟机内部,一致性协议应该提供较低的虚拟机内部cache-to-cache传输延迟。其次,多个虚拟机共享操60作系统常量等全局数据,一致性协议应该支持虚拟机之间的数据共享。但是由于全局共享数据量较少,应该以一种低开销的方式进行支持。再次,一致性协议应尽量隔离虚拟机之间的相互影响,同时允许虚拟机动态迁移。最后,一致性协议的带宽和存储开销应具备良好的可扩展性,一致性协议不应依赖有序网络等不适合众核处理器的结构。区域化层次一致性协议正是满足上述要求的理想选择。它的核心思想是:将众核处理器65划分成多个区域,每个区域运行一个虚拟机。一致性协议采用层次结构,局部一致性协议维持虚拟机内部的一致性,全局一致性协议维持虚拟机之间的一致性。大部分一致性请求通过局部协议满足,获得较高的性能,全局协议允许多个虚拟机之间共享数据。正因如此,区域化层次一致性协议已成为系统结构领域的研究热点,得到了学术界和工业界的极大关注。现有研究表明,与平坦结构的一致性协议相比,区域化层次一致性协议不[2][3]70仅能获得12%~58%的性能提升,同时也能降低34%的带宽需求。此外,随着处理器核[4]数的进一步增加,区域化层次一致性协议将是扩展一致性协议的必然选择。一些微处理器产品已经采用了层次一致性协议,包括Sun/Oracle的T2处理器、NVIDIA的FermiGPU和-2-
中国科技论文在线http://www.paper.edu.cnAMD的Bulldozer处理器。但是现有大部分研究只关注上层一致性协议的实现,忽略了底层片上网络的特性,这种75现象造成现有设计存在较大缺陷。首先,没有在虚拟机内部提供低延迟的数据共享。由于在无序片上网络中实现监听协议较复杂,现有设计大都在虚拟机内部使用目录协议,导致虚拟机内部数据共享的延迟较高,恶化了性能。比如,Daya等人在ISCA2014会议发布的36核[5]芯片的评估结果表明,目录协议的性能比无序网络中监听协议的性能低24.1%。其次,消耗了大量网络带宽。由于数据共享大部分发生在少数节点间,监听协议的大量广播请求被发80送到非共享节点上,不必要地消耗了带宽。粗粒度位向量目录结构能降低存储开销,但是引入了冗余的作废消息,消耗了额外的带宽。最后,忽略了片上网络优化对一致性协议的影响。比如,片上网络中硬件支持聚合通信能有效缓解一致性协议聚合通信的性能瓶颈。又如,片上网络的区域隔离机制是一致性区域性能隔离的基础。以上这些缺陷都严重制约了区域化层次一致性协议的效果及其在众核处理器中的实际应用。85众核处理器存储系统和互连系统之间的紧密耦合要求设计高效的区域化层次一致性协议必须仔细考虑cache一致性协议和片上网络之间的相互作用。同时,片上网络的研究进展也为层次一致性协议的优化提供了许多新的机会。本综述将深入分析负载聚集模式对处理器设计的影响,尤其关注对cache一致性协议设计的影响。面向负载聚集模式的cache一致性协议需要与片上网络协同设计,因此,本文针对现有cache一致性协议与片上网络协同设计90的研究成果进行了回顾。在上述分析的基础上,本文对未来设计面向负载聚集模式cache一致性协议的研究方向进行了展望,指出了研究动态区域层次化一致性协议是有效满足负载聚集模式cache一致性协议需求的有效途径。1面向负载聚集模式的Cache一致性协议研究进展负载聚集模式已成为众核处理器的重要应用场景,本节我们首先回顾负载聚集模式对处95理器结构的影响,尤其关注cache一致性协议的设计。Cache一致性协议与片上互连机制紧密相关,接下来我们分析cache一致性协议与片上网络协同设计的研究现状。1.1负载聚集模式对处理器设计的影响EnrightJerger等人基于商业应用测试集评估了图2所示的负载聚集模式对多核处理器设计的影响,他们考虑两种应用程序分配策略round-robin和affinity,其中round-robin在多个100处理核上轮转分配应用程序的线程,affinity尽量将同一个应用程序的线程分配在相邻的处理核上,他们的研究发现共享cache的访问调度策略对负载聚集模式的程序性能影响很大,[6]调度策略必须考虑多个程序之间的公平性和隔离性。-3-
中国科技论文在线http://www.paper.edu.cn105图2负载聚集模式下两种应用程序线程分配模式西蒙弗雷泽大学的Zhuravlev等人研究了能有效感知资源冲突的共享cache访问调度策略。他们指出,在负载聚集模式下,资源冲突造成的性能下降比cache容量不足造成的性能下降更为严重,这些资源冲突包括由cache缺失造成的访问存储控制器和存储总线的冲突。为此,他们提出将cache缺失均匀分布到所有cache体上的调度策略,显著提升了服务质量,[7]110为单个程序的性能提供了一定的隔离性。Mutlu和Moscibroda研究了负载聚集模式下的存储控制器调度策略的设计,他们提出能有效感知DRAM多个体之间访问并行性的批量调度器,通过批处理调度访存请求,在一个DRAM存储体内并行处理单个线程的请求,减少访存带来的停顿,不仅提升了性能,也提[8]高了程序之间的公平性。之后,Mutlu的小组针对多个程序访问存储控制器的冲突和干扰[9,10,11]115做了大量研究工作,包括控制访存冲突造成的延迟、通过任务映射降低访存冲突等。负载聚集模式下的cache一致性协议设计是近期研究热点。Marty和Hill认为负载聚集模式下的一致性协议应达到如下目标:以最优的方式支持虚拟机内部的数据共享;尽量减少虚拟机之间的干扰;支持虚拟机动态迁移;允许多虚拟机基于内容共享存储页面。他们提出[2]了虚拟层次一致性协议,由虚拟机内部的协议和虚拟机之间的协议组成。但是如图3所示,120该研究存在较大缺陷,他们在虚拟机内部采用目录协议,在虚拟机之间采用广播协议,不仅导致虚拟机内部的大量一致性事务的延迟过高,同时还造成虚拟机之间的一致性事务消耗了大量带宽。我们认为高效的动态区域化层次一致性协议与该设计正好相反,需要在虚拟机内部研究监听协议以降低事务延迟,在虚拟机之间研究目录协议以降低带宽开销。125(a)虚拟机内部采用目录协议(b)虚拟机之间采用广播协议[2]图3层次一致性协议-4-
中国科技论文在线http://www.paper.edu.cn清华大学的郭松柳等人针对传统目录一致性协议在众核处理器中延迟过高和存储开销过大的问题,提出了一种层次目录一致性协议。为优化一致性事务延迟,他们允许在共享[3]cache中存在多份数据拷贝。南京大学的Zhang等人也研究了层次目录一致性协议,他们130将整个芯片划分成多个集群,每个集群设置一个主节点,高层一致性协议维持集群内部的一[12]致性,底层一致性协议通过主节点维持集群之间的一致性。这两种设计能在一定程度上满足负载聚集模式的需求,但是它们不能支持虚拟机动态迁移,同时由于上层采用目录协议,虚拟机内部的一致性事务的延迟过高。当前也有部分层次一致性协议的上层结构采用监听协议,包括宾夕法尼亚州立大学Das[13]135等人提出的基于总线和网格型网络的混合结构和国防科技大学黄立波等人提出的基于扩[14]展行列总线的协议。但是如图4所描述,这些设计的监听协议都依赖结构固定的总线,不能适应虚拟机动态迁移,同时也不方便隔离虚拟机。与这些实现不同,我们将研究不依赖总线而直接在无序片上网络中实现监听协议,它能够较好地支持虚拟机动态迁移和虚拟机之间的隔离。140图4依赖于固定总线结构的层次一致性协议层次一致性协议结构除了能较好地满足负载聚集模式的需求外,它还是未来一致性协议向百核处理器乃至千核处理器扩展的基础。宾夕法尼亚大学的Martin等人指出由于兼容历145史遗留代码的需求,cache一致性协议必将在众核处理器中长期存在,但是解决目录一致性[4]协议存储开销和带宽开销剧增的问题必须采用层次一致性协议。1.2一致性协议与片上网络的协同设计Cache一致性协议的设计与片上互连机制密切相关,协同设计cache一致性协议与片上网络已成为重要研究领域。Chen等人针对不同一致性消息对带宽和延迟敏感程度的不同,150设置具有不同带宽和延迟属性的连线,通过将消息映射到最合适的连线上,降低了一致性协议的功耗,也提升了性能。但是他们在分析消息属性时,只考虑了协议跳数,没有考虑网络[15]跳数,导致设计只适合点到点互连,不适合网格型网络。Muralimanohar等人将上述思想扩展到大规模NUCA结构中,他们观察到在访问cache的过程中,地址只有低位部分处于关键路径上,而高位部分只在进行tag匹配时才使用,因此,他们使用低延迟连线传输地址[16]155低位部分,使用高带宽连线传输地址高位部分。Eisley等人为降低目录一致性协议的事务延迟,提出将目录信息通过虚拟树的方式保存-5-
中国科技论文在线http://www.paper.edu.cn在片上网络路由器中,提出了网络中一致性协议(In-networkcoherence)。如图5所示,当一致性请求传输时,如果通过虚拟树发现附近节点能满足请求,就不需访问目录节点(图5b),与图5a中的传统目录协议相比,它们的设计能降低了一致性请求的传输跳数。他们[17]160的设计需要考虑虚拟树作废时的系统一致性以及虚拟树替换对系统性能的影响。(a)传统目录协议(b)网络中一致性协议图5网络中一致性协议与传统目录协议的比较威斯康辛麦迪逊分校的EnrightJerger等人提出了虚拟树一致性协议,每个cache行的共165享节点通过虚拟树在片上网络中连接起来,虚拟树的根节点对一致性消息进行排序。Cache行的写缺失请求首先发送到虚拟树的根节点,之后沿着虚拟树将所有共享节点作废。Cache行的读缺失请求可以通过虚拟树上的最近节点得到满足。为减少存储开销,虚拟树为粗粒度[18]存储区域维持共享信息。中科院计算所的Zeng等人基于消息的网络跳数改进经典MESI目录协议,主要关注read170和read-exclusive事务,如果有距离请求节点更近的共享节点或exclusive节点能提供所请求[19]的cache行,则由这个节点而不是目录节点提供cache行,优化了事务延迟。清华大学的王惊雷等人将实现一致性协议的存储单元从一级cache和二级cache移至网络接口,降低了内核的设计难度,减少了二级cachetag体的访问冲突。此外,由于网络接口只为当前处于[20]活跃状态的二级cache保存目录信息,这种设计也减少了目录存储开销。175上述设计主要优化目录一致性协议的事务延迟和存储开销。传统监听协议依赖于总线等有序网络,但是众核处理器主要采用网格型网络等无序片上网络。为了在众核处理器中利用监听协议的低延迟特性,必须解决在无序网络中实现监听协议这个至关重要又极具挑战性的问题。Martin等人提出时间戳监听协议,他们为每个请求分配一个逻辑时间戳,目的节点根据逻辑时间戳按序处理请求。目的节点使用一个较大的缓冲存储具有特定排序时间的请求报[21]180文,缓冲容量与处理器核数和每个核的最多同时请求数成线性关系。令牌一致性协议支持在无序网络上实现监听协议,设计包括正确性层和性能层,正确性层通过令牌计数和持久请求保证协议的正确性,性能层通过瞬态请求降低一致性事务延迟。持久请求可能会导致系[22]统性能不稳定等问题。Marty和Hill将令牌计数的思想扩展到环网上,他们的设计避免了全局排序点,一致性[23]185请求在环网传输时完成排序。Strauss等人也研究了环网上的排序问题,他们观察到多个节点以相同顺序处理监听请求的关键是监听回复消息的传输,而不是监听请求消息的传输,因此他们提出只将监听回复消息沿着环网传输,而监听请求消息可以任意传输。这种设计提[24]升了load操作的性能,但是不能提升store操作的性能。麻省理工学院Peh的小组长期研究在无序网络中实现监听协议,他们首先采用分布式策-6-
中国科技论文在线http://www.paper.edu.cn190略在路由器上实现对监听请求的偏序支持,之后在网络接口维持监听请求的全序关系。在一[25]个64核平台上,他们的设计能获得比目录协议高30%的性能。最近Peh的小组在ISCA[1]2014国际会议上展示了一款在无序网络中实现监听协议的36核原型芯片(图6)。核心思想是将监听请求的传输与监听请求的排序解耦,监听请求通过一个无序网络广播,而监听请求的排序使用一个无冲突的辅助网络。系统采用时间窗机制,只允许在时间窗开始时注入195请求。由于辅助网络是无冲突的,在每个时间窗结束时,所有节点都能接收到相同的辅助消息,从而知道本时间窗内有哪些节点发出了请求,进而完成请求的排序。他们的设计能获得比目录协议高24.1%的性能。图6MIT的36核无序网络监听协议验证芯片200除了利用片上网络的特性改进cache一致性协议的设计外,另外一种思路是保持一致性协议不变,通过优化片上网络的设计提升一致性协议的性能。Bolotin等人在片上网络中优[26]先传输短控制报文以加速一致性事务的执行;Volos等人使用异构网络分别处理短报文和[27]长报文提高一致性协议的能耗效率。清华大学的Li等人提出了一种能有效感知报文关键[28]性的设计,他们允许关键报文复用交叉开关分配结果,加速关键报文的传输。国防科技[29,30]205大徐的项目组之前对一致性通信的大量短报文提出了支持较高吞吐率的流控机制。Cache一致性协议需要使用多播、广播和归约通信等聚合通信,在片上网络中对这些聚合通信提供硬件支持能提升一致性协议的性能。基于路径的多播路由带来了额外的路径建立[31]和确认延迟。VCTM设计通过虚拟多播树进行报文传输,在多播报文的目标集合重复率[32]较低时,多播树的建立延迟会显著降低性能。RPM在报文传输过程中建立多播树,延迟[33]210较低,但使用两个虚拟网络分别传输向上和向下的报文,降低了缓存利用率;浙江大学[34]的王小航等人将RPM扩展到多区域设计。bLBDR使用小区域内部的广播实现多播操作,[35][36]引入了冗余报文。MRR是一种基于旋转路由器的多播路由算法。在归约通信的支持方面,Krishna等人提出在片上网络中对归约ACK消息进行组合,该设计将先到达的ACK消息保存在虚通道内等待后到达的ACK消息,设计需配置12条虚通道才能获得性能提升。[37]215大量虚通道降低了路由器的频率,给性能带来了负面影响。区域化层次一致性协议需要片上网络提供区域隔离机制,但是目前业界对片上网络的区域隔离机制研究较少。Trivino等人将网络划分成多个区域,每个区域运行一个程序,通过[1,38]限制报文只使用区域内部的链路隔离多个程序。他们的设计静态配置区域范围,无法适应虚拟机动态迁移。中科院计算所的Lu等人认为适当放宽隔离要求可简化设计并提升性能,[39]220为此他们提出“松弛隔离”模型,根据路由算法的设计允许部分资源被多个程序共享。-7-
中国科技论文在线http://www.paper.edu.cn[40]Tile64处理器采用了Hardwall隔离机制,当报文需使用区域边界链路时,Hardwall要么丢弃报文,要么存储报文等待后续发送。2展望综上所述,不难得出如下结论:225首先,现有研究表明负载聚集模式给包括cache一致性协议在内的处理器设计带来了许多新的挑战,但是这些挑战还远未得到解决。比如,现有的层次一致性协议大都使用目录协议,导致虚拟机内部的一致性事务延迟过高。又如,部分设计的层次结构是固定的,无法满足虚拟机动态迁移的需求。其次,对cache一致性协议和片上网络进行协同设计能获显著提升性能并降低硬件开销,230但是现有研究基本只考虑平坦结构的一致性协议,没有考虑对区域化层次一致性协议的协同设计。最后,cache一致性协议和片上网络协同设计尚存在很多缺陷。比如,现有的无序网络中监听协议的设计没有考虑广播通信的巨大带宽开销。又如,片上网络对聚合通信的支持或存在较大的硬件开销,或严重影响频率。235总而言之,负载聚集模式对cache一致性协议提出了许多新的挑战,协同设计一致性协议和片上网络是一种能较好地解决上述挑战的途径。现有研究在延迟、开销和支持虚拟机动态迁移及区域隔离等方面还存在很多问题亟待解决,只有较好地解决了这些问题,才能充分满足负载聚集模式的需求,高效地利用众核处理器提供的丰富计算资源!240[参考文献](References)[1]F.Trivino,etal.VirtualizingNoCresourcesinchip-multiprocessors,MicroprocessorsandMicrosystems,35(2),2013.[2]M.Marty,M.Hill.VirtualHierarchiestoSupportServerConsolidation.InISCA2007.[3]S.Guo,H.Wang,Y.Xue,etal.HierarchicalCacheDirectoryforCMP.JournalofComputerScienceand245Technology,25(2):246-256.March2010.[4]M.Martin,M.Hill,D.Sorin.WhyOn-ChipCacheCoherenceIsHeretoStay.CommunicationsoftheACM,55(7):78-89.July2012.[5]N.Agarwal,L.Peh,N.Jha.In-NetworkSnoopOrdering(INSO):SnoopyCoherenceonUnorderedInterconnects.InHPCA2010.250[6]N.EnrightJerger,D.Vantrease,M.Lipasti.AnEvaluationofServerConsolidationWorkloads.InIISWC2007.[7]S.Zhuravlev,S.Blagodurov,A.Fedorova.Addressingsharedresourcecontentioninmulticoreprocessorsviascheduling.InASPLOS2010.[8]O.Mutlu,T.Moscibroda.Parallelism-AwareBatchScheduling:EnhancingbothPerformanceandFairnessofSharedDRAMSystems.InISCA2009.255[9]O.Mutlu.MemoryScaling:ASystemsArchitecturePerspective.InIMW2014.[10]H.Kim,D.deNiz,B.Andersson,etal.BoundingMemoryInterferenceDelayinCOTS-basedMulti-CoreSystems.TechnicalReportCMU/SEI-2014-TR-003,CarnegieMellonUniversity,2014.[11]R.Das,R.Ausavarungnirun,O.Mutlu,etal.Application-to-coremappingpoliciestoreducememorysysteminterferenceinmulti-coresystems.InHPCA2014.260[12]Y.Zhang,Z.Lu,A.Jantsch,etal.TowardsHierarchicalClusterbasedCacheCoherenceforLarge-ScaleNetwork-on-Chip.InDTIS2009.[13]R.Das,S.Eachempati,A.Mishra,etal.DesignandEvaluationofaHierarchicalOn-ChipInterconnectforNext-GenerationCMPs.InHPCA2010.[14]L.Huang,Z.Wang,N.Xiao.AnOptimizedMulticoreCacheCoherenceDesignforExploiting265CommunicationLocality.InGLVLSI2012.[15]L.Cheng,N.Muralimanohar,K.Ramani,etal.Interconnect-AwareCoherenceProtocolsforChipMultiprocessors.InISCA2007.[16]N.Muralimanohar,R.Balasubramonian.InterconnectDesignConsiderationsforLargeNUCACaches.InISCA2008.-8-
中国科技论文在线http://www.paper.edu.cn270[17]N.Eisley,L.Peh,L.Shang.In-NetworkCacheCoherence.InMICRO2007.[18]N.EnrightJerger,L.Peh,M.Lipasti.VirtualTreeCoherence:LeveragingRegionsandIn-NetworkMulticastTreesforScalableCacheCoherence.InMICRO2009.[19]H.Zeng,J.Wang,G.Zhang,etal.AnInterconnect-AwarePowerEfficientCacheCoherenceProtocolforCMPs.InIPDPS2011.275[20]J.Wang,Y.Xue,H.Wang,etal.CCNoC:Cache-coherentnetworkonchipforchipmultiprocessors.JournalofComputerScienceandTechnology,25(2):257-266,March2010.[21]M.Martin,D.Sorin,A.Ailamaki,etal.TimestampSnooping:AnApproachforExtendingSMPs.InASPLOS2000.[22]M.Martin,M.Hill,D.Wood.TokenCoherence:DecouplingPerformanceandCorrectness.InISCA2003.280[23]M.Marty,M.Hill.CoherenceOrderingforRing-basedChipMultiprocessors.InMICRO2006.[24]K.Strauss,X.Shen,J.Torrellas.Uncorq:UnconstrainedSnoopRequestDeliveryinEmbedded-RingMultiprocessors.InMICRO2007.[25]B.Daya,C.Chen,S.Subramanian,etal.SCORPIO:A36-CoreResearchChipDemonstratingSnoopyCoherenceonaScalableMeshNoCwithIn-NetworkOrdering.InISCA2014.285[26]E.Bolotin,Z.Guz,I.Cidon,etal.ThePowerofPriority:NoCbasedDistributedCacheCoherency.InNOCS2010.[27]S.Volos,C.Seiculescu,B.Grot,etal.CCNoC:SpecializingOn-ChipInterconnectsforEnergyEfficiencyinCache-CoherentServers.InNOCS2013.[28]Z.Li,J.Wu,L.Shang,etal.Latencycriticalityawareon-chipcommunication.InDATE2009.290[29]S.Ma,Z.Wang,N.EnrightJerger,etal.Novelflowcontrolforfullyadaptiveroutingincache-coherentNoCs.IEEETransactionsonParallelandDistributedSystems,25(9):2397-2407,September2014.[30]S.Ma,Z.Wang,Z.Liu,etal.Leavingoneslotempty:Flitbubbleflowcontrolfortoruscache-coherentNoCs.IEEETransactionsonComputers,64(3):763-777,2015.[31]Z.Lu,B.Yin,A.Jantsch.Connection-orientedmulticastinginwormhole-switchednetworksonchip.In295ISVLSI2006.[32]N.EnrightJerger,L.Peh,M.Lipasti.VirtualCircuitTreeMulticasting:ACaseforOn-ChipHardwareMulticastSupport.InISCA2008.[33]L.Wang,etal.RecursivePartitioningMulticast:Abandwidth-efficientroutingforNetworks-on-Chip.InNOCS2009.300[34]X.Wang,etal.OnanefficientNoCmulticastingschemeinsupportofmultipleapplicationsrunningonirregularsub-networks.MicroprocessorsandMicrosystems,35(2):119-129,2011.[35]S.Rodrigo,etal.EfficientunicastandmulticastsupportforCMPs.InMICRO2008.[36]P.Abad,V.Puente,J.Gregorio.MRR:EnablingfullyadaptivemulticastroutingforCMPinterconnectionnetworks.InHPCA2009.305[37]T.Krishna,etal.TowardstheIdealOn-chipFabricfor1-to-ManyandMany-to-1Communication.InMICRO2013.[38]F.Trivino,etal.Network-on-ChipvirtualizationinChip-MultiprocessorSystems.JournalofSystemsArchitecture,2014.[39]H.Lu,etal.RISO:relaxednetwork-on-chipisolationforcloudprocessors.InDAC2013.310[40]D.Wentzlaff,etal.On-ChipInterconnectionArchitectureoftheTileProcessor.IEEEMicro,27(5):15-31,2007.-9-'
您可能关注的文档
- 表面改性强化微粉煤脱硫试验研究.pdf
- 论公共服务供给侧改革的价值目标.pdf
- 论实验动物腧穴的发展阶段.pdf
- 轴向并联式轴向磁场磁通切换混合永磁记忆电机的电磁特性研究.pdf
- 金属纳米圆盘-纳米球间隙模式表面等离激元共振特性研究.pdf
- 钴镍氢氧化物的制备及其电催化析氧性能研究.pdf
- 银包金等离子体纳米棒对激射性能的提高.pdf
- 阿霉素涂层输尿管支架的制备及药物释放行为的研究.pdf
- 零件加工一致性评价技术.pdf
- 预补偿型反向训练模式下的01式跳空技术.pdf
- 高分辨率透射电镜碳烟图像量化分析方法研究.pdf
- 高压缩比天然气发动机爆震模拟及燃烧室优化.pdf
- 黄淮海平原区夏玉米倒伏特点及化控抗倒技术研究进展.pdf
- 黄芪甲苷对高胰岛素环境下肾小球系膜细胞的保护作用及其机制.pdf
- 黄连素激活TGR5、调节S1P2MAPK信号通路,抵抗高糖诱导的GMC中炎症纤维化成分的表达.pdf
- 黑加仑采收机的设计与试验.pdf
- 黑龙江省农机合作社发展现状分析.pdf
- 鼎湖鳞伞菌丝体粗多糖的流变学特性研究.pdf
相关文档
- 施工规范CECS140-2002给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程
- 施工规范CECS141-2002给水排水工程埋地钢管管道结构设计规程
- 施工规范CECS142-2002给水排水工程埋地铸铁管管道结构设计规程
- 施工规范CECS143-2002给水排水工程埋地预制混凝土圆形管管道结构设计规程
- 施工规范CECS145-2002给水排水工程埋地矩形管管道结构设计规程
- 施工规范CECS190-2005给水排水工程埋地玻璃纤维增强塑料夹砂管管道结构设计规程
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程(含条文说明)
- cecs 141:2002 给水排水工程埋地钢管管道结构设计规程 条文说明
- cecs 140:2002 给水排水工程埋地管芯缠丝预应力混凝土管和预应力钢筒混凝土管管道结构设计规程 条文说明
- cecs 142:2002 给水排水工程埋地铸铁管管道结构设计规程 条文说明